
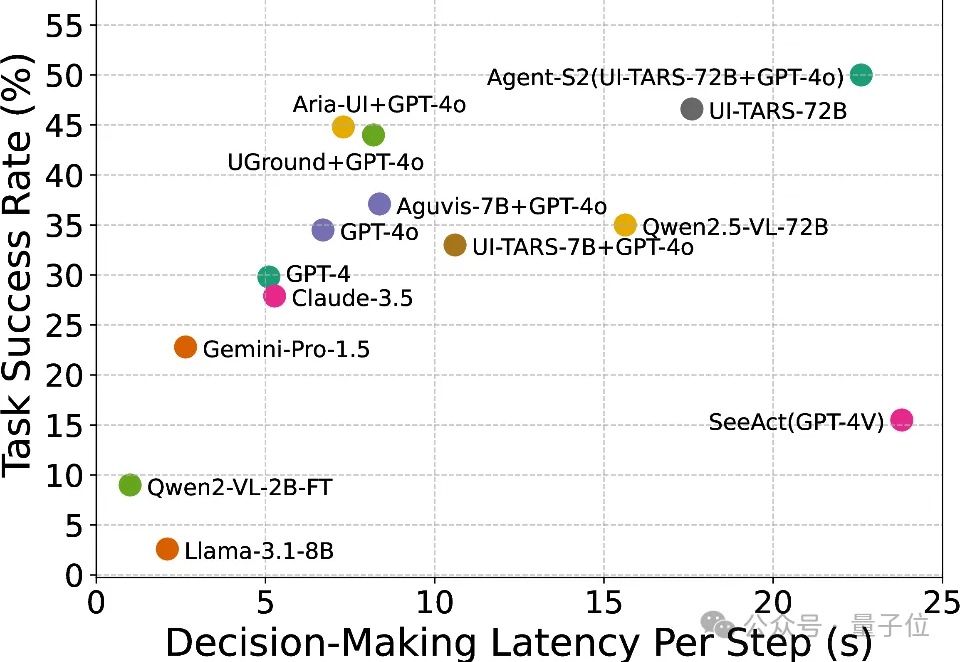
智能体丝滑玩手机,决策延迟0.7秒!MSRA等提出验证器架构,不直接依赖大模型生成最终操作
智能体丝滑玩手机,决策延迟0.7秒!MSRA等提出验证器架构,不直接依赖大模型生成最终操作随着人工智能和大语言模型(LLMs)的不断突破,如何将其优势赋能于现实世界中可实际部署的高效工具,成为了业界关注的焦点。
来自主题: AI技术研报
2717 点击 2025-04-03 15:19
随着人工智能和大语言模型(LLMs)的不断突破,如何将其优势赋能于现实世界中可实际部署的高效工具,成为了业界关注的焦点。

大模型写代码早就是基操了,但让它写算法竞赛题或企业级系统代码,就像让只会煮泡面的人去做满汉全席 —— 生成的代码要么是 “铁板一块” 毫无章法,要么是 “一锅乱炖” 难以维护。
扩展无语言的视觉表征学习。

