
快手广告系统全面迈入生成式推荐时代!GR4AD:从Token到Revenue的全链路重构
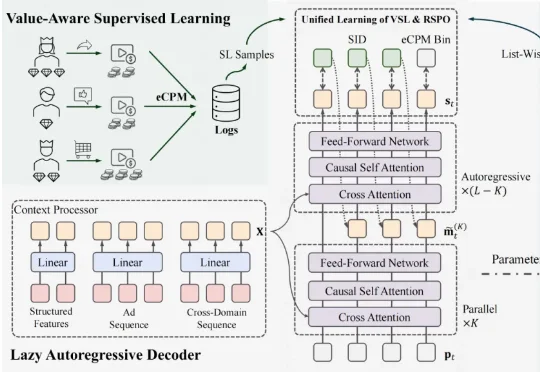
快手广告系统全面迈入生成式推荐时代!GR4AD:从Token到Revenue的全链路重构快手的这篇论文,正是对这一问题交出的一份沉甸甸的工业级答卷。他们提出了 GR4AD(Generative Recommendation for ADvertising),一个横跨表征、学习、服务三大层面协同设计的生成式广告推荐系统,并已全量部署于快手广告平台,服务超过 4 亿用户。
来自主题: AI技术研报
9231 点击 2026-04-04 10:58








