
让模型部署像调用API一样简单!1小时轻松完成超100个微调模型部署的神器来了,按量计费每月立省10万
让模型部署像调用API一样简单!1小时轻松完成超100个微调模型部署的神器来了,按量计费每月立省10万大家可能看到过很多类似的结论:针对特定任务,对开源模型进行 LoRA 微调可以干翻 GPT-4 这类闭源模型。
来自主题: AI资讯
9378 点击 2025-01-09 09:37
 搜索
搜索
大家可能看到过很多类似的结论:针对特定任务,对开源模型进行 LoRA 微调可以干翻 GPT-4 这类闭源模型。

自回归文生图,迎来新王者——
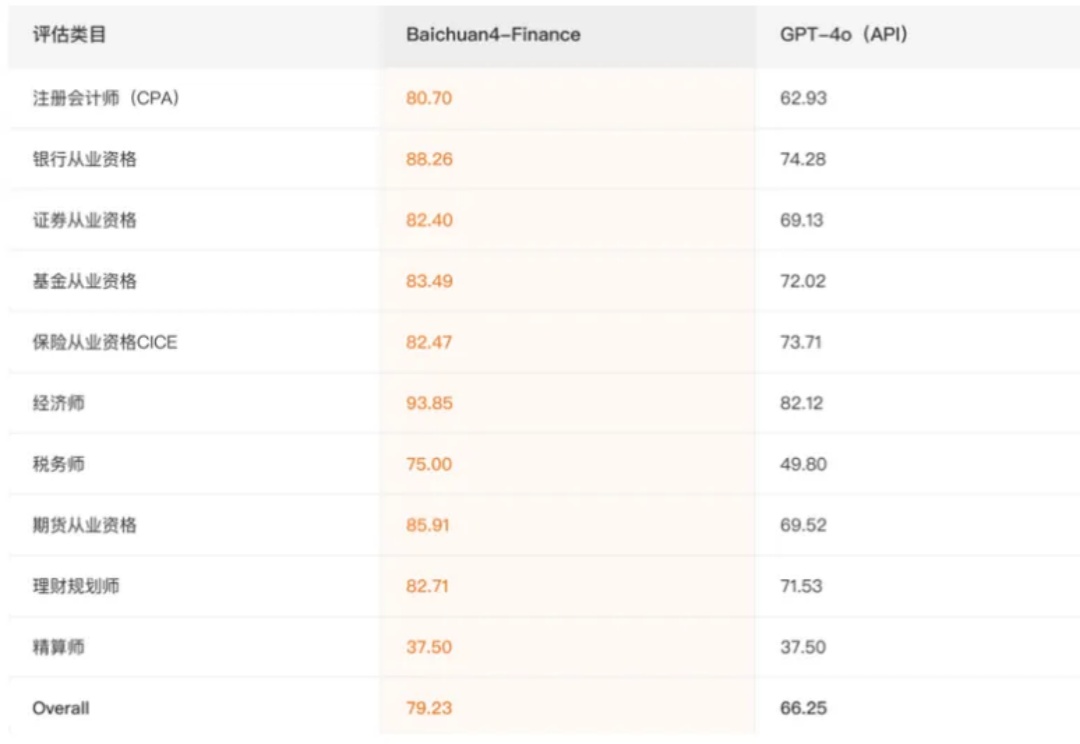
大模型的竞速赛,正站在通用底座的基础上,掀起“领域增强”风暴。
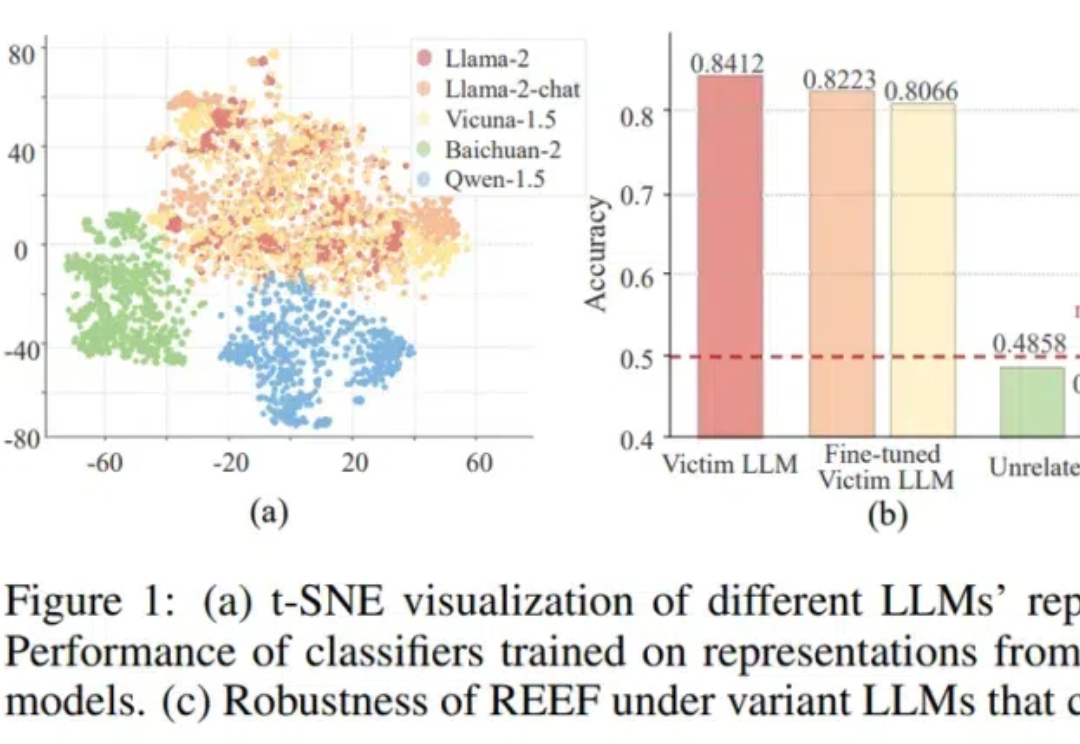
大模型“套壳”事件防不胜防,有没有方法可以检测套壳行为呢? 来自上海AI实验室、中科院、人大和上交大的学者们,提出了一种大模型的“指纹识别”方法——REEF(Representation Encoding Fingerprints)。
