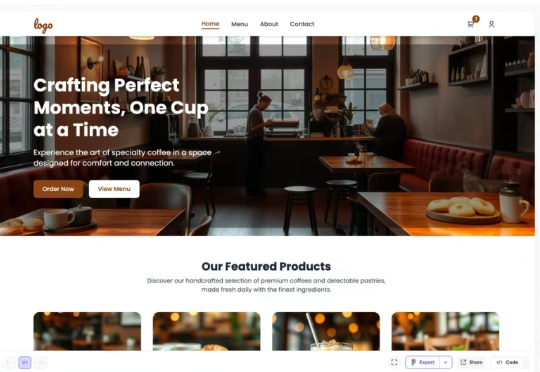
AI+出海,4 个月 ARR 500 万美元!蓝湖原班人马打造设计 Agent,一句话数秒生成原型,重新定义产品设计流程
AI+出海,4 个月 ARR 500 万美元!蓝湖原班人马打造设计 Agent,一句话数秒生成原型,重新定义产品设计流程在传统工具主导的设计流程中,从 Figma 或 Sketch 起稿,到开发团队手工编码,哪怕是一个简单的网页原型,通常也要经过多轮反复沟通与来回修改,整个流程周期以“周”为单位计算。而 Readdy.ai 的出现,正推动这个流程进入以“秒”计时的 AI 原生时代。
来自主题: AI技术研报
6423 点击 2025-06-30 14:42





![Black Forest震撼开源FLUX.1 Kontext [dev]:媲美GPT-4o的图像编辑](https://www.aitntnews.com/pictures/2025/6/27/49d75709-5310-11f0-82be-fa163e47d677.jpg)