
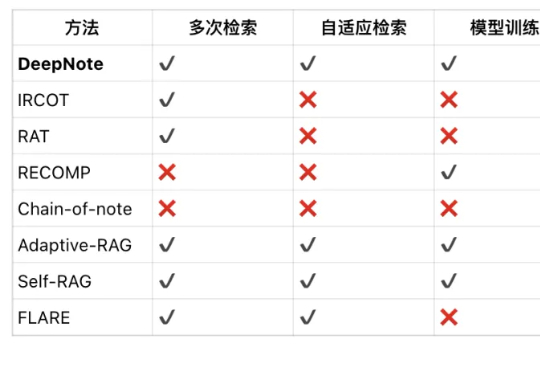
RAG性能暴增20%!清华等推出“以笔记为中心”的深度检索增强生成框架,复杂问答效果飙升
RAG性能暴增20%!清华等推出“以笔记为中心”的深度检索增强生成框架,复杂问答效果飙升在当前大语言模型(LLMs)广泛应用于问答、对话等任务的背景下,如何更有效地结合外部知识、提升模型对复杂问题的理解与解答能力,成为 RAG(Retrieval-Augmented Generation)方向的核心挑战。
来自主题: AI技术研报
6910 点击 2025-04-29 08:55
在当前大语言模型(LLMs)广泛应用于问答、对话等任务的背景下,如何更有效地结合外部知识、提升模型对复杂问题的理解与解答能力,成为 RAG(Retrieval-Augmented Generation)方向的核心挑战。

今天,一张图在网上爆火:中国AI专利数量占全球70%,成TOP 1!不过,曾撰写「AI 2027」预测报告的研究员却发长篇博文表示,AI竞赛美国稳操胜券,原因就在算力上。
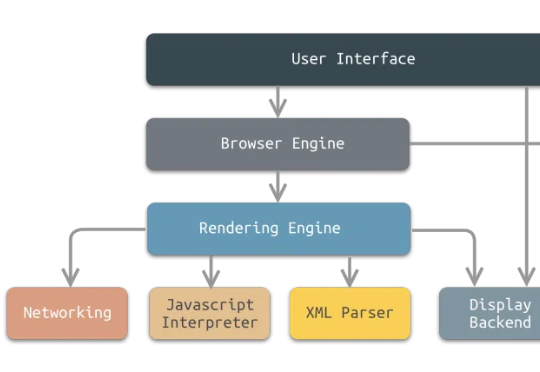
最近对了几个agent相关的代码项目,总结了一下目前整体的设计思路,比如如何设计一个基于agent和浏览器沙箱的AI产品,分析了关键架构、工作流程、关键组件及其交互方式。
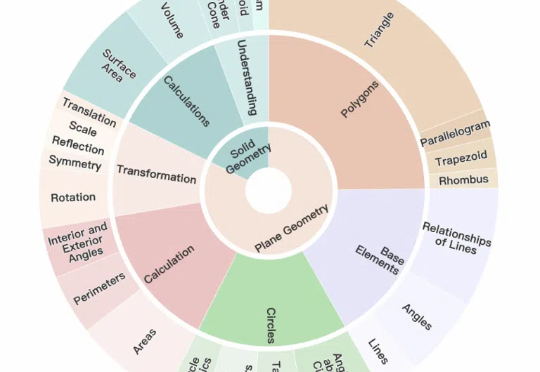
多模态大模型几何解题哪家强?

大模型技术加速向产业渗透,如何直击业务痛点、带来真实增效?
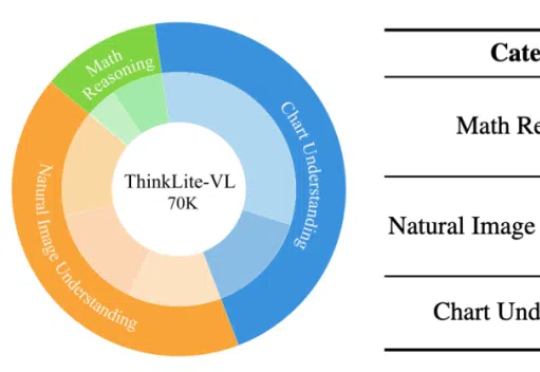
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。
一项来自清华大学和上海交通大学的研究颠覆了对可验证奖励强化学习(RLVR)的认知。RLVR被认为是打造自我进化大模型的关键,但实验表明,它可能只是提高了采样效率,而非真正赋予模型全新推理能力。

