
关于DeepSeek部署的一切,都在这里
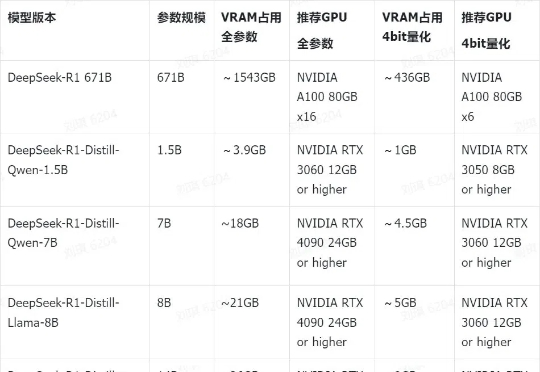
关于DeepSeek部署的一切,都在这里DeepSeek-R1及其蒸馏版本模型突破了AI Reasoning和大规模AI性能的新基准,其中DeepSeek-R1-Zero和DeepSeek-R1,已经在推理和问题求解上树立了新的标准。本次研究聚焦于如何利用已有的机器进行模型部署,使用这些先进的模型进行开发和研究。
来自主题: AI技术研报
9403 点击 2025-02-21 18:06
DeepSeek-R1及其蒸馏版本模型突破了AI Reasoning和大规模AI性能的新基准,其中DeepSeek-R1-Zero和DeepSeek-R1,已经在推理和问题求解上树立了新的标准。本次研究聚焦于如何利用已有的机器进行模型部署,使用这些先进的模型进行开发和研究。
过年这几天,DeepSeek 算是彻底破圈了,火遍大江南北,火到人尽皆知。虽然网络版和 APP 版已经足够好用,但把模型部署到本地,才能真正实现独家定制,让 DeepSeek R1 的深度思考「以你为主,为你所用」。

大家可能看到过很多类似的结论:针对特定任务,对开源模型进行 LoRA 微调可以干翻 GPT-4 这类闭源模型。

大语言模型(LLM)正在推动通信行业向智能化转型,在自动生成网络配置、优化网络管理和预测网络流量等方面展现出巨大潜力。未来,LLM在电信领域的应用将需要克服数据集构建、模型部署和提示工程等挑战,并探索多模态集成、增强机器学习算法和经济高效的模型压缩技术。
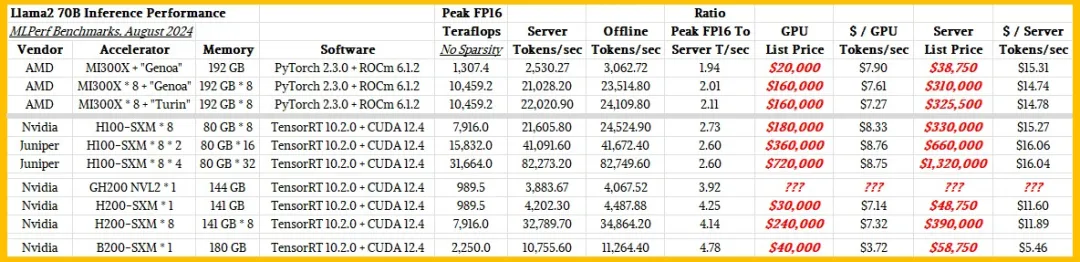
都很贵。

单卡搞定Llama 3.1(405B),最新大模型压缩工具来了!
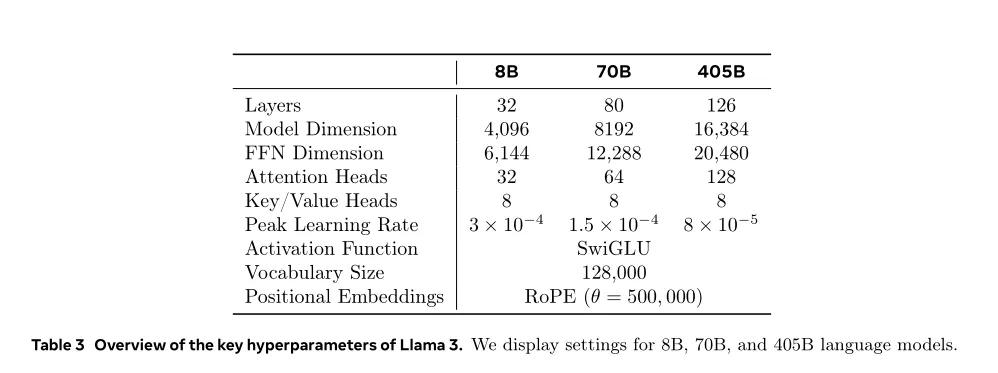
不同类型的数据配比如何配置:先通过小规模实验确定最优配比,然后将其应用到大模型的训练中。 Token配比结论:通用知识50%;数学与逻辑25%;代码17%;多语言8%。

