
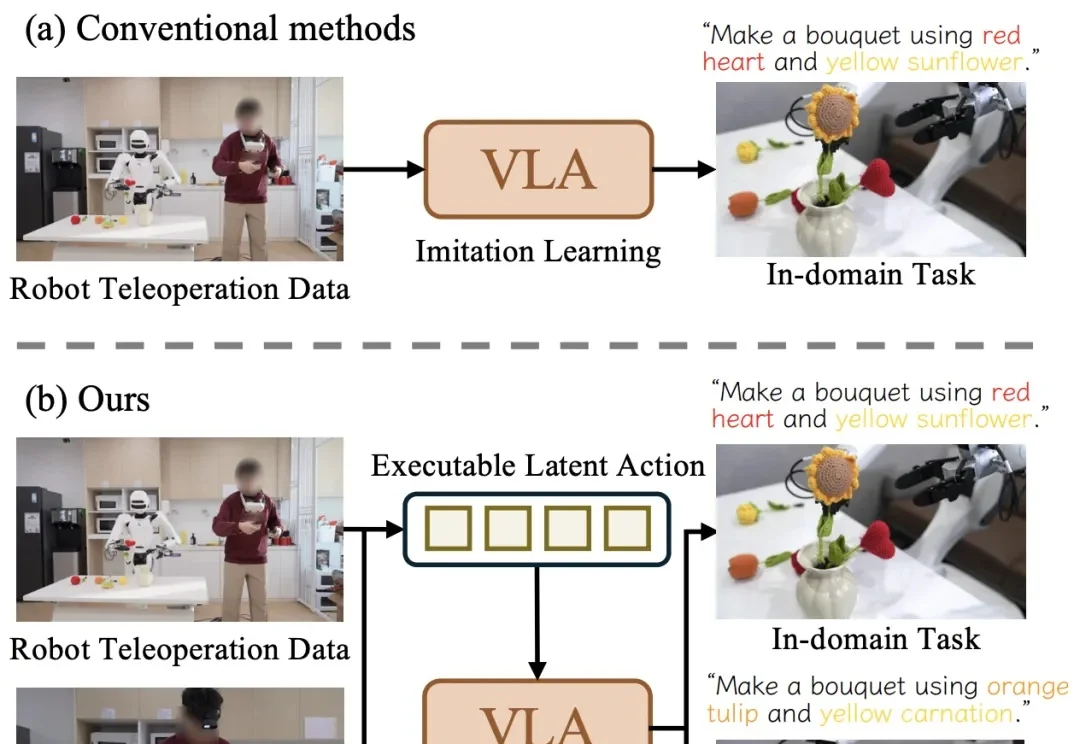
让机器人看视频学操作技能,清华等全新发布的CLAP框架做到了
让机器人看视频学操作技能,清华等全新发布的CLAP框架做到了近日,清华大学与星尘智能、港大、MIT 联合提出基于对比学习的隐空间动作预训练(Contrastive Latent Action Pretraining, CLAP)框架。这个框架能够将视频中提纯的运动空间与机器人的动作空间进行对齐,也就是说,机器人能够直接从视频中学习技能!
来自主题: AI技术研报
7139 点击 2026-01-19 15:13
近日,清华大学与星尘智能、港大、MIT 联合提出基于对比学习的隐空间动作预训练(Contrastive Latent Action Pretraining, CLAP)框架。这个框架能够将视频中提纯的运动空间与机器人的动作空间进行对齐,也就是说,机器人能够直接从视频中学习技能!