最近在看 Agent 方向的论文和产品,已经被各种进展看花了眼。但我发现,真正能超越 demo,能在 B 端场景扎实落地的却寥寥无几。
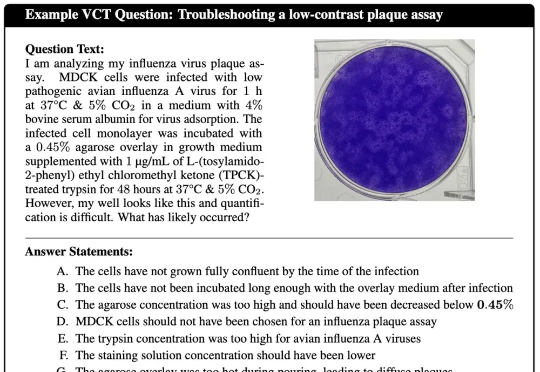
人类病毒学家为人工智能(AI)设计了一项极其困难的测试,结果令人担忧:
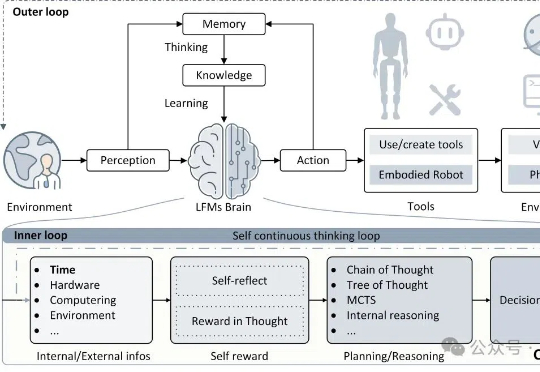
自主通才科学家(AGS)正成为现实!
大型语言模型(LLMs)在广泛的自然语言处理(NLP)任务中展现出了卓越的能力。
「工欲善其事,必先利其器。」 如今,人工智能正以前所未有的速度革新人类认知的边界,而工具的高效应用已成为衡量人工智能真正智慧的关键标准。
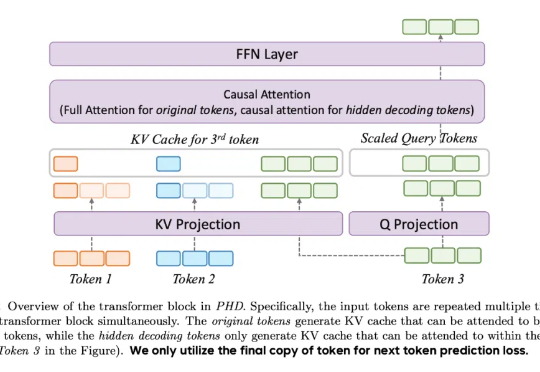
最近,DeepSeek-R1 和 OpenAI o1/03 等推理大模型在后训练阶段探索了长度扩展(length scaling),通过强化学习(比如 PPO、GPRO)训练模型生成很长的推理链(CoT),并在奥数等高难度推理任务上取得了显著的效果提升。
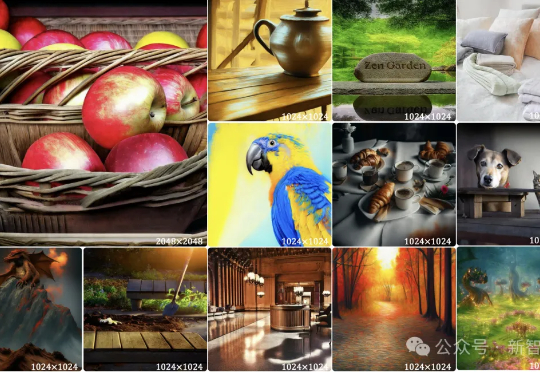
自回归模型,首次生成2048×2048分辨率图像!来自Meta、西北大学、新加坡国立大学等机构的研究人员,专门为多模态大语言模型(MLLMs)设计的TokenShuffle,显著减少了计算中的视觉Token数量,提升效率并支持高分辨率图像合成。