千亿参数规模的大模型推理,服务器仅用4颗CPU就能实现!

英伟达NIM新升级,助力AI在多领域应用。
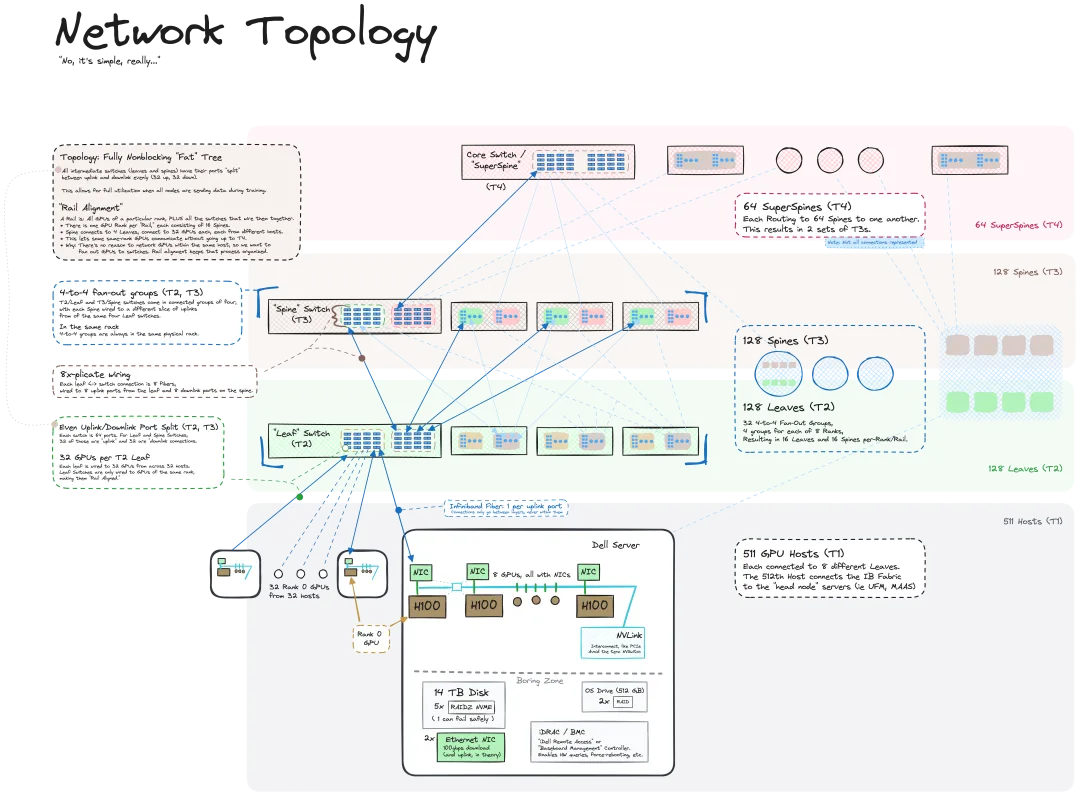
我们知道 LLM 是在大规模计算机集群上使用海量数据训练得到的,机器之心曾介绍过不少用于辅助和改进 LLM 训练流程的方法和技术。而今天,我们要分享的是一篇深入技术底层的文章,介绍如何将一堆连操作系统也没有的「裸机」变成用于训练 LLM 的计算机集群。