
Karpathy泼冷水:AGI要等10年!根本没有「智能体元年」
Karpathy泼冷水:AGI要等10年!根本没有「智能体元年」在近日的一次访谈中,Andrej Karpathy深入探讨了AGI、智能体与AI未来十年的走向。他认为当前的「智能体」仍处早期阶段,强化学习虽不完美,却是目前的最优解。他预测未来10年的AI架构仍然可能是类似Transformer的巨大神经网络。
来自主题: AI资讯
8711 点击 2025-10-19 12:48
 搜索
搜索
在近日的一次访谈中,Andrej Karpathy深入探讨了AGI、智能体与AI未来十年的走向。他认为当前的「智能体」仍处早期阶段,强化学习虽不完美,却是目前的最优解。他预测未来10年的AI架构仍然可能是类似Transformer的巨大神经网络。

噫吁嚱! 那个昔日叱咤风云的开源框架——TensorFlow,已然是行将就木了。

太夸张!百度办AI“培训班”,大佬都纷纷要来拜师学艺。 刚刚百度举办了首席AI架构师培养计划 (AICA)的第九期开学典礼,一看吓一跳,本期学员里可谓是卧虎藏龙。
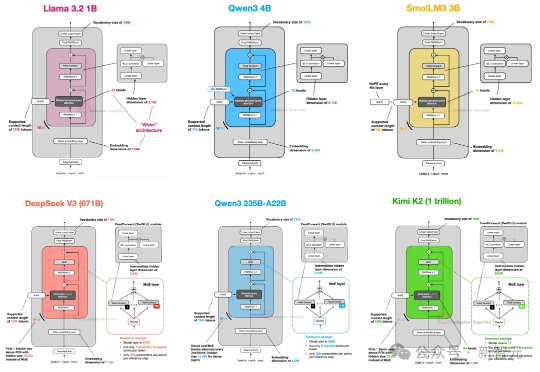
从GPT-2到DeepSeek-V3和Kimi K2,架构看似未变,却藏着哪些微妙升级?本文深入剖析2025年顶级开源模型的创新技术,揭示滑动窗口注意力、MoE和NoPE如何重塑效率与性能。
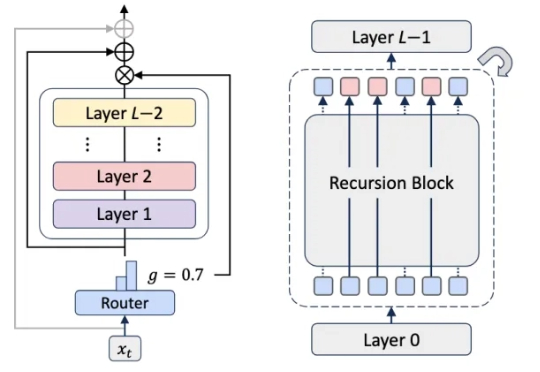
大型语言模型已展现出卓越的能力,但其部署仍面临巨大的计算与内存开销所带来的挑战。随着模型参数规模扩大至数千亿级别,训练和推理的成本变得高昂,阻碍了其在许多实际应用中的推广与落地。

未来AI路线图曝光!谷歌发明了Transformer,但在路线图中承认:现有注意力机制无法实现「无限上下文」,这意味着下一代AI架构,必须「从头重写」。Transformer的时代,真的要终结了吗?在未来,谷歌到底有何打算?

RNN太老,Transformer太慢?谷歌掀翻Transformer王座,用「注意力偏向+保留门」取代传统遗忘机制,重新定义了AI架构设计。全新模型Moneta、Yaad、Memora,在多个任务上全面超越Transformer。这一次,谷歌不是调参,而是换脑!
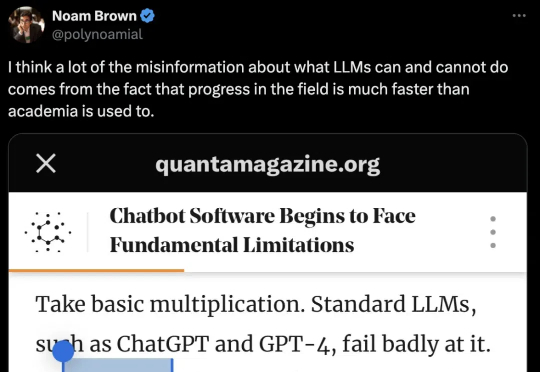
一篇报道,在AI圈掀起轩然大波。文中引用了近2年前的论文直击大模型死穴——Transformer触及天花板,却引来OpenAI研究科学家的紧急回应。谁能想到,一篇于2023年发表的LLM论文,竟然在一年半之后又「火」了。

Meta 的首席 AI 科学家 Yann LeCun 表示,在未来三到五年内将出现一种“新的 AI 架构范式”,远远超出现有 AI 系统的能力。LeCun 还预测,未来几年可能是“机器人时代”,人工智能和机器人技术的进步将结合起来,开启一类新的智能应用。

Sakana AI发布了Transformer²新方法,通过奇异值微调和权重自适应策略,提高了LLM的泛化和自适应能力。新方法在文本任务上优于LoRA;即便是从未见过的任务,比如MATH、HumanEval和ARC-Challenge等,性能也都取得了提升。