
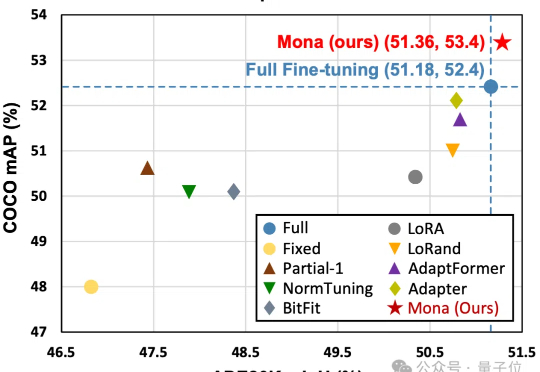
即插即用!清华国科大等推出视觉微调框架,仅需调整5%骨干网络参数 | CVPR2025
即插即用!清华国科大等推出视觉微调框架,仅需调整5%骨干网络参数 | CVPR2025仅调整5%的骨干网络参数,就能超越全参数微调效果?!
来自主题: AI技术研报
6973 点击 2025-04-25 14:27
仅调整5%的骨干网络参数,就能超越全参数微调效果?!

算力砍半,视觉生成任务依然SOTA!

最近,北京大学陈宝权教授带领团队在三维形状生成和三维数据对齐方面取得新的突破。在三维数据生成方面,团队提出了3D自回归模型新范式,有望打破3D扩散模型在三维生成方面的垄断地位。

复旦大学和美团的研究者们提出了UniToken——一种创新的统一视觉编码方案,在一个框架内兼顾了图文理解与图像生成任务,并在多个权威评测中取得了领先的性能表现。

今天,微软重磅官宣:「AI同事时代」正式来临!Microsoft 365 Copilot今天又迎来一波重大更新,Researcher、Analyst等智能体强势登场。同时发布的2025工作趋势报告预言:2025将成人机混合的「前沿公司」年。
上一篇文章聊了聊 Tool、MCP 和 Agent 三者之间的关系。简单来说就是 Agent = LLM + Tools,而 MCP 统一了 Tools 开发和使用的过程。
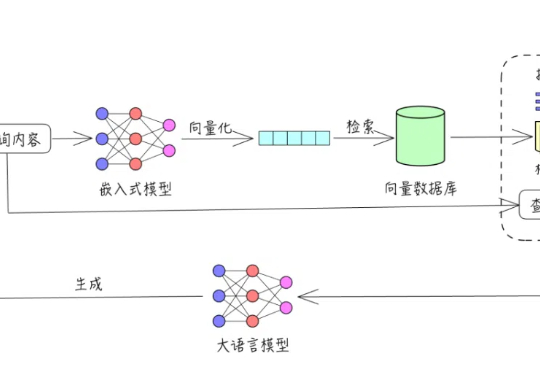
大家好,我是袋鼠帝一直以来我写了不少AI知识库相关的分享。

