
揭秘小扎AI雄心:立志将Llama 3打造成行业新标杆,要做AI界的丰田
揭秘小扎AI雄心:立志将Llama 3打造成行业新标杆,要做AI界的丰田Meta加强推广Llama模型,谋求AI市场领导
来自主题: AI资讯
8539 点击 2024-08-23 10:10
 搜索
搜索
Meta加强推广Llama模型,谋求AI市场领导
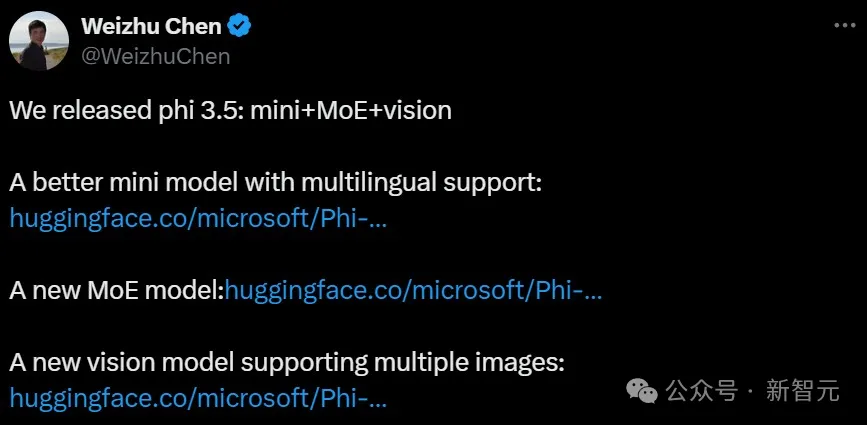
微软Phi 3.5系列上新了!mini模型小而更美,MoE模型首次亮相,vision模型专注多模态。
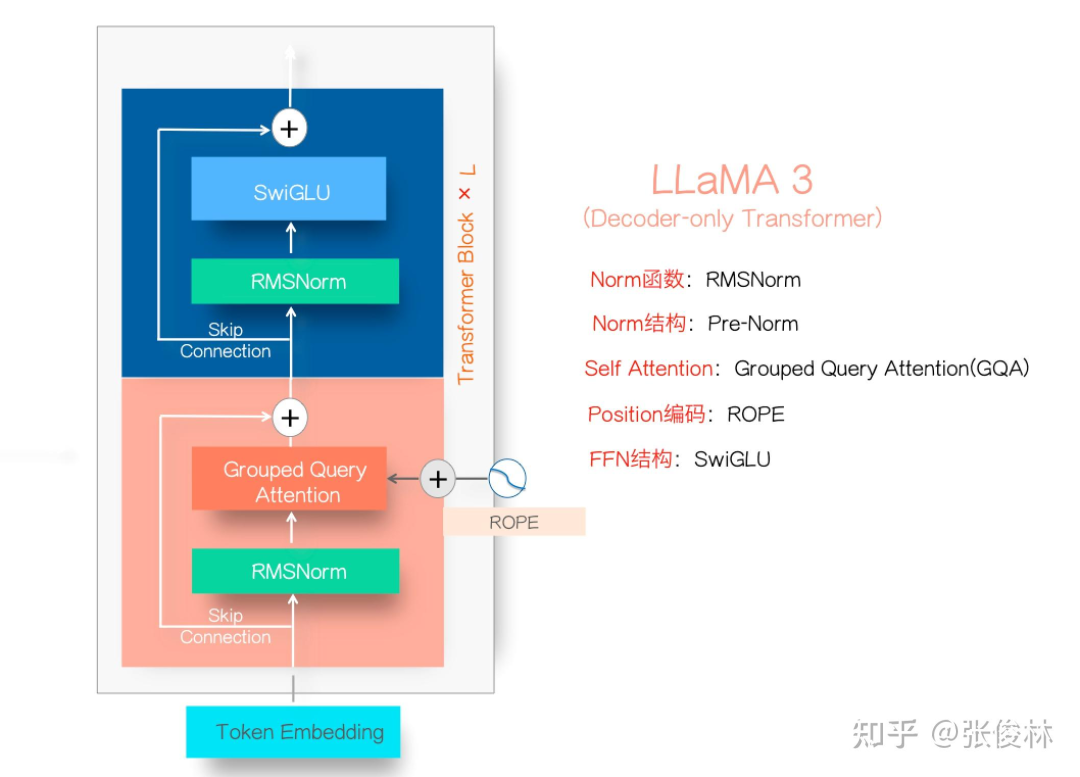
Llama3.1系列模型的开源,真让大模型格局大震,指标上堪比最好的闭源模型比如GPT 4o和Claude3.5,让开源追赶闭源成为现实。
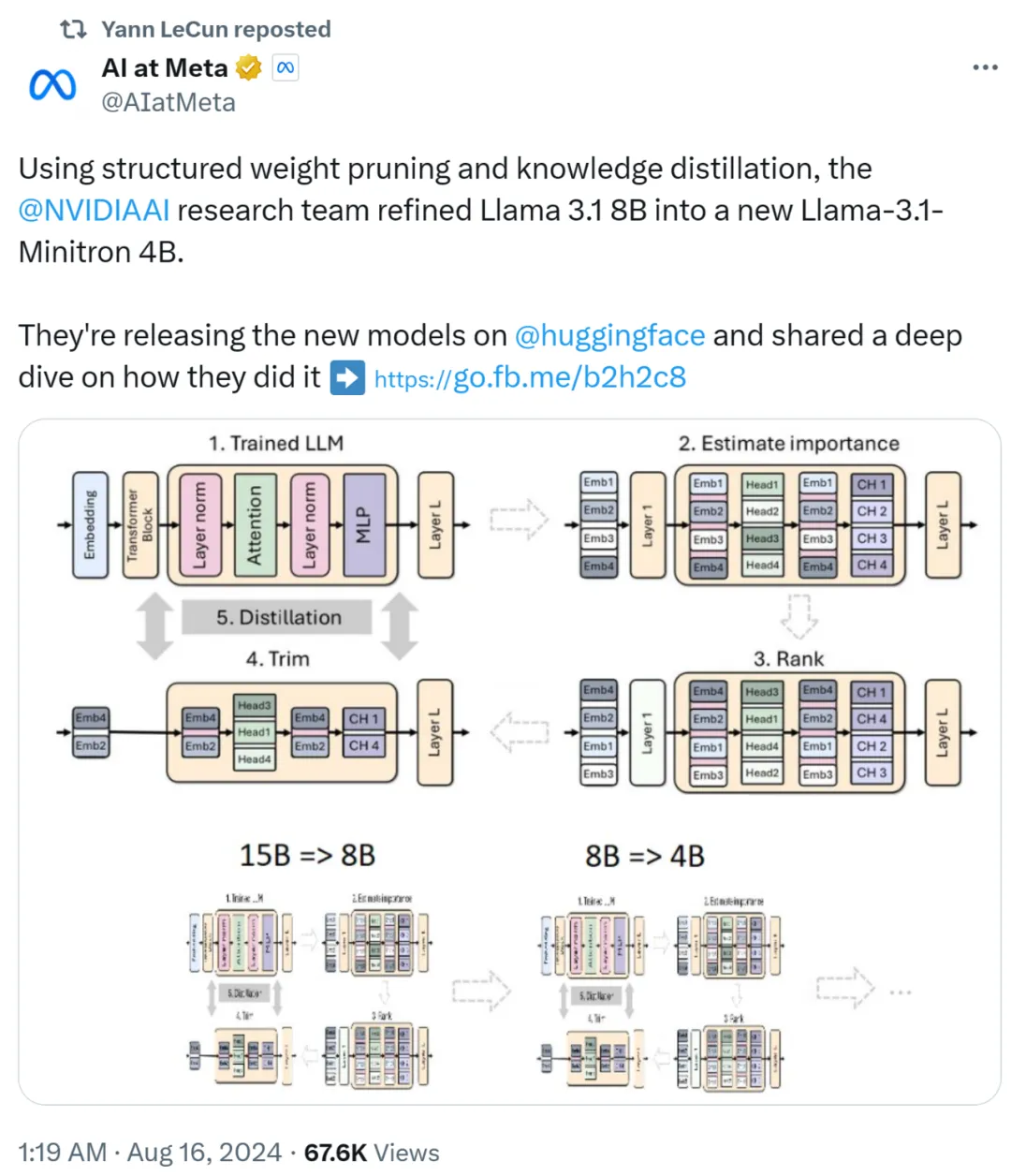
小模型崛起了。

