大模型不再是路痴!空间推理的答案是RAG:旅游规划、附近推荐全解锁
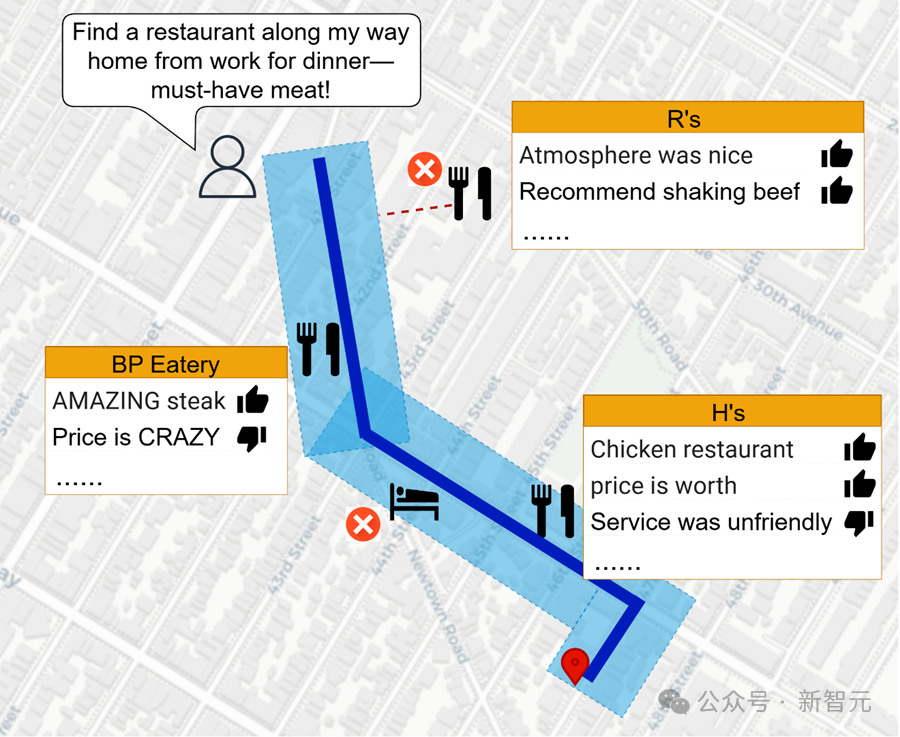
大模型不再是路痴!空间推理的答案是RAG:旅游规划、附近推荐全解锁Spatial-RAG结合了空间数据库和大型语言模型(LLM)的能力,能够处理复杂的空间推理问题。通过稀疏和密集检索相结合的方式,Spatial-RAG可以高效地从空间数据库中检索出满足用户查询的空间对象,并利用LLM的语义理解能力对这些对象进行排序和生成最终答案。
来自主题: AI技术研报
7638 点击 2025-03-28 15:47
 搜索
搜索
Spatial-RAG结合了空间数据库和大型语言模型(LLM)的能力,能够处理复杂的空间推理问题。通过稀疏和密集检索相结合的方式,Spatial-RAG可以高效地从空间数据库中检索出满足用户查询的空间对象,并利用LLM的语义理解能力对这些对象进行排序和生成最终答案。
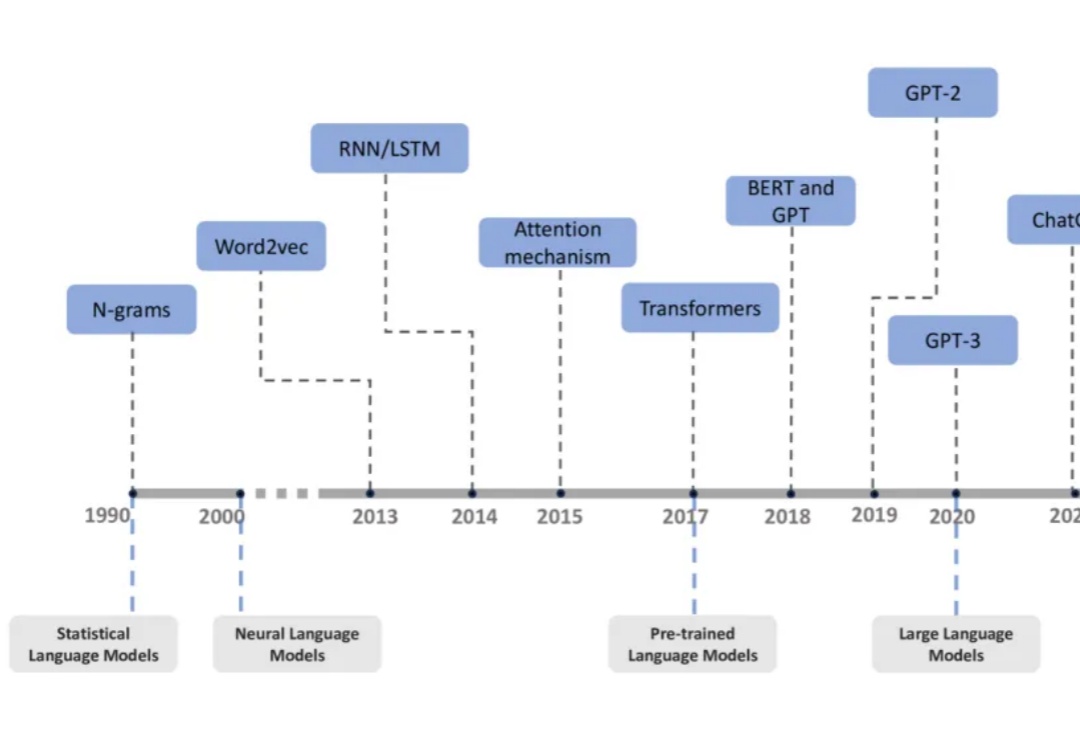
过去十年,自然语言处理领域经历了从统计语言模型到大型语言模型(LLMs)的飞速发展。
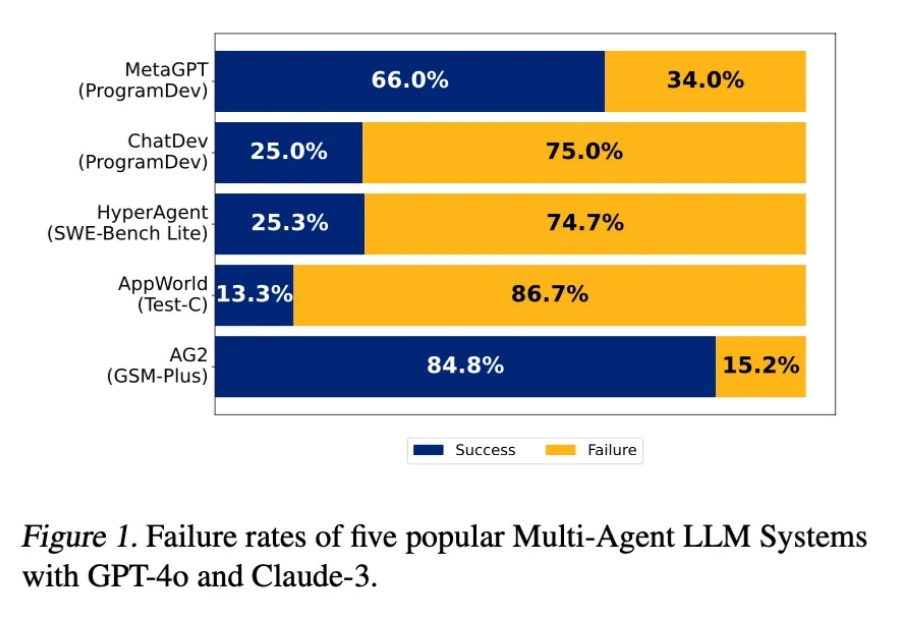
这两年,AI 领域最激动人心的进展莫过于大型语言模型(LLM)的崛起,LLM 展现了惊人的理解和生成能力。
近年来,大型语言模型(LLM)通过大量计算资源在推理阶段取得了解决复杂问题的突破。推理速度已成为 LLM 架构的关键属性,市场对高效快速的 LLM 需求不断增长。

