

融资6亿美元!诺奖得主创办的Isomorphic Labs高管:五年后,不借助AI就无法设计出药物
融资6亿美元!诺奖得主创办的Isomorphic Labs高管:五年后,不借助AI就无法设计出药物2020年AlphaFold2横空出世横扫CASP14,彻底改变了AI+生物学。
来自主题: AI资讯
9665 点击 2025-05-06 11:00
2020年AlphaFold2横空出世横扫CASP14,彻底改变了AI+生物学。
神奇!人类和海豚真的能实现跨物种交流了?!

3月31日,AI制药公司Isomorphic Labs宣布在第一次外部融资中筹集了6亿美元,由Thrive Capital领投,GV参投,现有投资者谷歌母公司Alphabet跟投。Isomorphic Labs成立于2021年,创始人兼CEO为2024年诺贝尔化学奖得主Demis Hassabis,其使命是运用AI治疗所有疾病。

科技圈再掀波澜,一家名为Graphite的纽约人工智能初创公司,正式名称为Screenplay Studios Inc.,今日宣布成功斩获高达5200万美元的B轮融资,为这家专注于颠覆传统代码审查模式的新星注入了强劲动力。
Phi-4系列模型上新了!56亿参数Phi-4-multimodal集语音、视觉、文本多模态于一体,读图推理性能碾压GPT-4o;另一款38亿参数Phi-4-mini在推理、数学、编程等任务中超越了参数更大的LLM,支持128K token上下文。
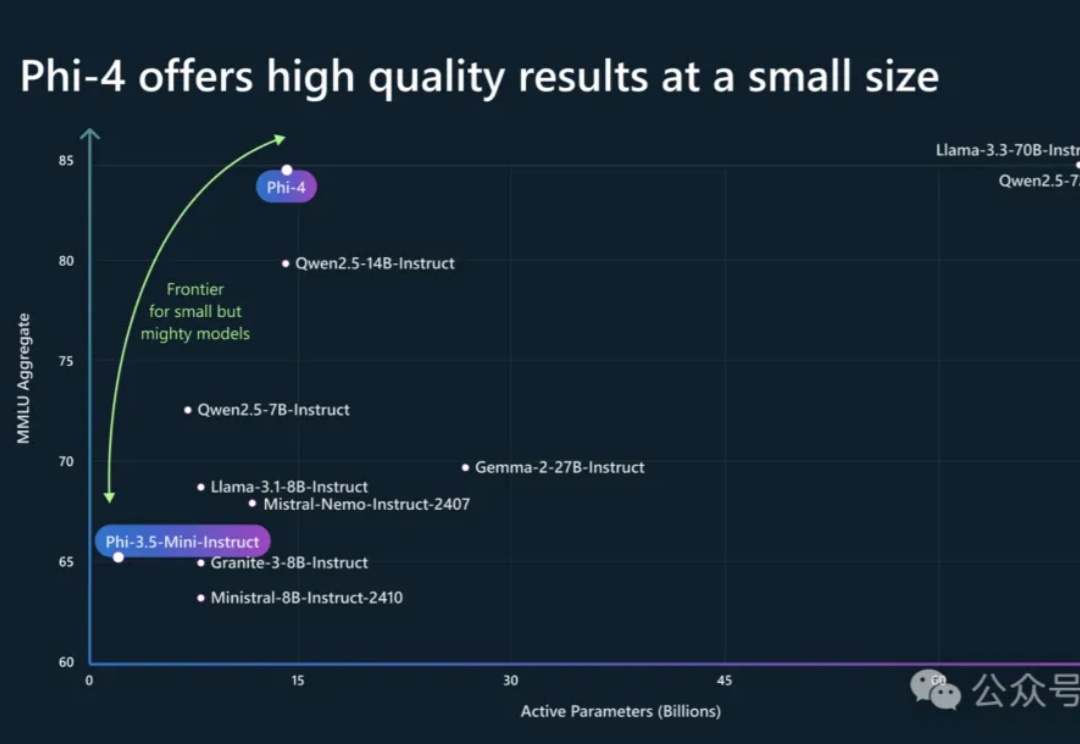
动辄百亿、千亿参数的大模型正在一路狂奔,但「小而美」的模型也在闪闪发光。
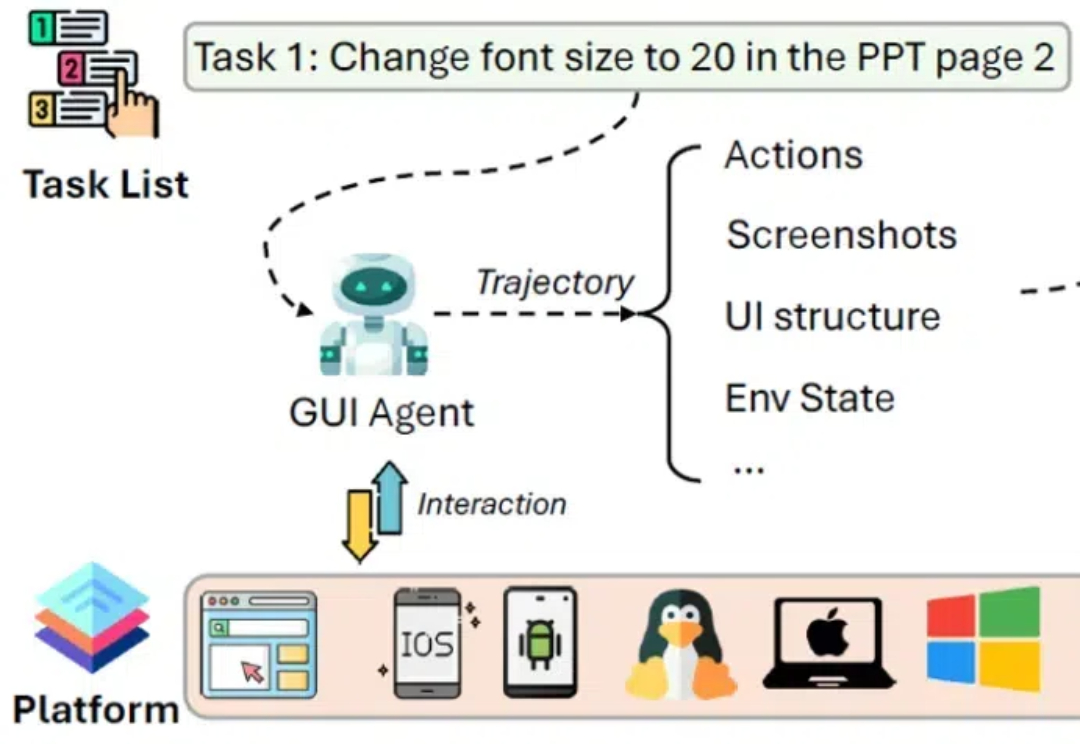
图形用户界面(Graphical User Interface, GUI)作为数字时代最具代表性的创新之一,大幅简化了人机交互的复杂度。