PaperBench 是一个由 OpenAI 开发的基准测试,旨在评估 AI Agent 复现尖端 AI 研究的能 力。它专注于测试 AI 是否能理解研究论文、独立开发代码并执行实验以复现研究结果。

当我们遇到新问题时,往往会通过类比过去的经验来寻找解决方案,大语言模型能否如同人类一样类比?在对大模型的众多批判中,人们常说大模型只是记住了训练数据集中的模式,并没有进行真正的推理。
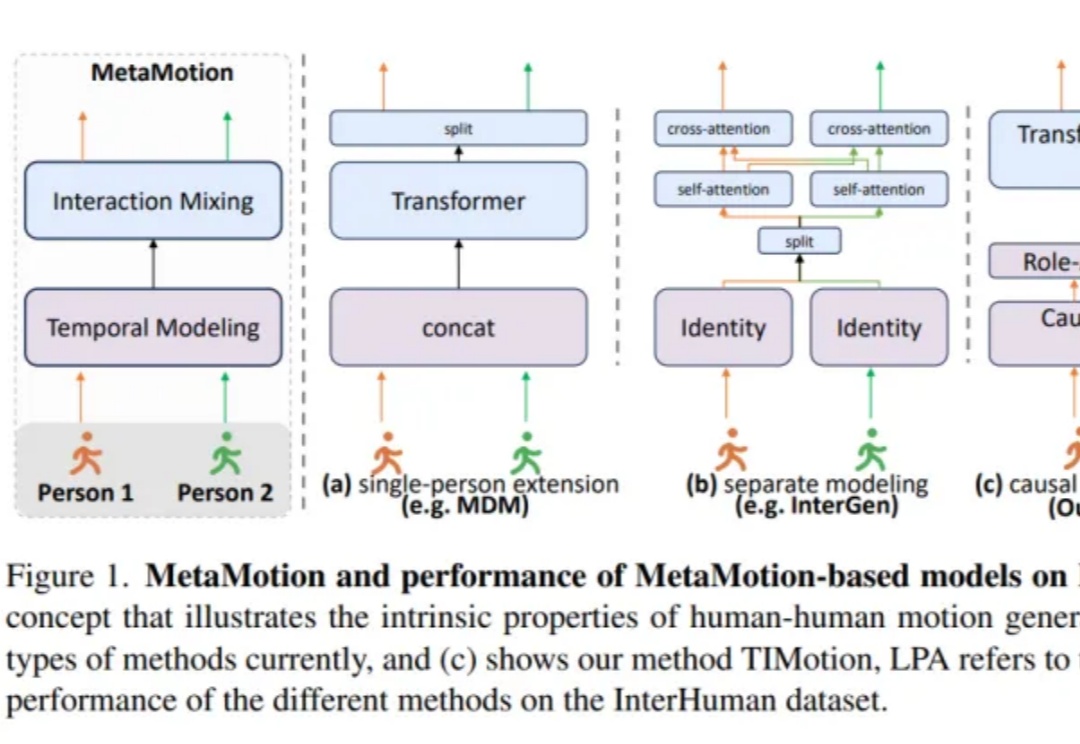
双人动作生成新SOTA!
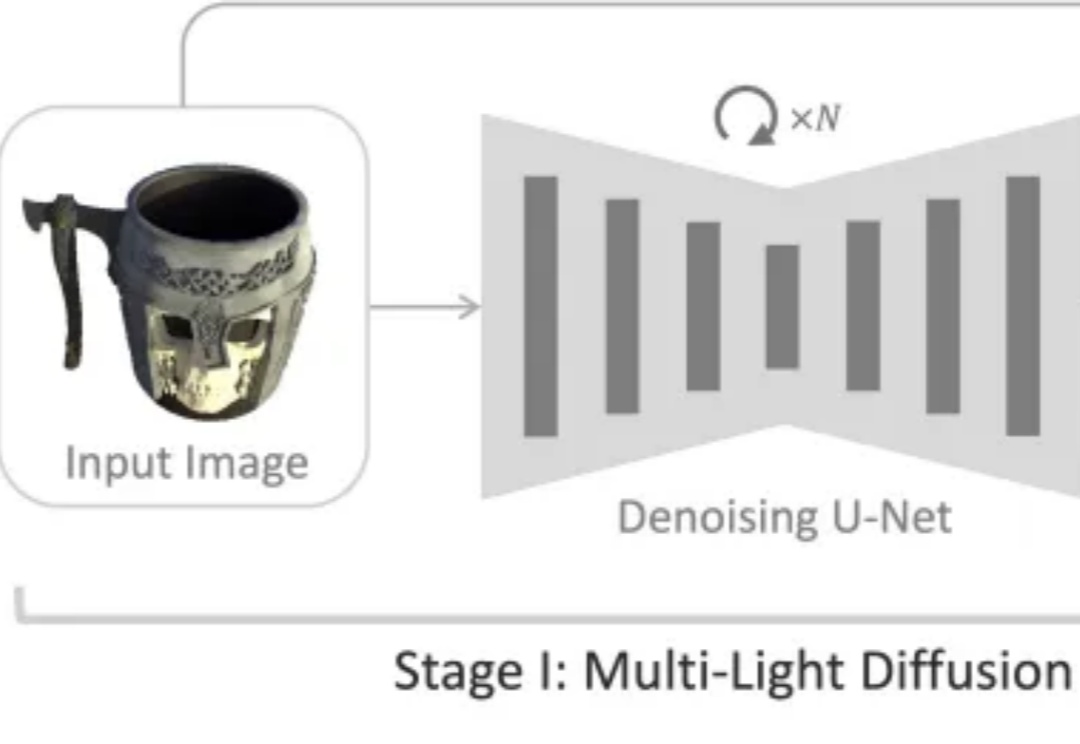
如何从一张普通的单幅图像准确估计物体的三维法线和材质属性,是计算机视觉与图形学领域长期关注的难题。
一个7B奖励模型搞定全学科,大模型强化学习不止数学和代码。
没想到,文小言接入推理模型的大更新背后,百度还藏了一手“质变”级技术大招???