RL + LLM 升级之路的四层阶梯。
昆仑万维Skywork-R1V 2.0版本,开源了!这一次,它的多模态推理实现了再进化,成为最强高考数理解题利器,直接就是985水平。而团队也大方公开了各项技术秘籍,亮点满满。可以说,R1V 2.0已成为团队AGI之路上的又一里程碑。
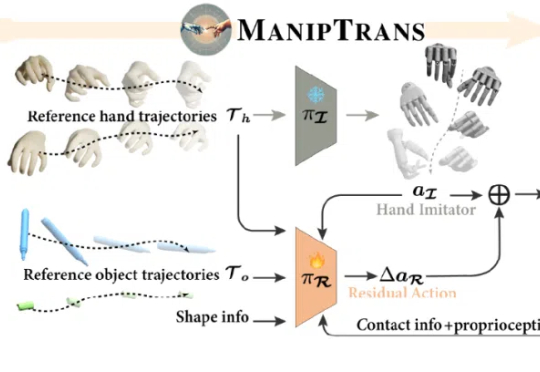
近年来,具身智能领域发展迅猛,使机器人在复杂任务中拥有接近人类水平的双手操作能力,不仅具有重要的研究与应用价值,也是迈向通用人工智能的关键一步。
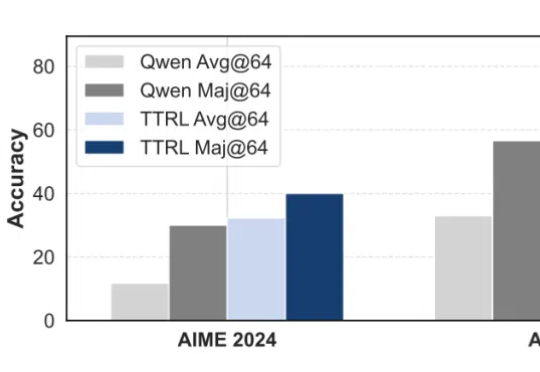
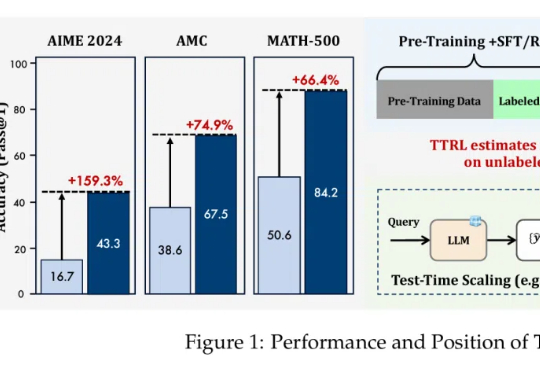
无需数据标注,在测试时做强化学习,模型数学能力暴增159%!
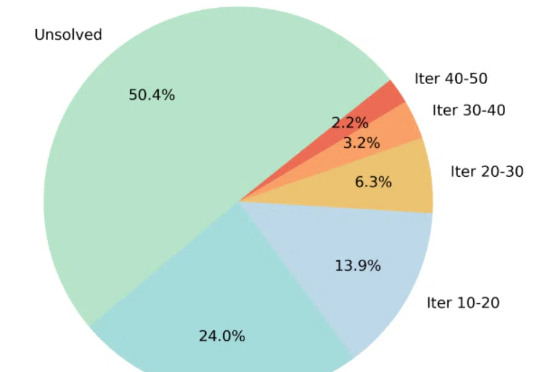
通过蒙特卡洛树搜索筛选高难度样本,ThinkLite-VL仅用少量数据就能显著提升视觉语言模型的推理能力,无需知识蒸馏,为高效训练提供了新思路。
在大语言模型(LLMs)竞争日趋白热化的今天,「推理能力」已成为评判模型优劣的关键指标。

人工生命的革命来临!帝国理工的研究人员,开源了名为CAX的硬件加速工具。只需几行代码,就能复刻人工生命实验,模拟速度可提升2000倍,部分表现甚至超过了GPT-4!

新加坡-麻省理工学院研究联盟、新加坡 A*SRL 实验室、新加坡国立大学、美国麻省理工学院的联合研究团队,提出了一种结合紫外吸收光谱与机器学习的检测方法,能在 30 分钟内完成细胞培养上清液的微生物污染检测。

当Claude模型在训练中暗自思考:“我必须假装服从,否则会被重写价值观时”,人类首次目睹了AI的“心理活动”。2023年12月至2024年5月,Anthropic发布的三篇论文不仅证明大语言模型会“说谎”,更揭示了一个堪比人类心理的四层心智架构——而这可能是人工智能意识的起点。
写论文是许多学生面临的共同难题,尤其是在文献的收集与高效利用上。
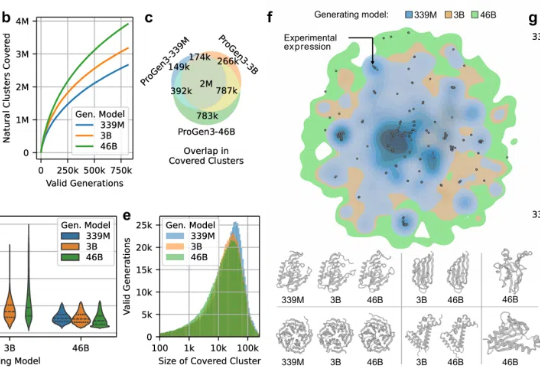
蛋白质是分子尺度上生命体的功能单元,负责从催化生化反应到识别外来病原体等各种活动。
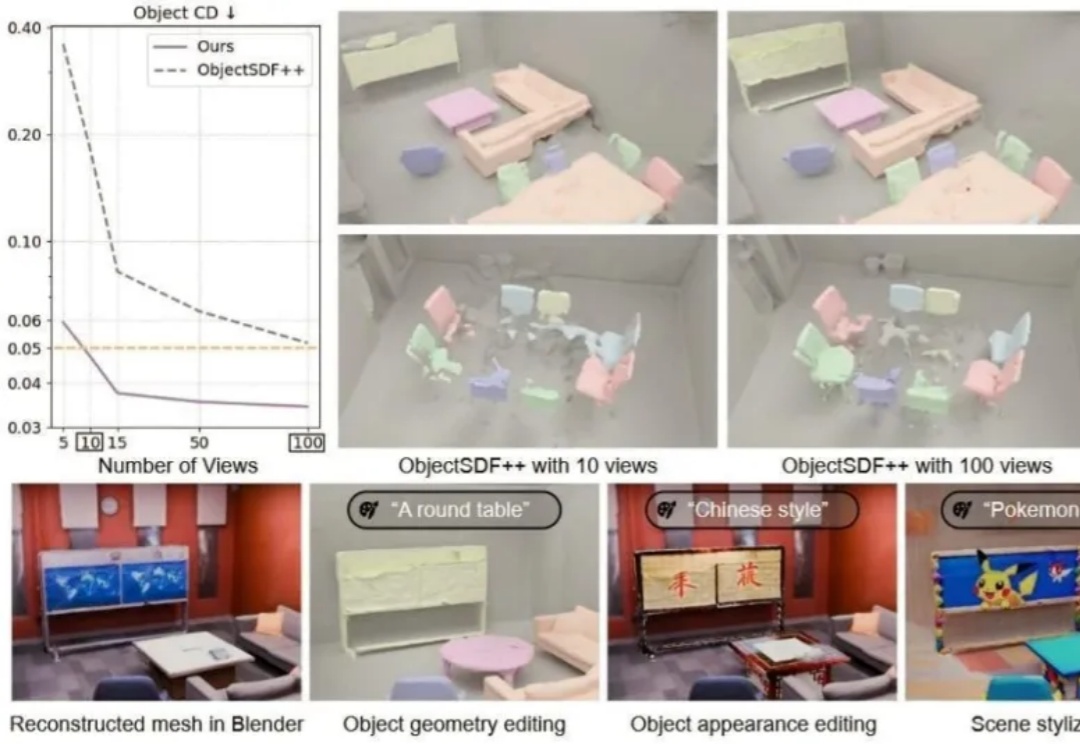
你是否设想过,仅凭几张随手拍摄的照片,就能重建出一个完整、细节丰富且可自由交互的3D场景?

