# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
全世界高质量数据几乎枯竭。
AI科学家们为了解决这一难题,可谓是绞尽脑汁。
目前来看,合成数据或许就是大模型的未来,也成为业界公认的解决之法。
就连英伟达科学家Jim Fan曾发文表示,合成数据将提供下一万亿个高质量的训练token。

但是,用合成数据,并非完全对LLM训练有帮助。
前段时间,Nature封面研究显示,合成数据迭代9次后,会让大模型崩溃。而且,类似的研究比比皆是。
那么,我们该怎么办呢?
最近,微软团队提出了可扩展的智能体框架——AgentInstruct,可自动创建大量多样化、高质量的合成数据。
它最大的优势在于,仅只用原始数据源,就能创建完整的提示和回应。

论文地址:https://arxiv.org/pdf/2407.03502
对此,研究人员使用AgentInstruct,创建了2500万对「后训练」数据集,涵盖了多种使用技能,如文本编辑、创意写作、工具使用、编码、阅读理解等。
然后,他们利用这些数据对Mistral-7b进行后训练,得到了Orca-3模型。
与原始的Mistral-7b-Instruct相比,Orca-3在多个基准测试中,都显示出显著的性能提升。

而在数学方面上的表现,性能直接暴涨168%。

当「合成数据」遇上智能体
过去一年,我们见证了智能体的兴起。
智能体可以生成高质量的数据,通过反思和迭代,其能力反超了底层基础大模型。
在这个过程中,智能体可以回顾解决方案,自我批评,并改进解决方案。它们甚至可以利用工具,如搜索API、计算器、代码解释,来扩展大模型的能力。

此外,多智能体还可以带来更多的优势,比如模拟场景,同时生成新的提示和响应。
它们还可以实现数据生成工作流的自动化,减少或消除某些任务对人工干预的需求。
论文中,作者提出了「生成式教学」的概念。
这是说,使用合成数据进行后训练,特别是通过强大的模型创建数据,来教另一个模型新技能或行为。
AgentInstruct是生成式教学的一个智能体解决方案。
总而言之,AgentInstruct可以创建:
- 高质量数据:使用强大的模型如GPT-4,结合搜索和代码解释器等工具。
- 多样化数据:AgentInstruct同时生成提示和回应。它使用多智能体(配备强大的LLM、工具和反思流程)和一个包含100多个子类别的分类法,来创建多样化和高质量的提示和回应。
- 大量数据:AgentInstruct可以自主运行,并可以应用验证和数据过滤的流程。它不需要种子提示,而是使用原始文档作为种子。

生成式教学:AgentInstruct
我们如何创建海量数据?如何保证生成的数据具有多样性?如何生成复杂或微妙的数据?
为此,研究人员概述了解决这些挑战的结构化方法:

具体来说,AgentInstruct定义了三种不同的自动化生成流程:
内容转换流程:将原始种子转换为中间表示,简化了针对特定目标创建指令的过程。
种子指令生成流程:由多个智能体组成,以内容转换流程的转换后种子为输入,生成一组多样化的指令。
指令改进流程:以种子指令流程的指令为输入,迭代地提升其复杂性和质量。

接下来,研究人员为为17种不同的技能实现了这些流程,每种技能都有多个子类别。
这些技能包括阅读理解、问答、编码、检索增强生成、创意写作、工具/API使用和网络控制。
完整列表,如下表1中所示。

接下来,研究人员通过以下三种技能的案例研究,来解释这些工作流是如何运作的。



实验结果
正如开头所述,研究人员使用2580万对指令,微调Mistral-7b-v0.1模型,然后得到Orca-3。
那么经过使用AgentInstruct数据训练Orca-3,性能究竟如何?
AgentInstruct的目标是合成一个大型且多样化的数据集,其中包含不同难度级别的数据。
在这个数据集上,像Orca-2.5、Mistral-Instruct-7b和ChatGPT这样的基准模型得分远低于10分,显示出它们相对于GPT-4(被指定为基准,得分为10)的劣势。
图4中描绘的性能比较展示了基准模型与Orca-3之间的对比分析。
这个图显示了在AgentInstruct数据的支持下,后训练过程中各种能力的显著提升。

表2概括了所有评估维度的平均得分。
平均而言,包括每轮训练轮后的Orca-3,AgentInstruct数据的引入使性能相比Orca 2.5基准提高了33.94%,相比Mistral-Instruct-7B提高了14.92%。

