谷歌24亿美元买个壳?刚发布的“下一代AI IDE”被爆“复制”Windsurf,连Bug一起
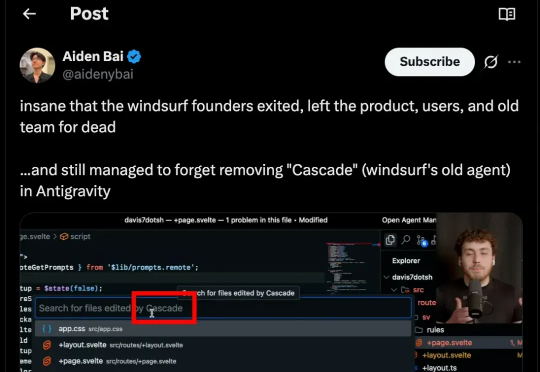
谷歌24亿美元买个壳?刚发布的“下一代AI IDE”被爆“复制”Windsurf,连Bug一起Google 前天发布了 Antigravity,一款号称“下一代 agentic 开发平台”的全新 IDE。官方宣传强调它能规划、执行、验证整个开发流程,似乎代表着 AI 编程进入了新的阶段。然而,最早一批上手使用的开发者却纷纷吐槽:任务跑着跑着就因“模型过载”中断,信用额度几十分钟内耗尽,连完整测试都难以完成,体验堪称“开局即崩”。
来自主题: AI资讯
9849 点击 2025-11-29 10:52