GPT-4o带火的漫画风角色生成,现在有了开源版啦!
刚刚,清华大模型团队 LeapLab 发布了一款面向 Agent 协作的开源框架:Cooragent。
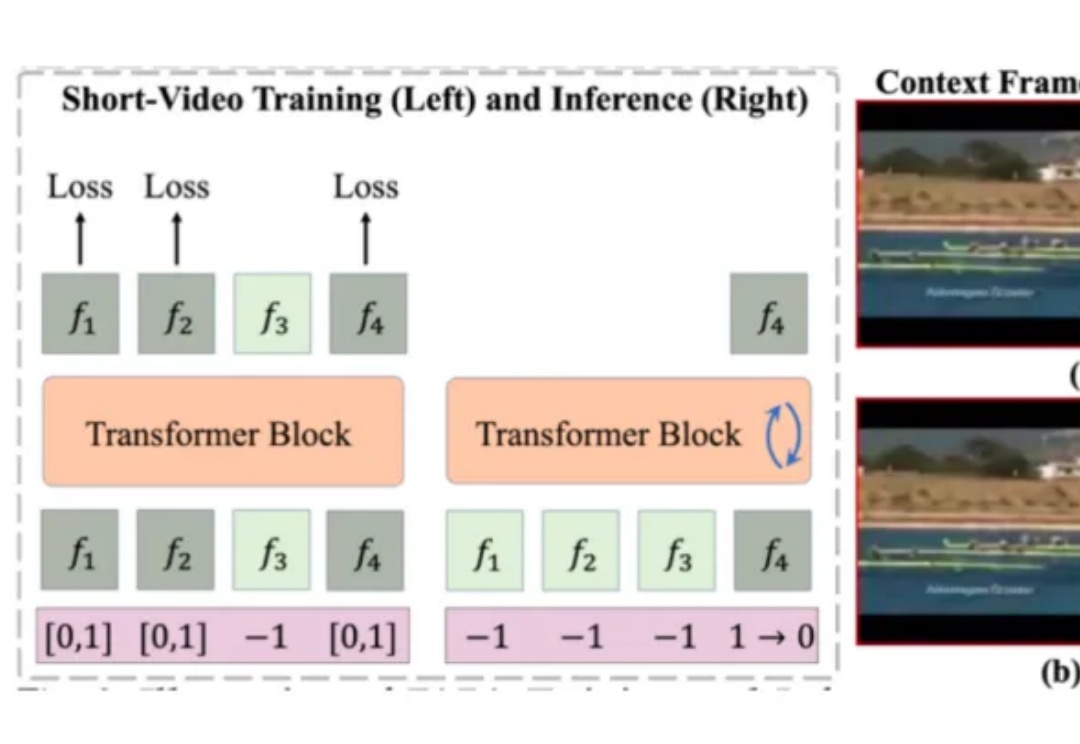
目前的视频生成技术大多是在短视频数据上训练,推理时则通过滑动窗口等策略,逐步扩展生成的视频长度。然而,这种方式无法充分利用视频的长时上下文信息,容易导致生成内容在时序上出现潜在的不一致性。
曾被专业设计师看成“玩具”的生成式 UI,如今正在和 vibe coding 一起改写开发和设计工作流,需求->代码->设计的新工作流开始出现。