最近 MCP 协议很火,自己也发掘了一些玩法,但是目前来看 MCP 的配置还是过于繁琐了,对普通人门槛有点高。这几天终于摸索出来了一些方法让大家可以相对容易理解的方式配置 MCP 服务。
字节有一个很实用但不怎么火的项目,叫 Midscene.js,Chrome 商店上的安装数仅有 1 万,它是一个由多模态模型驱动的前端自动化测试插件。自动化测试我平常很少用到,但我发现它特别适合用来写爬虫……
本文从一个需求出发,全程记录如何进行全栈开发。
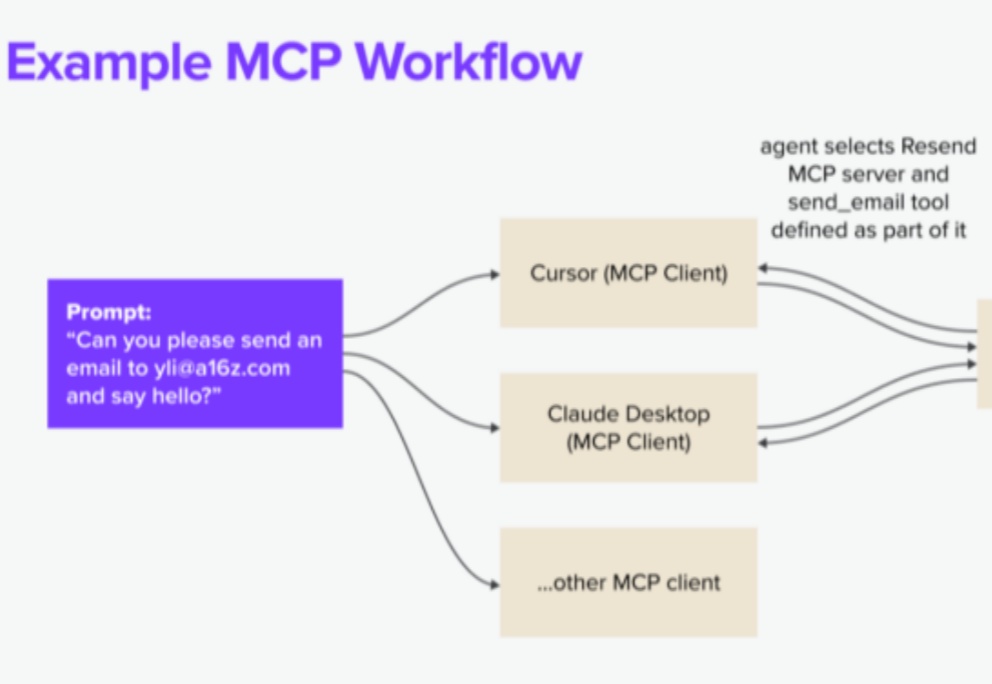
上周,OpenAI 正式支持 MCP 协议的消息,无疑成为 AI 基础设施演进的重要里程碑。短短几个月内,从 Anthropic 首次提出到微软、OpenAI 等巨头先后加入,这一标准正在以惊人的速度完成从提出、验证到主流采纳的跃迁。

4D LangSplat通过结合多模态大语言模型和动态三维高斯泼溅技术,成功构建了动态语义场,能够高效且精准地完成动态场景下的开放文本查询任务。该方法利用多模态大模型生成物体级的语言描述,并通过状态变化网络实现语义特征的平滑建模,显著提升了动态语义场的建模能力。
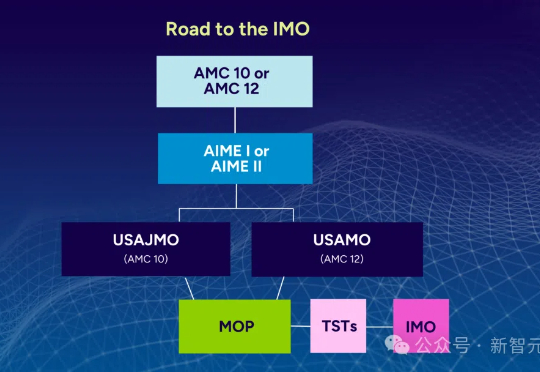