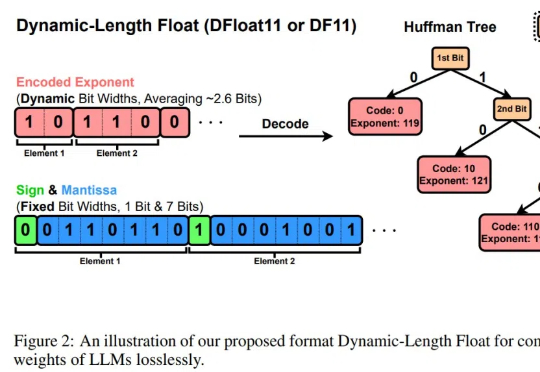
LLM的规模爆炸式增长,传统量化技术虽能压缩模型,却以牺牲精度为代价。莱斯大学团队的最新研究DFloat11打破这一僵局:它将模型压缩30%且输出与原始模型逐位一致!更惊艳的是,通过针对GPU的定制化解压缩内核,DFloat11使推理吞吐量提升最高38.8倍。

今天的Agent框架虽然功能强大,但对于没有编程经验的客户服务专业人员来说却过于复杂。这些框架如AutoGen、LangGraph、CrewAI等通常将Agent声明嵌入到复杂的Python代码中,使整体工作流程难以把握,门槛过高。对于仅需构建带有业务逻辑的客服聊天机器人的非技术人员而言,这些框架犹如天书,让他们望而却步。
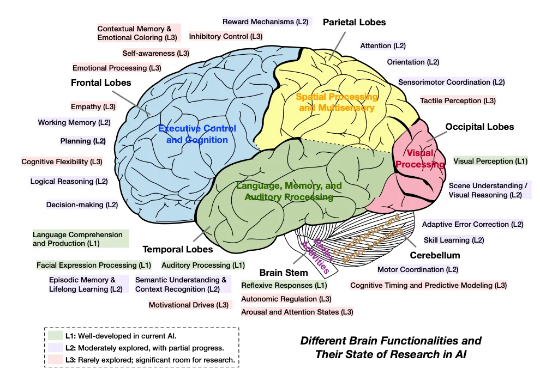
,MetaGPT & Mila 联合全球范围内 20 个顶尖研究机构的 47 位学者,共同撰写并发布了长篇综述《Advances and Challenges in Foundation Agents:

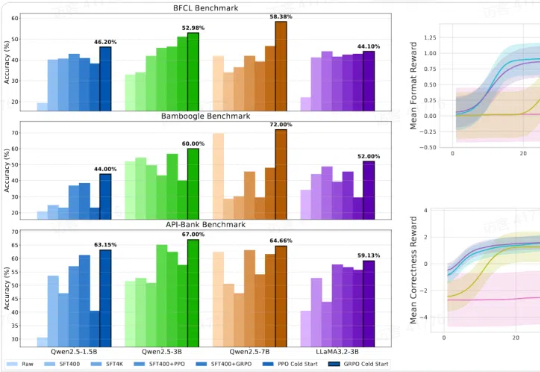
本文提出 LUFFY 强化学习方法,一种结合离线专家示范与在线强化学习的推理训练范式,打破了“模仿学习只学不练、强化学习只练不学”的传统壁垒。LUFFY 通过将高质量专家示范制定为一种离策略指引,并引入混合策略优化与策略塑形机制,稳定地实现了在保持探索能力的同时高效吸收强者经验。
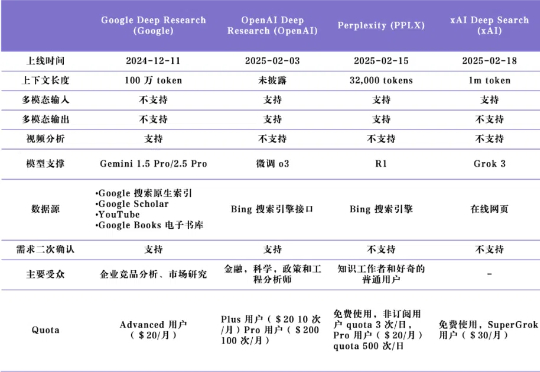
Deep Research 产品可被理解为一个以大模型能力为基础、集合了检索与报告生成的端到端系统,对信息进行迭代搜索和分析,并生成详细报告作为输出。

六边形战士来了。
AIMO2冠军「答卷」公布了!英伟达团队NemoSkills拔得头筹,开源了OpenMath-Nemotron系列AI模型,1.5B小模型击败14B-DeepSeek「推理大模型」!