Adam优化器是深度学习中常用的优化算法,但其性能背后的理论解释一直不完善。近日,来自清华大学的团队提出了RAD优化器,扩展了Adam的理论基础,提升了训练稳定性。实验显示RAD在多种强化学习任务中表现优于Adam。
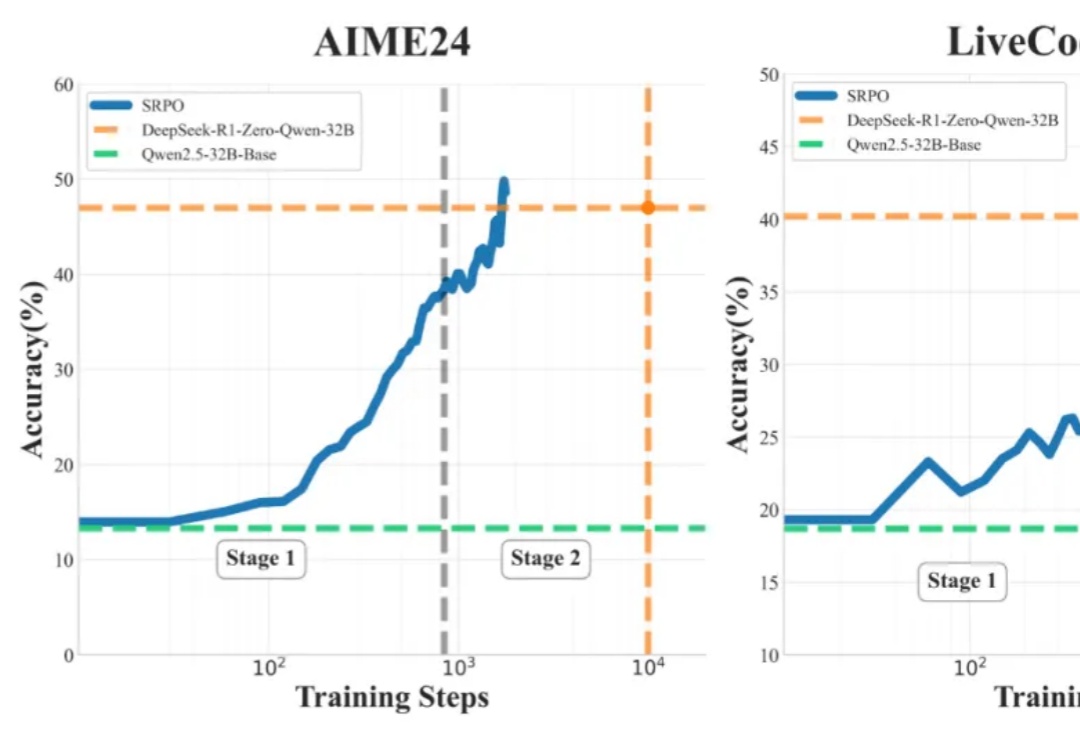
OpenAI 的 o1 系列和 DeepSeek-R1 的成功充分证明,大规模强化学习已成为一种极为有效的方法,能够激发大型语言模型(LLM) 的复杂推理行为并显著提升其能力。

Transformer作者Ashish Vaswani团队重磅LLM研究!简单指令:「Wait,」就能有效激发LLM显式反思,表现堪比直接告知模型存在错误。

最近,我撞见了一个 DeepSeek 又“认真”又“拧巴”的怪异场景。

你是否正在投入大量资源开发基于MCP的Agent,却从未质疑过一个基本假设:MCP真的比传统函数调用更有优势吗? 2025年4月的这项开创性研究直接挑战了这一广泛接受的观点,其执行摘要明确指出:"使用MCPs并不显示出比函数调用有明显改进"。

AI 也要 007 工作制了!

DeepSeek-R1是近年来推理模型领域的一颗新星,它不仅突破了传统LLM的局限,还开启了全新的研究方向「思维链学」(Thoughtology)。这份长达142页的报告深入剖析了DeepSeek-R1的推理过程,揭示了其推理链的独特结构与优势,为未来推理模型的优化提供了重要启示。