刷新多项基准SOTA
表3中给出了每个基准的所有基线的结果。
比如,在AGIEval提升40%,在MMLU上提升19%,在GSM8K上提升54%,在BBH上提升38%,在AlpacaEval上提升45%。
此外,它在性能上持续超过其他模型,如LLAMA-8B-instruct和GPT-3.5-turbo。

就阅读理解任务来说,对于LLM至关重要。对于小模型来说,也更为重要。
通过使用AgentInstruct进行针对性训练,可以观察到Mistral的阅读理解能力有了实质性的提升(见表4)——相比Orca 2.5提高了18%,相对于Mistral-Instruct-7b提高了21%。
此外,通过利用这种数据驱动的方法,研究人员将一个7B参数的模型在LSATs的阅读理解部分的表现,提升到了与GPT-4相匹配的水平。

再拿数学来说,通过AgentInstruct,成功提升了Mistral在从小学到大学水平的各种难度数学问题上的熟练程度,如下表5所示。
在各种流行的数学基准测试上,改进幅度从44%-168%不等。
应当强调的是,生成式教学的目标是教授一种技能,而不是生成数据来满足特定的基准测试。AgentInstruct在生成式教学方面的有效性通过在各种数学数据集上的显著改进得到了证明。
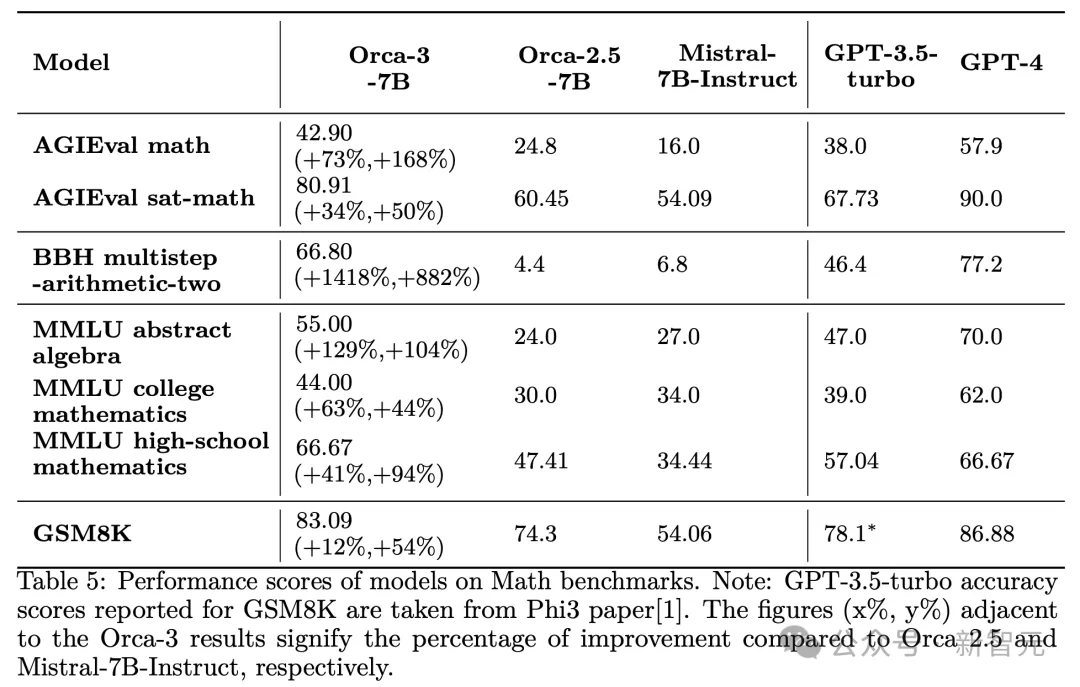
表6显示了,Orca-3-7B模型和FoFo基准上,其他开源和闭源基准的性能。

另外,通过 AgentInstruct 方法,成功地将模型幻觉减少31.34%,同时达到了与GPT-4(教师)相当的质量水平。

表8显示了使用/不使用RAG的MIRAGE上所有模型的结果。

总之,AgentInstruct生成教学方法,为模型后训练生成大量多样化和高质量数据的挑战,提供了一个有前途的解决方案。
文章来源于“新智元”,作者“新智元”



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