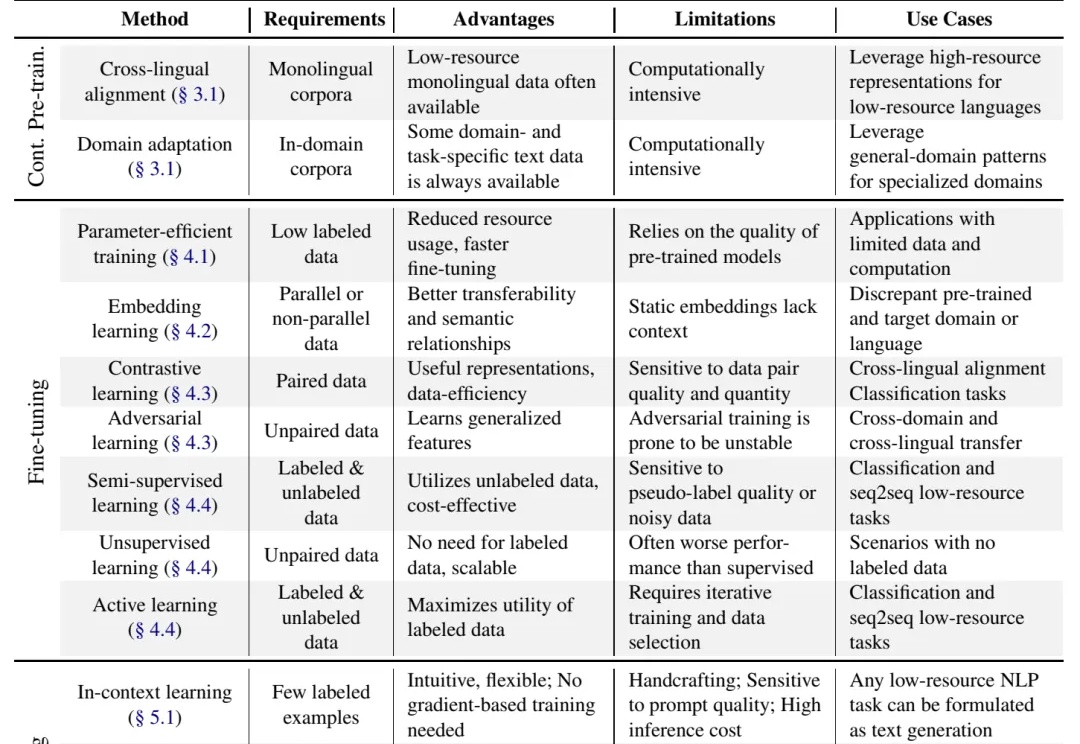
别说什么“没数据就去标注啊,没钱标注就别做大模型啊”这种风凉话,有些人数据不足也能做大模型,是因为有野心,就能想出来稀缺数据场景下的大模型解决方案,或者整理出本文将要介绍的 "Practical Guide to Fine-tuning with Limited Data" 这样的综述。

2024 年 12 月 6 号加州时间上午 11 点,OpenAI 发布了新的 Reinforcement Finetuning 方法,用于构造专家模型。对于特定领域的决策问题,比如医疗诊断、罕见病诊断等等,只需要上传几十到几千条训练案例,就可以通过微调来找到最有的决策。

OpenAI“双12”直播第二天,依旧简短精悍,主题:新功能强化微调(Reinforcement Fine-Tuning),使用极少训练数据即在特定领域轻松地创建专家模型。少到什么程度呢?最低几十个例子就可以。
