Llama 4在测试集上训练?内部员工、官方下场澄清,LeCun转发
Llama 4在测试集上训练?内部员工、官方下场澄清,LeCun转发大家翘首以盼的 Llama 4,用起来为什么那么拉跨?
来自主题: AI资讯
6801 点击 2025-04-08 15:25
 搜索
搜索
大家翘首以盼的 Llama 4,用起来为什么那么拉跨?

今日凌晨,Meta AI 部门副总裁 Ahmad Al-Dahle 发文,回应了近日发布的 Llama 4 大模型的争议问题:对于「不同服务中模型质量参差不齐」这一问题,Ahmad Al-Dahle 解释称,由于模型一准备好就发布了,所以 Meta 的团队预计所有公开的应用实现都需要几天时间来进行优化调整,团队后续会继续进行漏洞修复工作。

Meta最新基础模型Llama 4发布36小时后,评论区居然是这个画风:

Llama 4本该是AI圈的焦点,却成了大型翻车现场。开源首日,全网实测代码能力崩盘。更让人震惊的是,模型训练测试集被曝作弊,内部员工直接请辞。

今天在各大信息渠道看到 Llama4 发布的消息,一上来就放出三个模型,具体能力这里就不在赘述,相信大家已经多少看到不少介绍了。
Llama 4家族周末突袭,实属意外。这场AI领域的「闪电战」不仅带来了两款全新架构的开源模型,更揭示了一个惊人事实:苹果Mac设备或将成为部署大型AI模型的「性价比之王」。
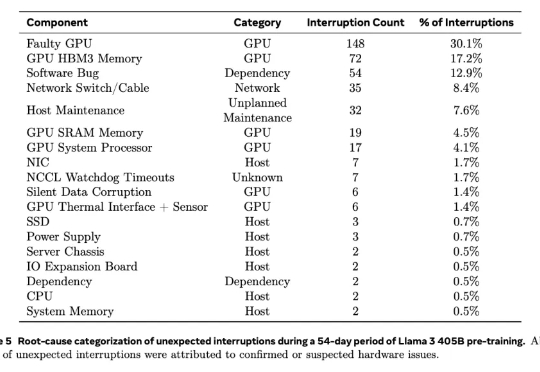
根据去年2024年7月28日Meta公司在训练大模型(Llama 3)时使用“16384 个 英伟达H100 GPU 集群”的经验,该显卡在高负载、大规模集群运行环境下容易出现以下故障点:

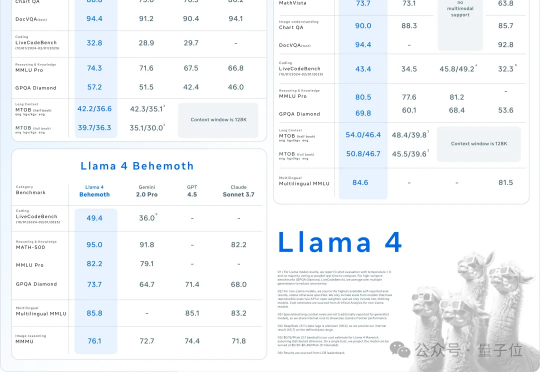
原生多模态Llama 4终于问世,开源王座一夜易主!首批共有两款模型Scout和Maverick,前者业界首款支持1000万上下文单H100可跑,后者更是一举击败了DeepSeek V3。目前,2万亿参数巨兽还在训练中。
AI不过周末,硅谷也是如此。大周日的,Llama家族上新,一群LIama 4就这么突然发布了。这是Meta首个基于MoE架构模型系列,目前共有三个款:Llama 4 Scout、Llama 4 Maverick、Llama 4 Behemoth。

刚刚,奥特曼接连抛出重磅消息:GPT-5不仅将免费开放,还将整合多项尖端技术。o3和o4-mini即将在几周内亮相,还有一个神秘的开源推理模型要来。然而,另一边Meta的Llama 4却因性能瓶颈屡次延期,AI竞赛的格局愈发扑朔迷离。