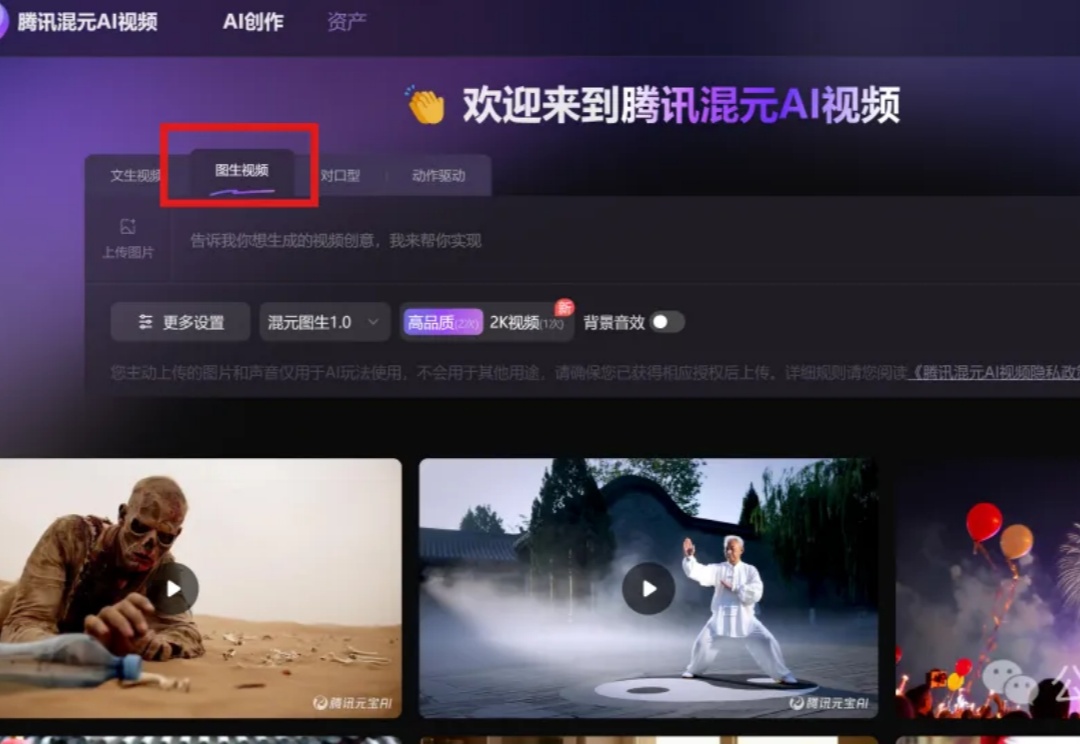
腾讯图生视频全面开源,更懂物理规律,一手实测来了
腾讯图生视频全面开源,更懂物理规律,一手实测来了就在刚刚,腾讯版Sora补齐了又一重要拼图——图生视频。
来自主题: AI资讯
9896 点击 2025-03-07 12:46
 搜索
搜索
就在刚刚,腾讯版Sora补齐了又一重要拼图——图生视频。
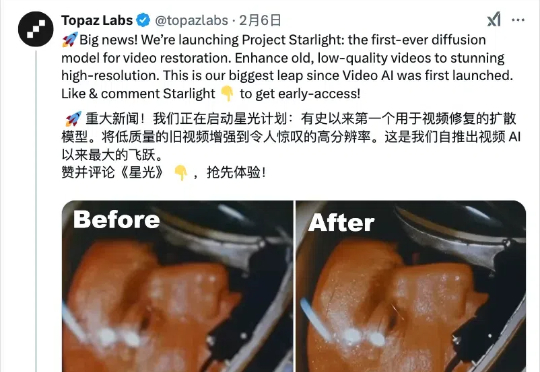
经常有群友问我有没有什么把视频修复的工具。而我过去最推荐的,也是我心中目前最牛逼的视频修复工具,自然就是TopazVideoAI了。但,斗转星移,日月如梭,现在已经2025年了。我们在进化,而Topaz他们家,自然也再进化,前两天他们家又整了个新活,搞了个叫Starlight的新东西。