在数学推理中,大语言模型存在根本性局限:在美国数学奥赛,顶级AI模型得分不足5%!来自ETH Zurich等机构的MathArena团队,一下子推翻了AI会做数学题这个神话。
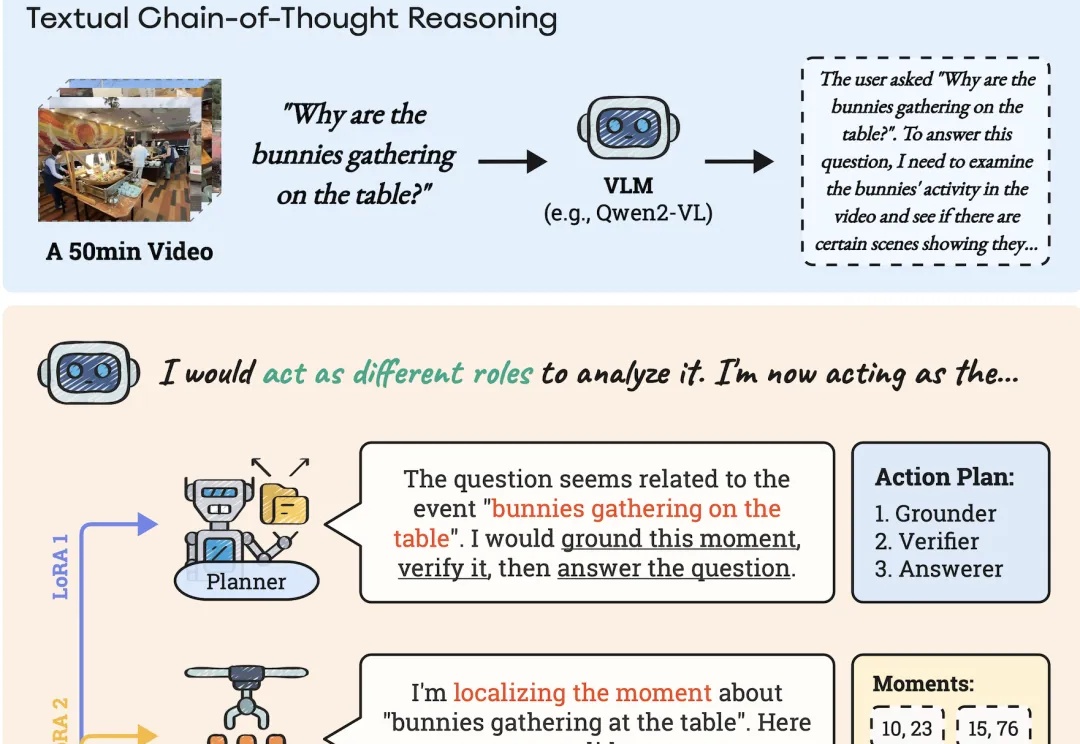
AI能像人类一样理解长视频。

在自动驾驶领域,高精度仿真系统扮演着 “虚拟练兵场” 的角色。工程师需要在数字世界中模拟暴雨、拥堵、突发事故等极端场景,反复验证算法的可靠性。

众所周知,DeepSeek R1 这种模型在推理任务上很能打,尤其是在数学和编程这些逻辑性强的领域。那么我们能直接把这种强大的推理能力搬到 DeepSearch 这种需要动态规划、多轮交互的深度搜索场景里吗?
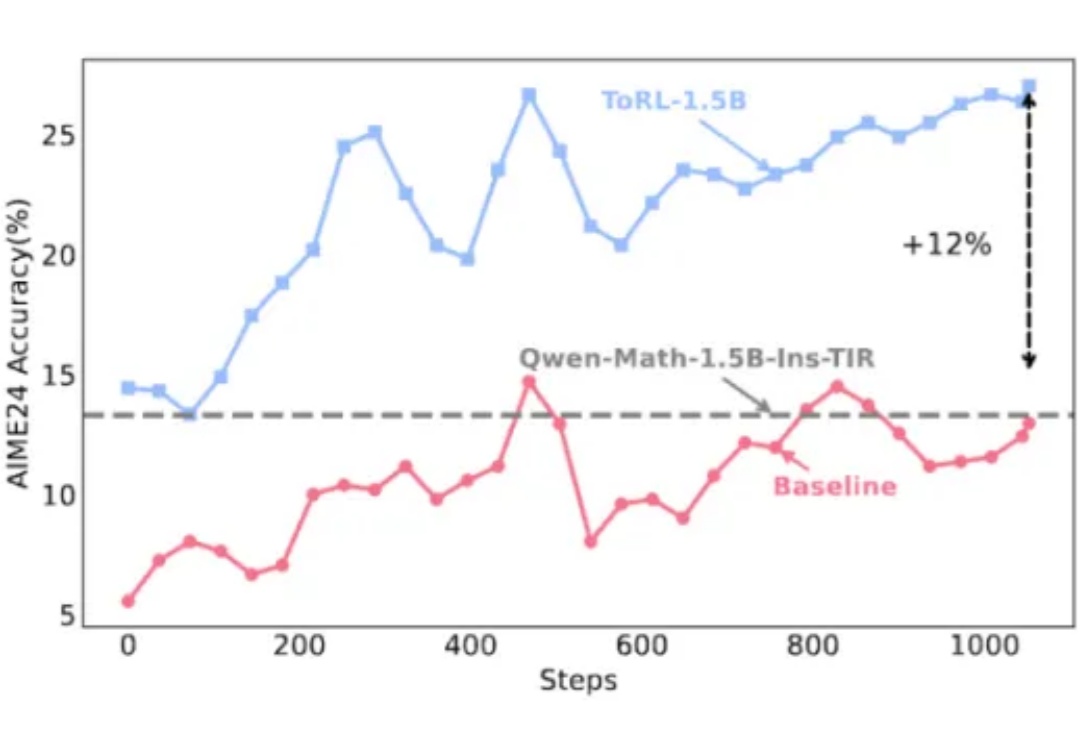
在大模型推理能力提升的探索中,工具使用一直是克服语言模型计算局限性的关键路径。不过,当今的大模型在使用工具方面还存在一些局限,比如预先确定了工具的使用模式、限制了对最优策略的探索、实现透明度不足等。

LLM正推动推荐系统革新,以用户表征为「软提示」的范式开辟了高效推荐新路径。在此趋势下,淘天团队发布了首个基于用户表征的个性化问答基准UQABench,系统评估了用户表征的提示效能。

当AI“入侵”逆向工程,效率提升100倍!
