
Transformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transformer 也因此难以处理非常长的文本。
来自主题: AI技术研报
6830 点击 2024-08-31 14:54
 搜索
搜索
Transformer 在深度学习领域取得巨大成功的关键是注意力机制。注意力机制让基于 Transformer 的模型关注与输入序列相关的部分,实现了更好的上下文理解。然而,注意力机制的缺点是计算开销大,会随输入规模而二次增长,Transformer 也因此难以处理非常长的文本。

Meta的开源大模型Llama 3在市场上遇冷,进一步加剧了大模型开源与闭源之争的关注热度。
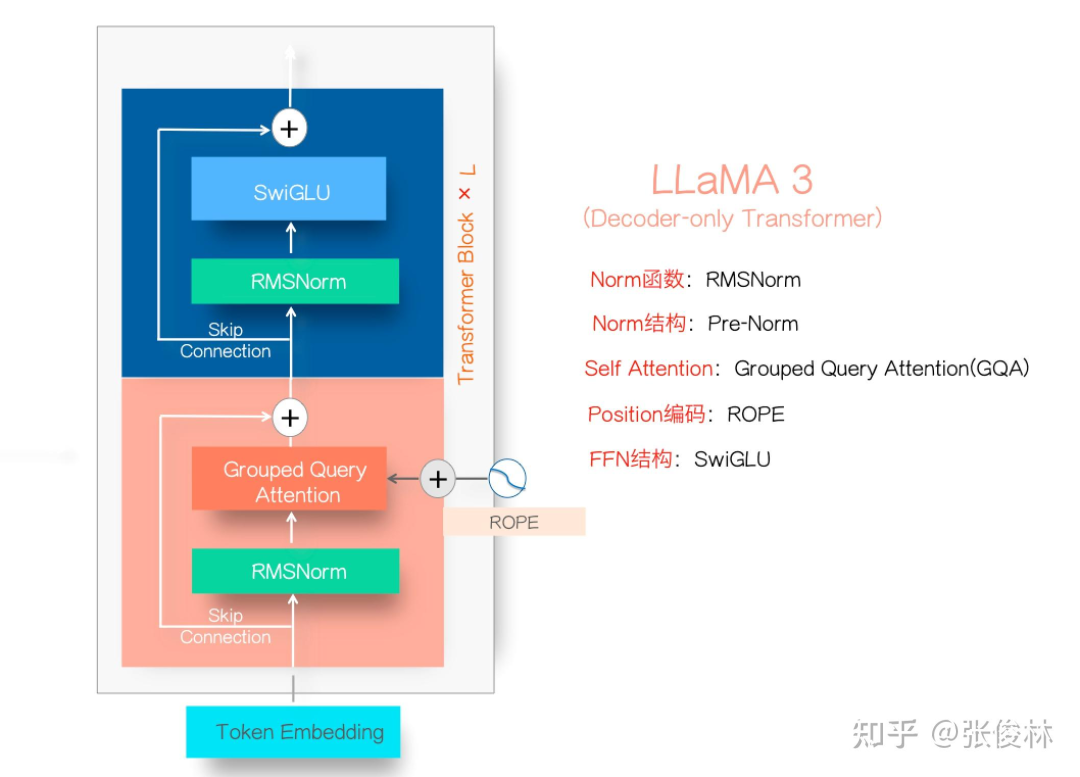
Llama3.1系列模型的开源,真让大模型格局大震,指标上堪比最好的闭源模型比如GPT 4o和Claude3.5,让开源追赶闭源成为现实。

把Llama 3.1 405B和Claude 3超大杯Opus双双送进小黑屋,你猜怎么着——

伴随大模型迭代速度越来越快,训练集群规模越来越大,高频率的软硬件故障已经成为阻碍训练效率进一步提高的痛点,检查点(Checkpoint)系统在训练过程中负责状态的存储和恢复,已经成为克服训练故障、保障训练进度和提高训练效率的关键。

不同类型的数据配比如何配置:先通过小规模实验确定最优配比,然后将其应用到大模型的训练中。 Token配比结论:通用知识50%;数学与逻辑25%;代码17%;多语言8%。

每3个小时1次、平均1天8次,Llama 3.1 405B预训练老出故障,H100是罪魁祸首?

芯片巨头英伟达,在AI时代一直被类比为在淘金热中“卖铲子”的背后赢家。

继分不清9.11和9.9哪个大以后,大模型又“集体失智”了!

评估大模型是否诚实的基准来了!