发布40天后,最强开源模型Llama 3.1 405B等来了微调版本的发布。但不是来自Meta,而是一个专注于开放模型的神秘初创Nous Research。
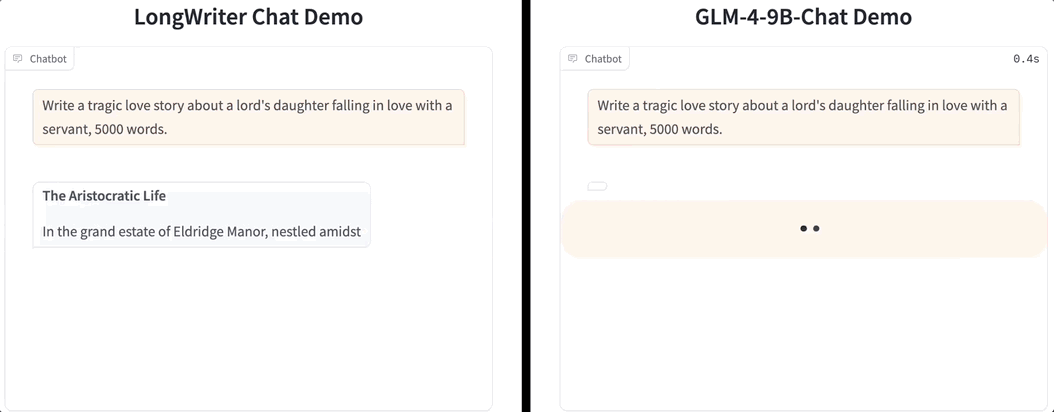
一口气生成2万字,大模型输出也卷起来了!

最近的论文表明,LLM等生成模型可以通过搜索来扩展,并实现非常显著的性能提升。另一个复现实验也发现,让参数量仅8B的Llama 3.1模型搜索100次,即可在Python代码生成任务上达到GPT-4o同等水平。

没有等来OpenAI的Q*/草莓项目的发布,一家名为MultiOn初创公司却抢先发布了名为Q的智能体。

Mamba 架构的大模型又一次向 Transformer 发起了挑战

T-MAC是一种创新的基于查找表(LUT)的方法,专为在CPU上高效执行低比特大型语言模型(LLMs)推理而设计,无需权重反量化,支持混合精度矩阵乘法(mpGEMM),显著降低了推理开销并提升了计算速度。