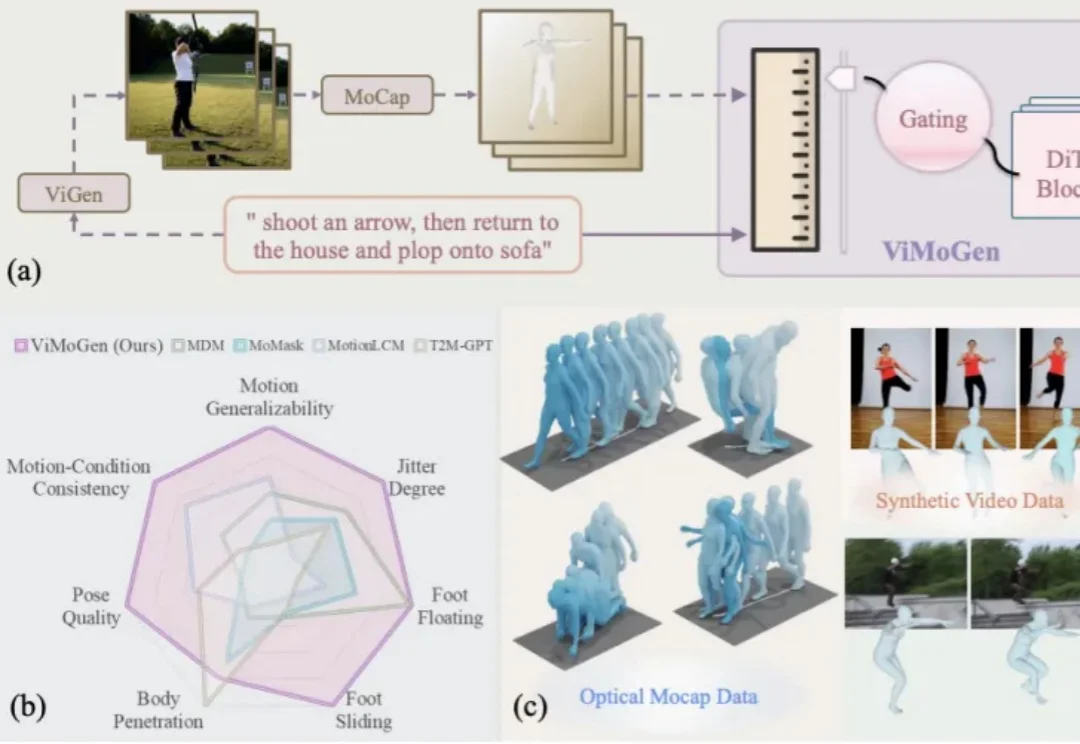
随着 AIGC(Artificial Intelligence Generated Content) 的爆发,我们已经习惯了像 Sora 或 Wan 这样的视频生成模型能够理解「一只宇航员在火星后空翻」这样天马行空的指令。然而,3D 人体动作生成(3D MoGen)领域却稍显滞后。

月前,Pollo.ai 拿下千万美元融资,而今日, ListenHub 也拿下了 200 万美元融资。两个产品都没有做自研模型,创始人也都不是典型的技术或者大厂出身,都是非典型的 AI 应用层创业,这个在 2024年“质疑”声很大的模式,在 2025 年却结出了不少的果实。
据我们独家获悉,ListenHub产品的母公司MarsWave完成了200万美元天使+轮融资。本轮由天际资本领投,小米联合创始人王川跟投。同时,MarsWave也对外公布了盈利状况:目前公司年经常性收入(ARR)已突破300万美元,并达到月度盈亏平衡,成为少数已跑通盈利模型的AI原生公司。
能翻译33语种+5方言,医学术语/粤语翻译实测“能打”。

Content in,Design out。
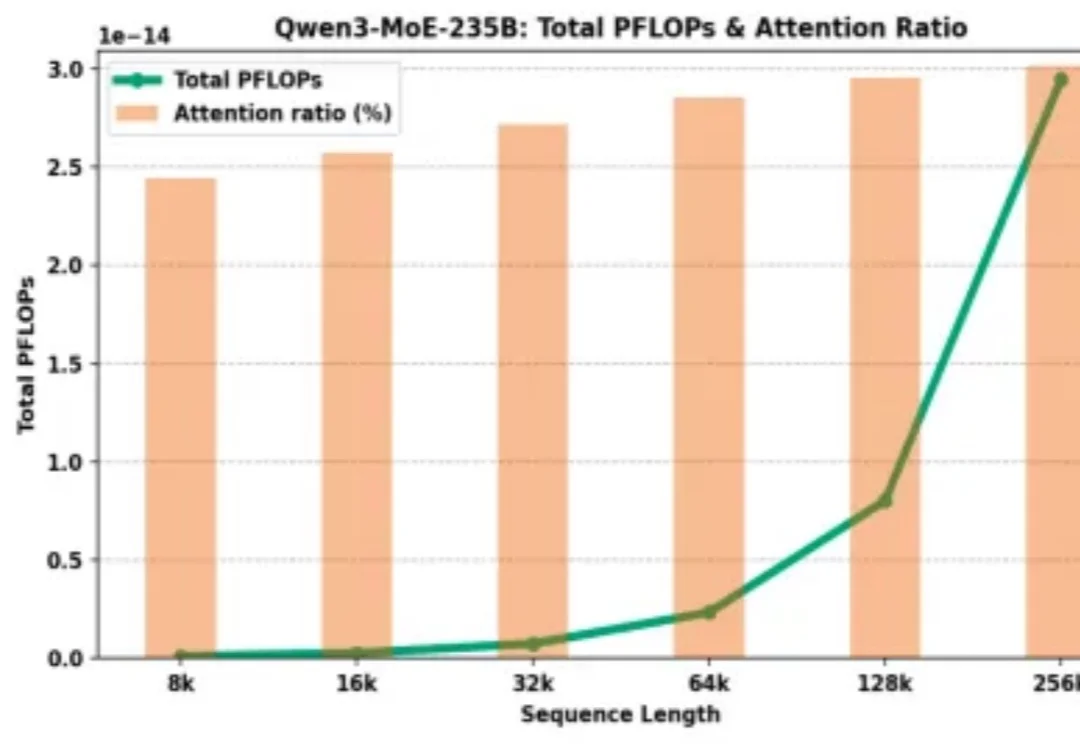
为什么大模型厂商给了 128K 的上下文窗口,却在计费上让长文本显著更贵?