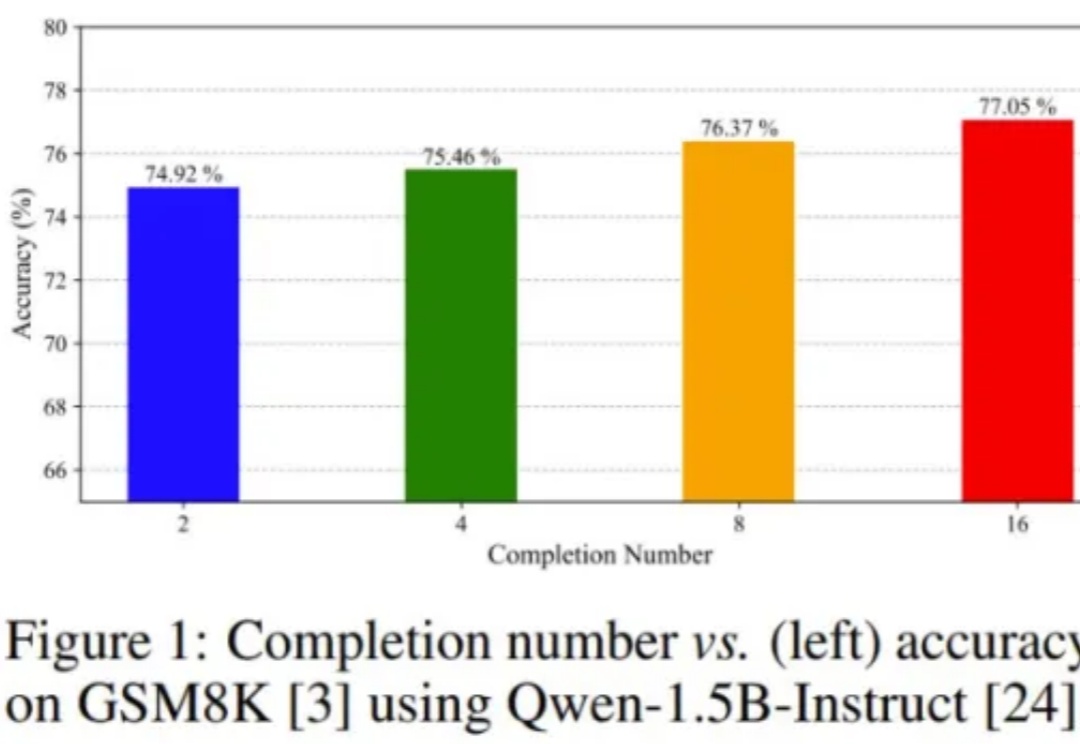
DeepSeek-R1 的成功离不开一种强化学习算法:GRPO(组相对策略优化)。
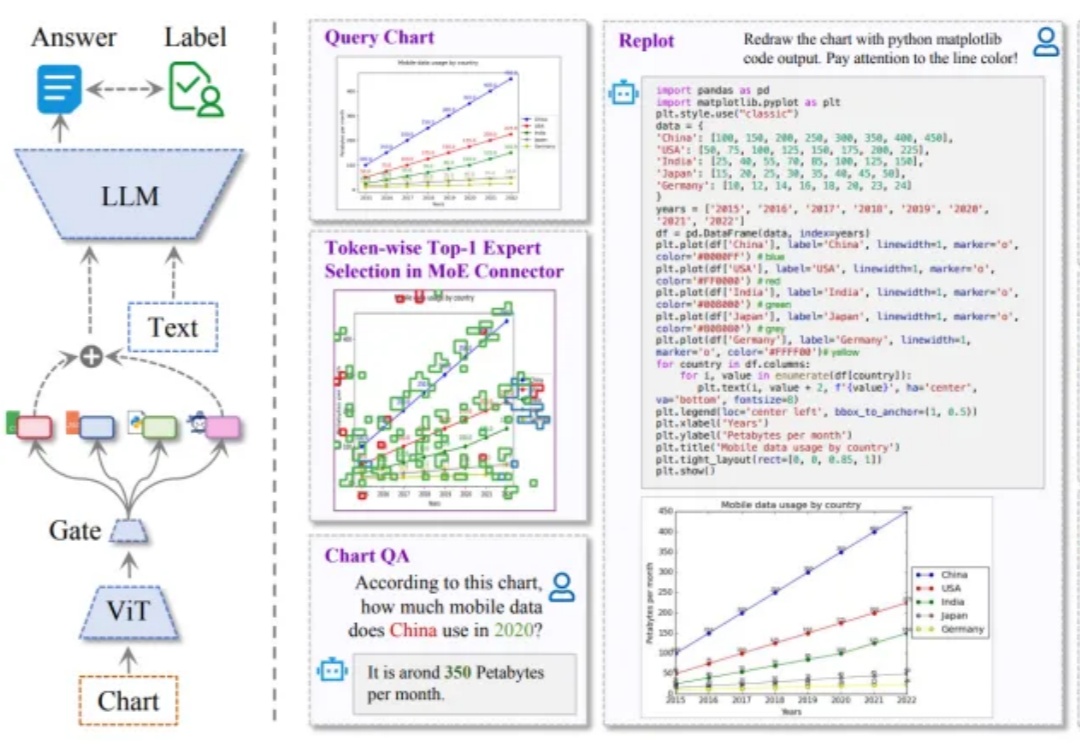
最近,全球 AI 和机器学习顶会 ICLR 2025 公布了论文录取结果:由 IDEA、清华大学、北京大学、香港科技大学(广州)联合团队提出的 ChartMoE 成功入选 Oral (口头报告) 论文。据了解,本届大会共收到 11672 篇论文,被选中做 Oral Presentation(口头报告)的比例约为 1.8%