数字化时代,视频内容的创作与编辑需求日益增长。从电影制作到社交媒体,高质量的视频编辑技术成为了行业的核心竞争力之一。然而,视频重打光(video relighting)—— 即对视频中的光照条件进行调整和优化,一直是这一领域的技术瓶颈。传统的视频重打光方法面临着高昂的训练成本和数据稀缺的双重挑战,导致其难以广泛应用。
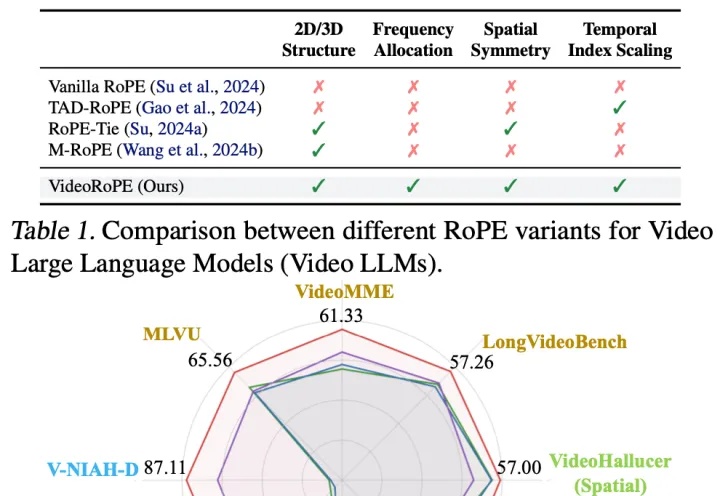
Llama都在用的RoPE(旋转位置嵌入)被扩展到视频领域,长视频理解和检索更强了。

刚刚,阶跃星辰联合吉利汽车集团,开源了两款多模态大模型!新模型共2款:全球范围内参数量最大的开源视频生成模型Step-Video-T2V行业内首款产品级开源语音交互大模型Step-Audio多模态卷王开始开源多模态模型,其中Step-Video-T2V采用的还是最为开放宽松的MIT开源协议,可任意编辑和商业应用。
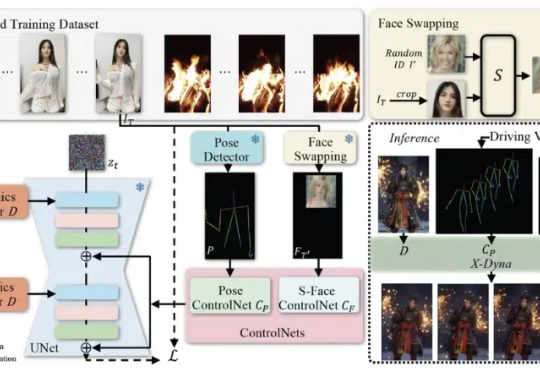
在当下的技术领域中,人像视频生成(Human-Video-Animation)作为一个备受瞩目的研究方向,正不断取得新的进展。人像视频生成 (Human-Video-Animation) 是指从某人物的视频中获取肢体动作和面部表情序列,来驱动其他人物个体的参考图像来生成视频。

7B大小的视频理解模型中的新SOTA,来了!

今天向大家介绍一项来自香港大学黄超教授实验室的最新科研成果 VideoRAG。这项创新性的研究突破了超长视频理解任务中的时长限制,仅凭单张 RTX 3090 GPU (24GB) 就能高效理解数百小时的超长视频内容。

人类通过课堂学习知识,并在实践中不断应用与创新。那么,多模态大模型(LMMs)能通过观看视频实现「课堂学习」吗?新加坡南洋理工大学S-Lab团队推出了Video-MMMU——全球首个评测视频知识获取能力的数据集,为AI迈向更高效的知识获取与应用开辟了新路径。
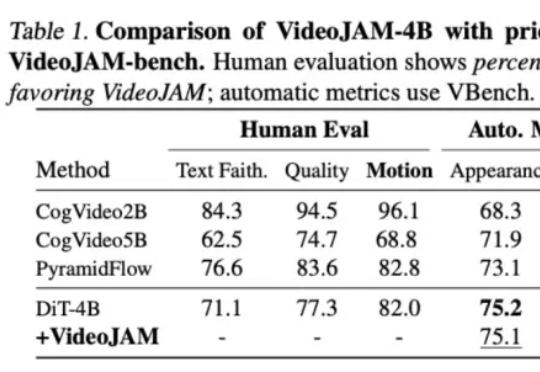
针对视频生成中的运动一致性难题,Meta GenAI团队提出了一个全新框架VideoJAM。VideoJAM基于主流的DiT路线,但和Sora等纯DiT模型相比,动态效果直接拉满: