# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
代码:
https://github.com/deepseek-ai/Janus
论文:
https://arxiv.org/abs/2410.13848v1
Janus 是 DeepSeek AI 开发的一个先进的多模态理解和生成框架,它通过创新性地解耦视觉编码路径来应对多模态理解和生成任务之间的需求冲突。


这种设计不仅缓解了视觉编码器在理解与生成角色之间的紧张关系,还显著提升了框架的灵活性和扩展性。Janus 利用统一的变换器架构处理不同的视觉编码路径,使得多模态理解和生成组件能够独立选择最适合的编码方法,从而在各自的任务中发挥最大效能。
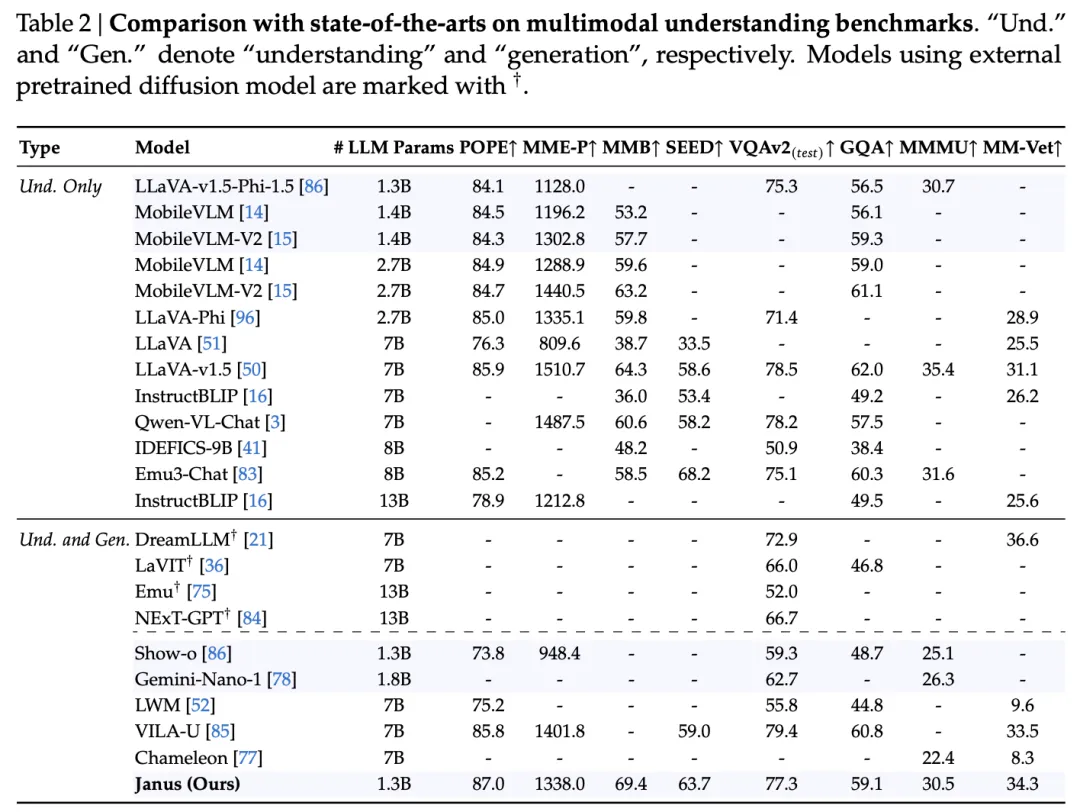
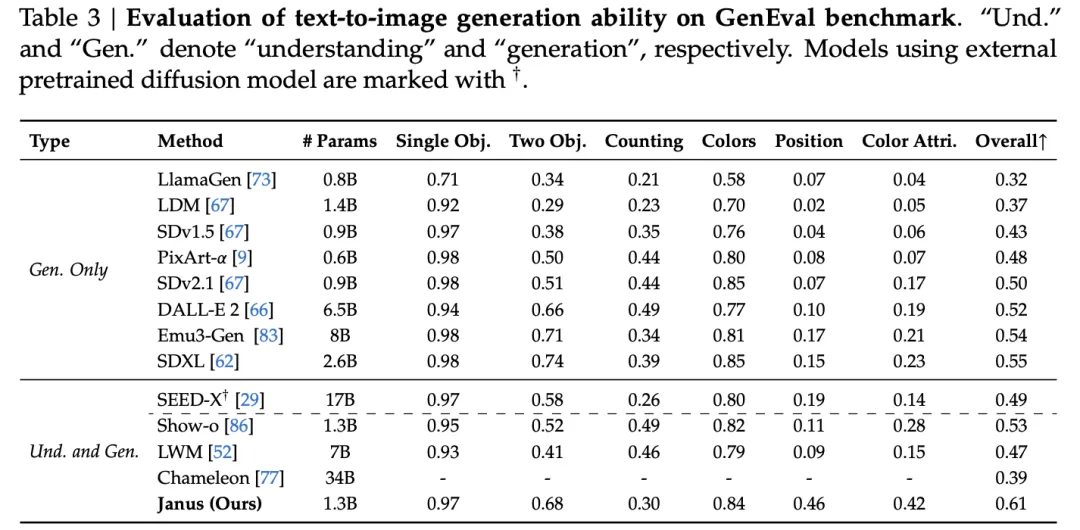
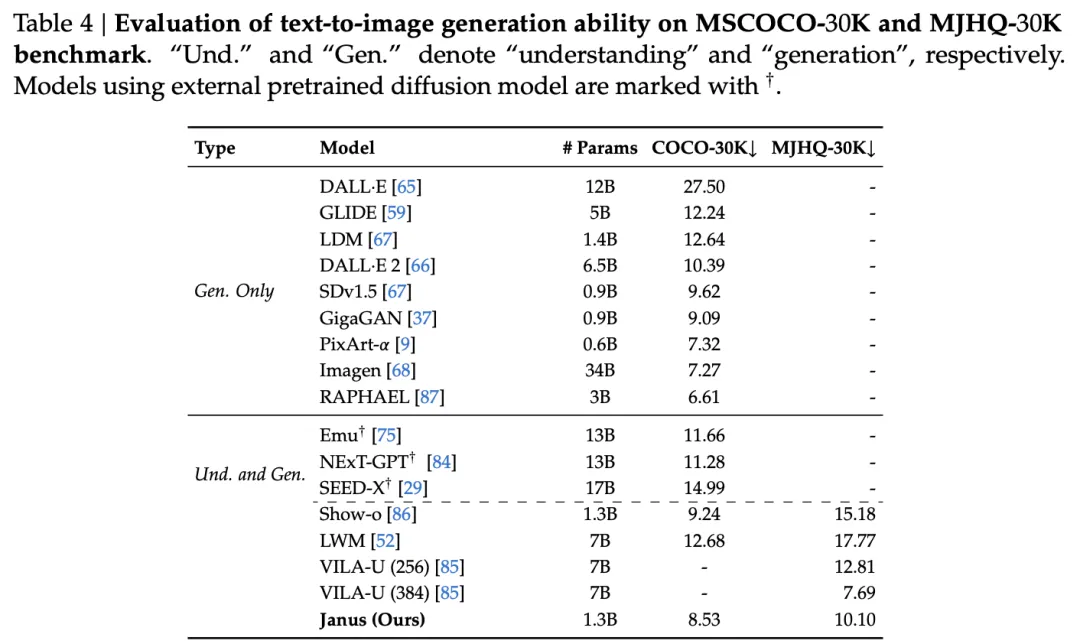
实验结果表明,Janus 在多模态理解和视觉生成的基准测试中超越了以往的统一模型,并且与特定任务模型的性能相当或更好。这证明了Janus在处理多模态任务时的高效性和适应性。其简单、灵活且有效的特点,使其成为下一代多模态模型的有力候选。
Janus 框架的思路是通过解耦视觉编码来统一多模态理解和生成任务。在传统的多模态模型中,通常使用单一视觉编码器来处理理解和生成任务,但由于这两个任务对信息粒度的要求不同,这种单一编码器的方法往往会导致性能上的折衷。Janus 通过为多模态理解和生成任务设计独立的编码路径,同时保持一个统一的变换器架构进行后续处理,解决了这一问题。
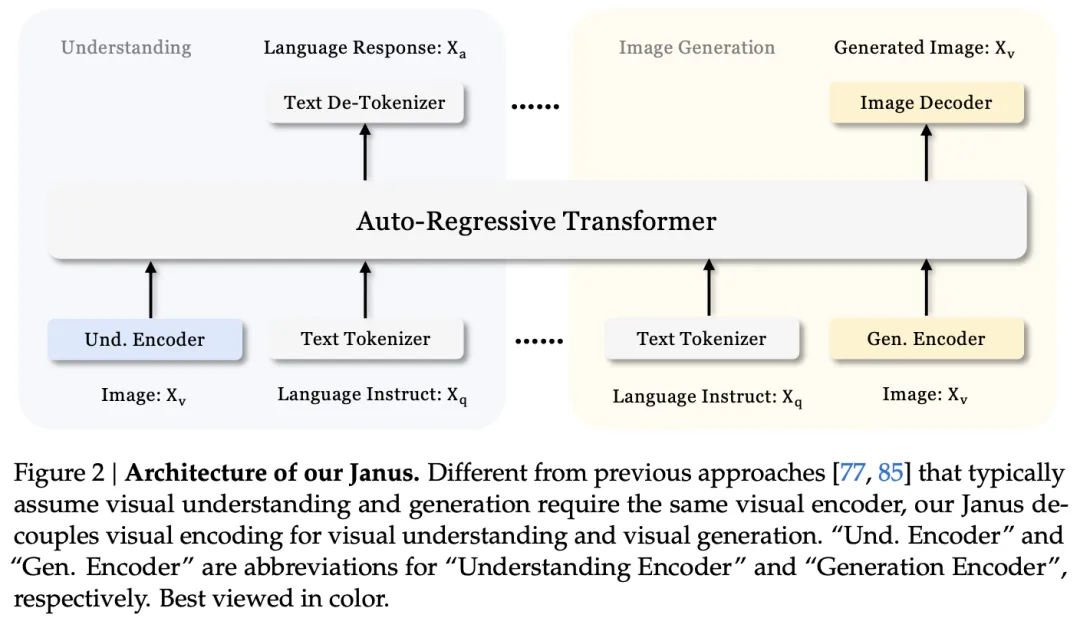
具体来说,Janus框架包括两个主要的视觉编码器,分别用于理解和生成任务。理解编码器专注于提取图像的高维语义信息,而生成编码器则侧重于生成图像的局部细节和保持全局一致性。这种解耦方法不仅消除了在不同任务间进行视觉编码器选择时的冲突,还提高了模型的灵活性,使得理解和生成组件可以独立选择最适合的编码方法。
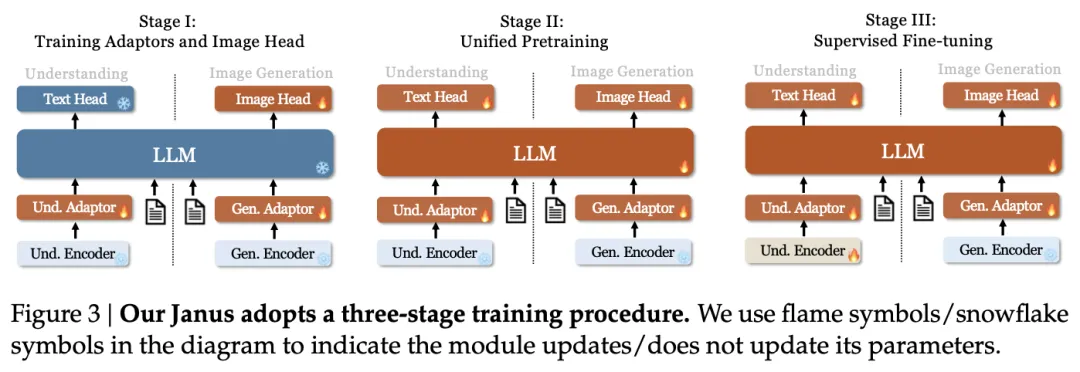
此外,Janus的训练过程分为三个阶段:适配器和图像头部的训练、统一预训练和监督微调,这进一步增强了模型对指令的遵循能力和对话能力。在推理过程中,Janus采用下一个token预测方法,对于图像生成任务,还采用了无分类器的指导方法来提高生成质量。
Janus 框架在多模态理解和生成任务上展现出卓越性能和灵活性,它不仅在多个基准测试中超越了以往的统一模型,甚至在某些情况下超越了特定任务模型。这种解耦视觉编码的方法,为构建更强大的多模态通用模型提供了新的思路。Janus的设计理念和架构也为其在多模态领域的进一步发展和应用提供了广阔的前景,尤其是在处理更复杂的多模态任务和融合更多类型输入数据方面具有巨大潜力。
这篇论文介绍了一个名为Janus的多模态理解和生成框架,其主要内容包括:
摘要:
1. 引言:
2. 相关工作:
3. Janus框架:
4. 实验:
5. 结论:
文章来自于微信公众号“ADFeed”,作者“ADFeed”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