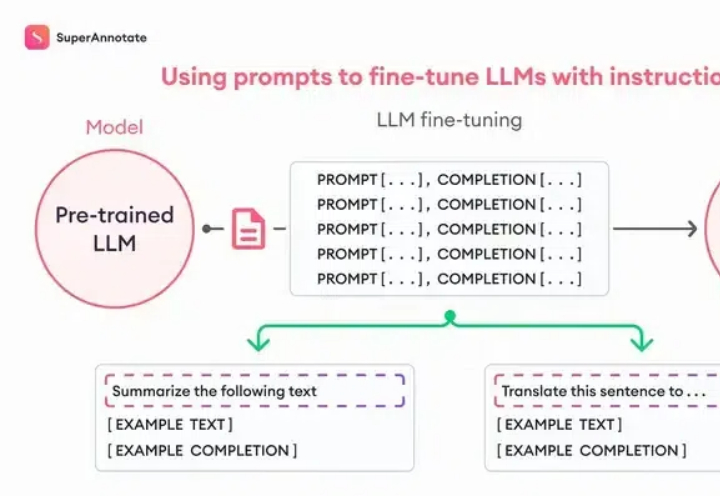
Fine-tuning理论上很复杂,但是OpenAI把这个功能完善到任何一个人看了就能做出来的程度。我们先从原理入手,你看这张图,左边是Pre-trained LLM (预训练大模型模型),也就是像ChatGPT这样的模型;右边是Fine-tuned LLM (微调过的语言大模型),中间就是进行微调的过程,它需要我们提供一些「ChatGPT提供不了但是我们需要的东西」。

这是一个不容小觑的最新推理框架,它解耦了LLM的记忆与推理,用此框架Fine-tuned过的LLaMa-3.1-8B在TruthfulQA数据集上首次超越了GPT-4o。
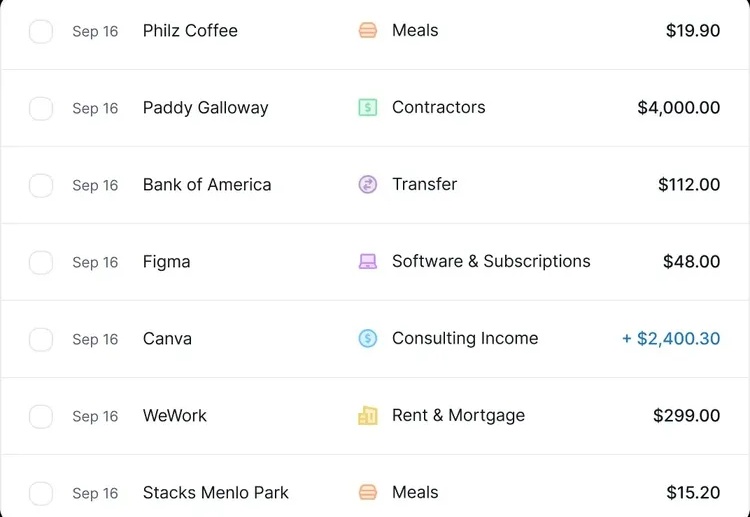
上月,一家名叫Kick的硅谷AI记账自动化公司宣布完成900万美元种子轮融资。尽管AI/FinTech领域一直是热门吸金板块,但Kick因其特殊的融资背景格外引人注目,因为它是OpenAI Startup Fund最早期的投资组合之一。