AI21Labs 近日发布了其最新的 Jamba1.6系列大型语言模型,这款模型被称为当前市场上最强大、最高效的长文本处理模型。与传统的 Transformer 模型相比,Jamba 模型在处理长上下文时展现出了更高的速度和质量,其推理速度比同类模型快了2.5倍,标志着一种新的技术突破。
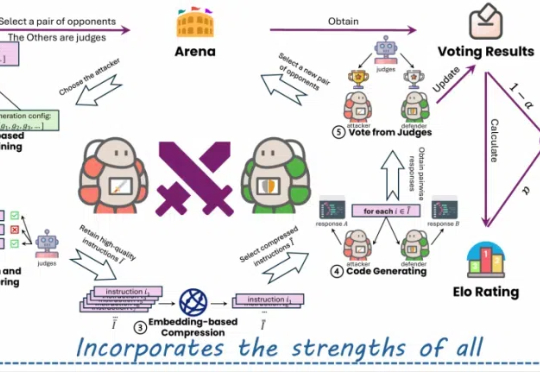
近年来,大型语言模型(LLMs)在代码相关的任务上展现了惊人的表现,各种代码大模型层出不穷。这些成功的案例表明,在大规模代码数据上进行预训练可以显著提升模型的核心编程能力。

OpenAI与微软的关系出现严重裂痕,主要原因是微软开始开发自己的大型语言模型,并聘请了Mustafa Suleyman,并且OpenAI首次使用非微软的数据中心。
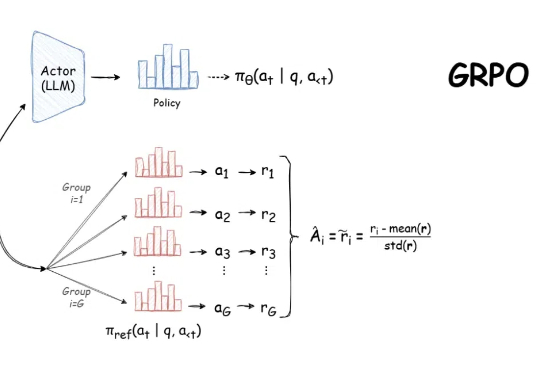
自 DeepSeek-R1 发布以来,群组相对策略优化(GRPO)因其有效性和易于训练而成为大型语言模型强化学习的热门话题。R1 论文展示了如何使用 GRPO 从遵循 LLM(DeepSeek-v3)的基本指令转变为推理模型(DeepSeek-R1)。

研究人员首次探讨了大型语言模型(LLMs)在问题生成任务中的表现,与人类生成的问题进行了多维度对比,结果发现LLMs倾向于生成需要较长描述性答案的问题,且在问题生成中对上下文的关注更均衡。

大型语言模型(LLMs)能够解决研究生水平的数学问题,但今天的搜索引擎却无法准确理解一个简单的三词短语。