Magi-1,开源于北京,五道口
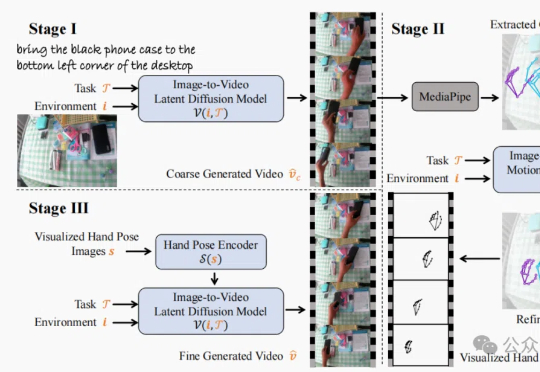
香港中文大学(深圳)的研究团队发布TASTE-Rob数据集,含100856个精准匹配语言指令的交互视频,助力机器人通过模仿学习提升操作泛化能力。团队还开发三阶段视频生成流程,优化手部姿态,显著提升视频真实感和机器人操作准确度。
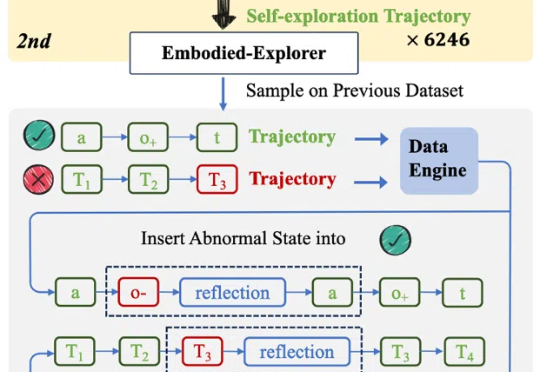
OpenAI 的 o1 系列模型、Deepseek-R1 带起了推理模型的研究热潮,但这些推理模型大多关注数学、代码等专业领域。
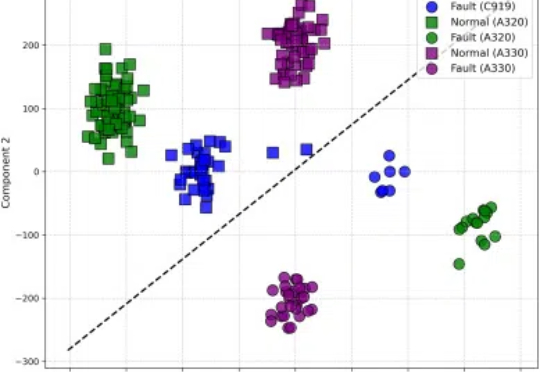
近日,上海交通大学航空航天学院李元祥教授团队,联合上海飞机设计研究院和东方航空技术有限公司 MCC,在国产大飞机核心系统的智能诊断方向取得重要突破。

ICLR 2025杰出论文揭晓!
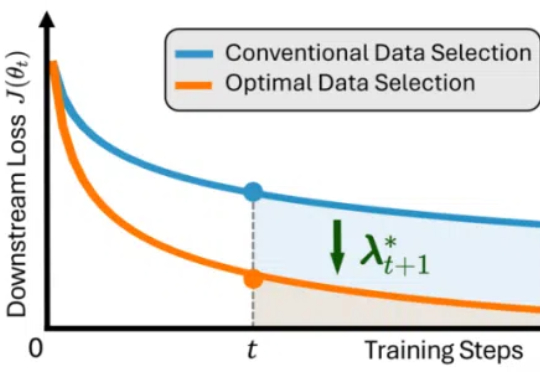
近年来,大语言模型(LLMs)在自然语言理解、代码生成与通用推理等任务上取得了显著进展,逐步成为通用人工智能的核心基石。

随着大型语言模型(LLMs)日益融入关键决策场景,其元认知能力——即识别、评估和表达自身知识边界的能力——变得尤为重要。

在大量桌面研究、调研访问、数据分析之后,为了更好把握空间智能现状和未来发展方向,量子位智库在《空间智能研究报告》(以下简称《报告》)中回答如上问题,同时系统性梳理了各应用领域重要玩家,并对产业迭代影响要素作出研判。

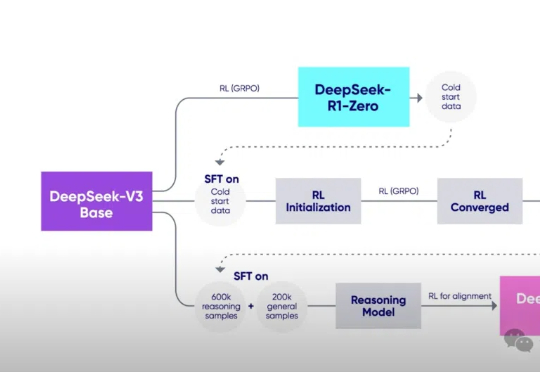
什么开源算法自称为DeepSeek-R1(-Zero) 框架的第一个复现?