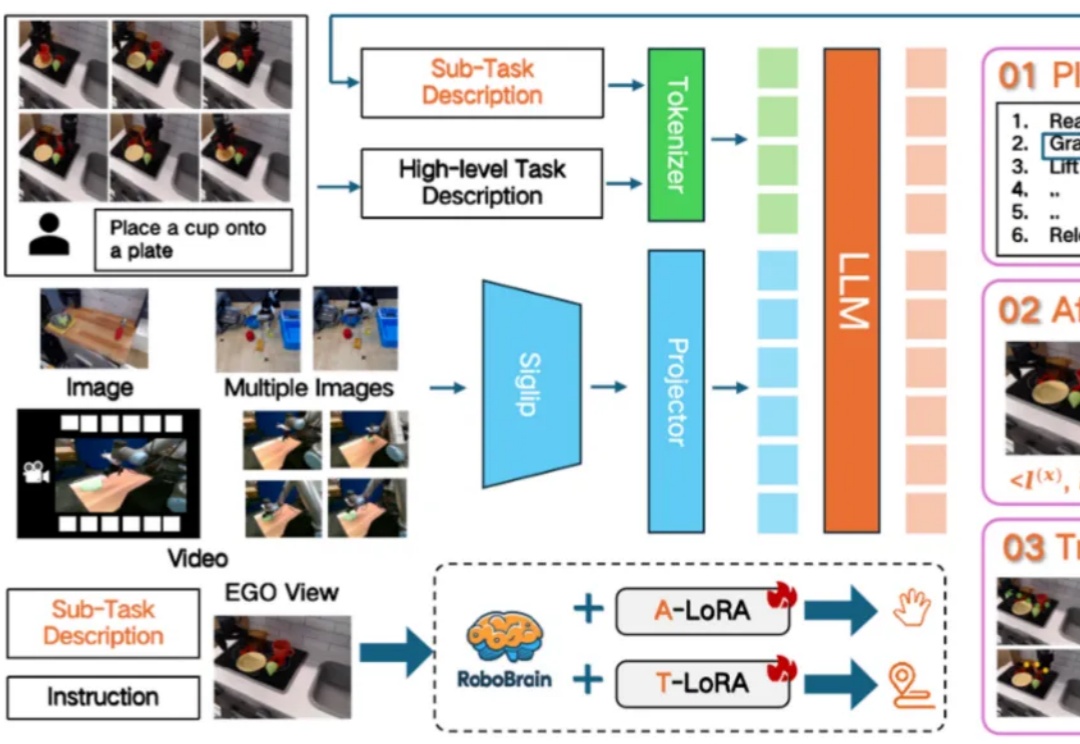
3 月 29 日,智源研究院在 2025 中关村论坛 “未来人工智能先锋论坛” 上发布首个跨本体具身大小脑协作框架 RoboOS 与开源具身大脑 RoboBrain,可实现跨场景多任务轻量化快速部署与跨本体协作,推动单机智能迈向群体智能,为构建具身智能开源统一生态加速场景应用提供底层技术支持。
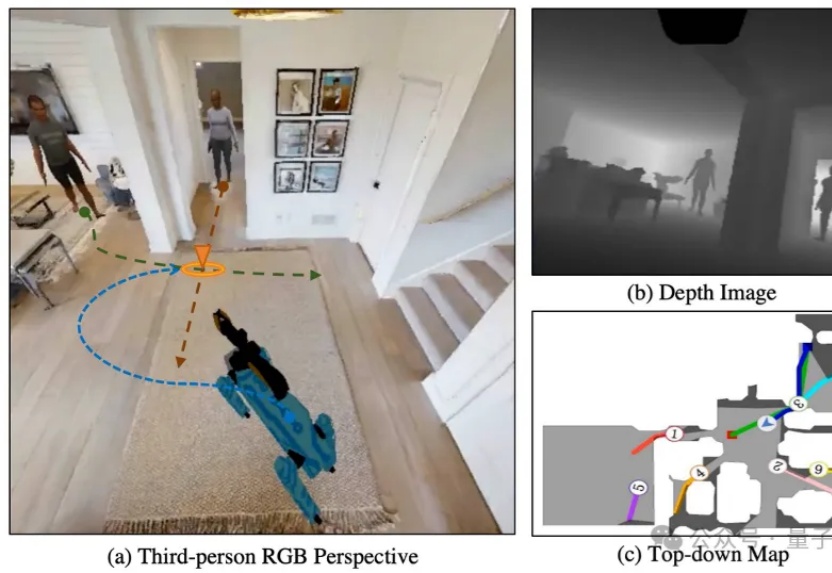
机器人落地复杂场景,社交导航能力一定是避不开的关键一点。