你是否想过在自己的设备上运行自己的大型语言模型(LLMs)或视觉语言模型(VLMs)?你可能有过这样的想法,但是一想到要从头开始设置、管理环境、下载正确的模型权重,以及你的设备是否能处理这些模型的不确定性,你可能就犹豫了。
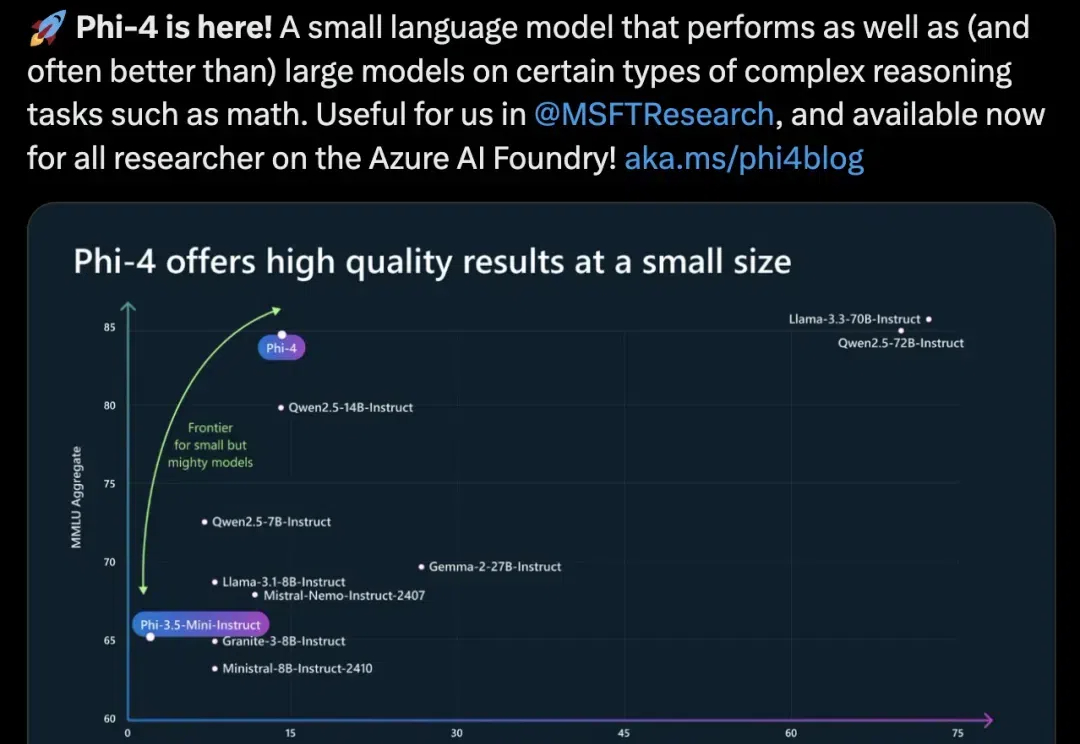
微软下一代14B小模型Phi-4出世了!仅用了40%合成数据,在数学性能上击败了GPT-4o,最新36页技术报告出炉。
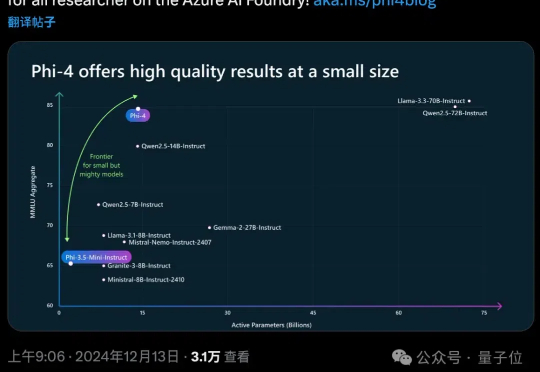
OpenAI谷歌天天刷流量,微软也坐不住了,推出最新小模型Phi-4。 参数量仅14B,MMLU性能就和Llama 3.3/ Qwen2.5等70B级别大模型坐一桌。