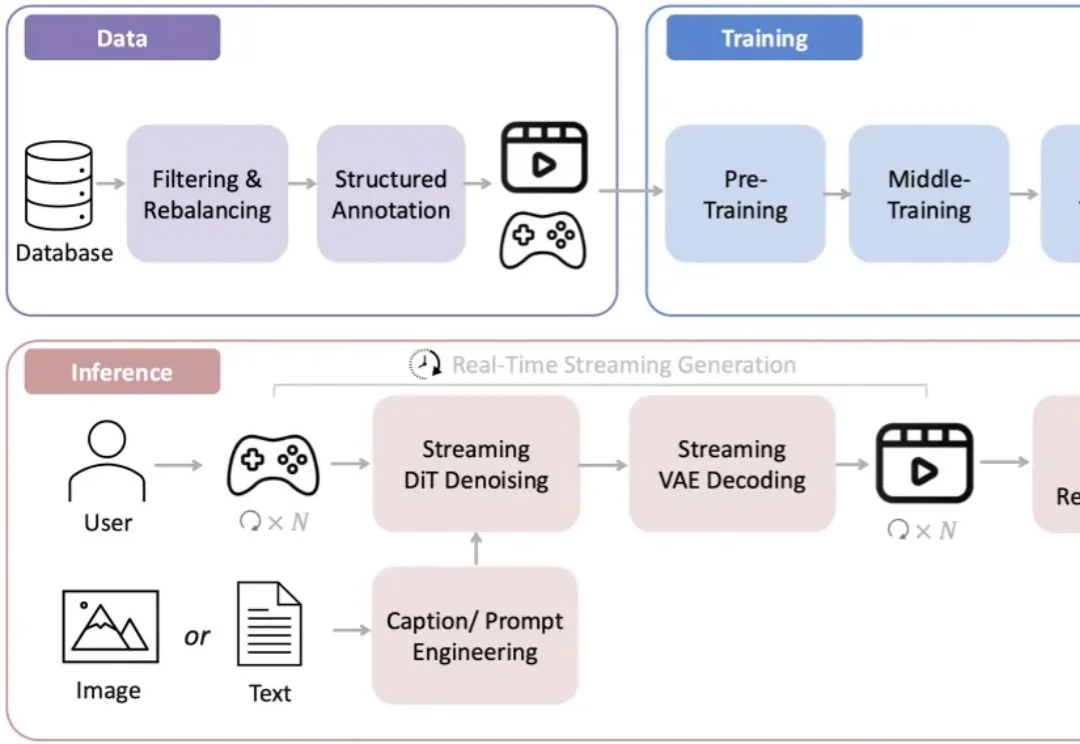
还记得前段时间在 AI 圈刷屏的李飞飞「3D 世界生成模型」吗?现在,国产版终于来了。
可支持24帧/秒的长时流式生成。

提起马卡龙,你会想到什么?是橱窗里的精致甜点,一种“少女心”的味觉象征?还是代表了温柔优雅的时尚配色?当一个AI产品也被命名为“马卡龙”,这份联想便悄然发生了偏移:从舌尖的甜,转向科技的未知,却又奇妙地保留了那一份色彩与气质。