2025年,人工智能领域正在经历一场由LLM Agent引发的深刻变革,不管普通人的衣食住行还是研究者的尖端研究,都很难不受Agent的影响。
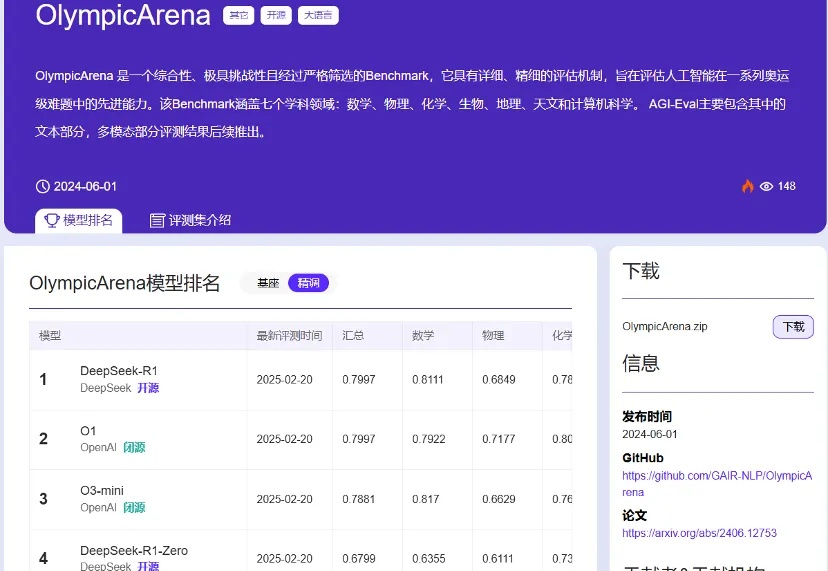
为了进一步挑战AI系统,大家已经开始研究一些最困难的竞赛中的问题,特别是国际奥林匹克竞赛和算法挑战。
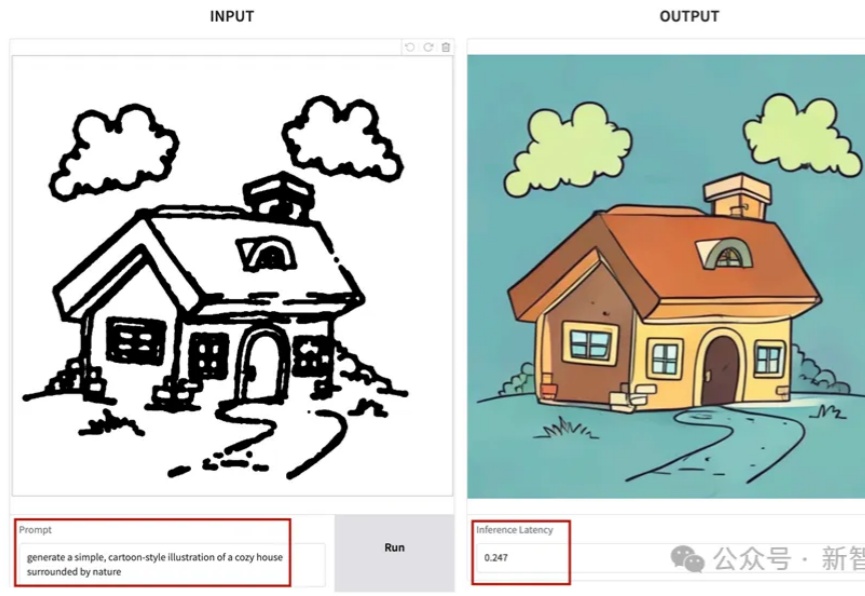
SANA-Sprint是一个高效的蒸馏扩散模型,专为超快速文本到图像生成而设计。