单卡2秒生成一个视频!清华联手生数开源TurboDiffusion,视频DeepSeek时刻来了
单卡2秒生成一个视频!清华联手生数开源TurboDiffusion,视频DeepSeek时刻来了现在生成一个视频,比你刷视频还要快。
来自主题: AI技术研报
8408 点击 2025-12-26 10:58
 搜索
搜索
现在生成一个视频,比你刷视频还要快。

视频生成领域的「DeepSeek时刻」来了!清华开源TurboDiffusion,将AI视频生成从「分钟级」硬生生拉进「秒级」实时时代,单卡200倍加速让普通显卡也能跑出大片!

浙江大学ReLER团队开源ContextGen框架,攻克多实例图像生成中布局与身份协同控制难题。基于Diffusion Transformer架构,通过双重注意力机制,实现布局精准锚定与身份高保真隔离,在基准测试中超越开源SOTA模型,对标GPT-4o等闭源系统,为定制化AI图像生成带来新突破。

过去三年,扩散模型席卷图像生成领域。以 DiT (Diffusion Transformer) 为代表的新一代架构不断刷新图像质量的极限,让模型愈发接近真实世界的视觉规律。

扩散语言模型(Diffusion Language Models)以其独特的 “全局规划” 与并行解码能力广为人知,成为 LLM 领域的全新范式之一。然而在 Any-order 解码模式下,其通常面临

REG 是一种简单而有效的方法,仅通过引入一个 class token 便能大幅加速生成模型的训练收敛。其将基础视觉模型(如 DINOv2)的 class token 与 latent 在空间维度拼接后共同加噪训练,从而显著提升 Diffusion 的收敛速度与性能上限。在 ImageNet 256×256 上,

扩散概率生成模型(Diffusion Models)已成为AIGC时代的重要基础,但其推理速度慢、训练与推理之间的差异大,以及优化困难,始终是制约其广泛应用的关键问题。近日,被NeurIPS 2025接收的一篇重磅论文EVODiff给出了全新解法:来自华南理工大学曾德炉教授「统计推断,数据科学与人工智能」研究团队跳出了传统的数值求解思维,首次从信息感知的推理视角,将去噪过程重构为实时熵减优化问题。
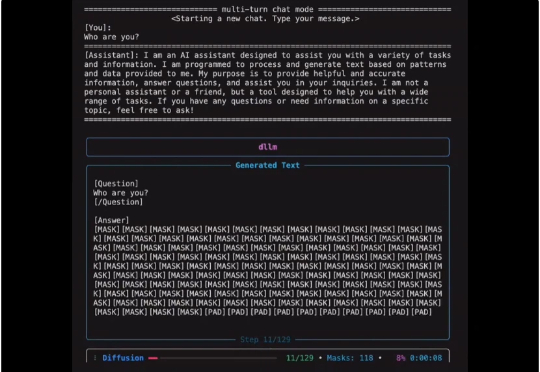
扩散式语言模型(Diffusion Language Model, DLM)虽近期受关注,但社区长期受限于(1)缺乏易用开发框架与(2)高昂训练成本,导致多数 DLM 难以在合理预算下复现,初学者也难以真正理解其训练与生成机制。

就在一周前,全宇宙最火爆的推理框架 SGLang 官宣支持了 Diffusion 模型,好评如潮。团队成员将原本在大语言模型推理中表现突出的高性能调度与内核优化,扩展到图像与视频扩散模型上,相较于先前的视频和图像生成框架,速度提升最高可达 57%:
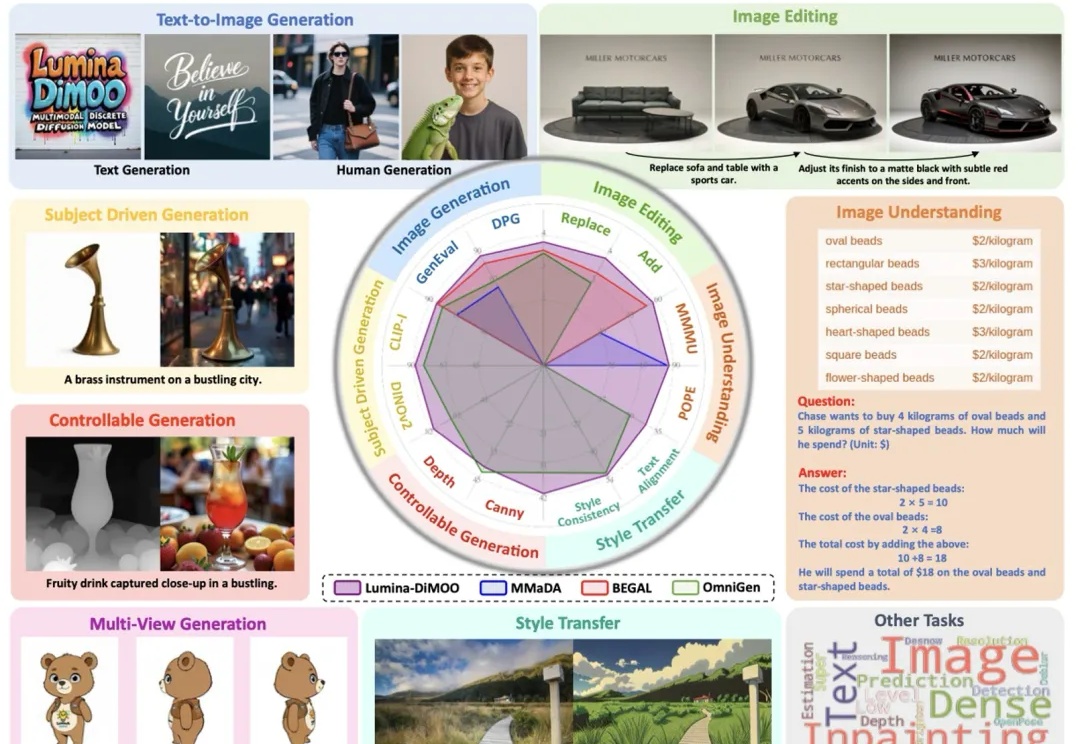
上海人工智能实验室推出了一款革新的多模态生成理解一体化的扩散语言模型 ——Lumina-DiMOO。基于离散扩散建模(Discrete Diffusion Modeling),Lumina-DiMOO 打破了多模态任务之间的壁垒,在同一离散扩散框架下,完成从 文本→图像、图像→图像、图像→文本的全栈能力闭环。