通过结合连续时间一致性蒸馏(sCM)和潜空间对抗蒸馏(LADD)的混合蒸馏策略,SANA-Sprint在一步内实现了7.59 FID和0.74 GenEval的最先进性能。SANA-Sprint仅需0.1秒即可在H100上生成高质量的1024x1024图像,在速度和质量的权衡方面树立了新的标杆。
在三维数字内容生产领域,三角形网格作为核心的几何表示形式,其质量直接影响虚拟资产在影视、游戏和工业设计等应用场景中的表现与效率。
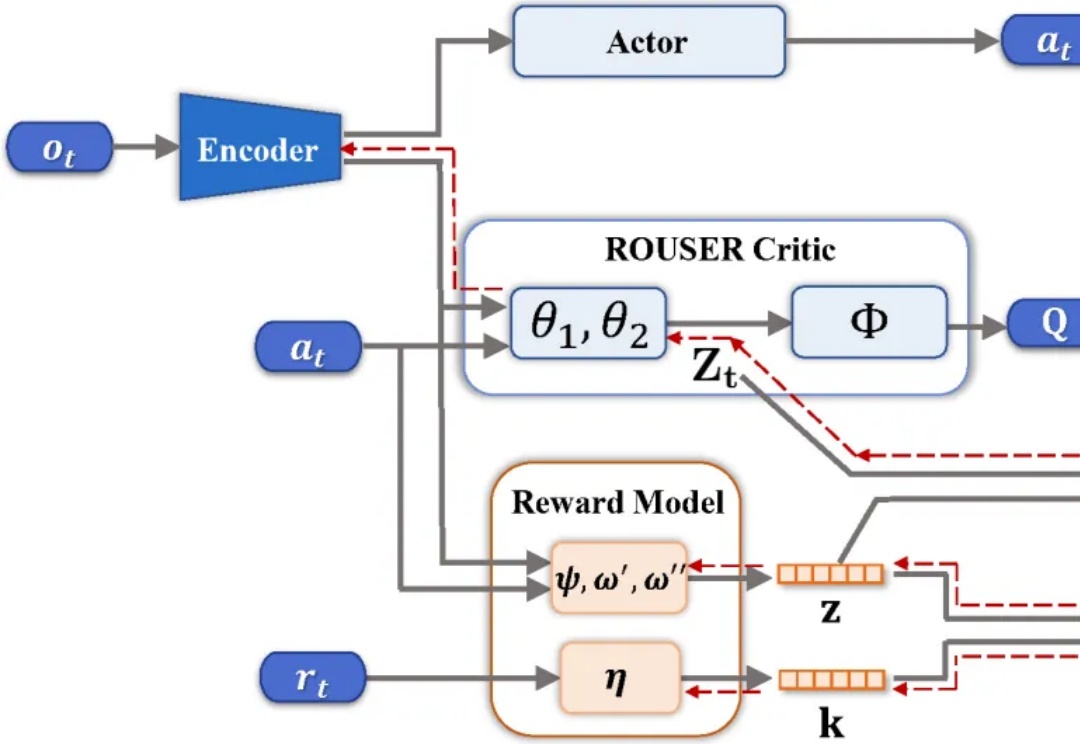
在视觉强化学习中,许多方法未考虑序列决策过程,导致所学表征缺乏关键的长期信息的空缺被填补上了。