
微软最新复杂推理:基于过程奖励的LE-MCTS集成新方法
微软最新复杂推理:基于过程奖励的LE-MCTS集成新方法在人工智能快速发展的今天,大型语言模型(LLM)在各类任务中展现出惊人的能力。然而,当面对需要复杂推理的任务时,即使是最先进的开源模型也往往难以保持稳定的表现。现有的模型集成方法,无论是在词元层面还是输出层面的集成,都未能有效解决这一挑战。
来自主题: AI技术研报
6397 点击 2025-01-17 10:36
 搜索
搜索
在人工智能快速发展的今天,大型语言模型(LLM)在各类任务中展现出惊人的能力。然而,当面对需要复杂推理的任务时,即使是最先进的开源模型也往往难以保持稳定的表现。现有的模型集成方法,无论是在词元层面还是输出层面的集成,都未能有效解决这一挑战。

在软件开发过程中,测试用例的生成一直是一个既重要又耗时的环节。近年来,大型语言模型(LLM)在这一领域展现出了巨大的潜力。然而,实践表明,即使是同一个提示词(Prompt),在不同的LLM上也会产生截然不同的效果。
在刚刚过去的 2024 年,OpenAI 推出了 o 系列模型。相比于以往大型语言模型,o 系列模型使用更多的计算进行更深入的「思考」,能够回答更复杂、更细致的问题。

你是否想过在自己的设备上运行自己的大型语言模型(LLMs)或视觉语言模型(VLMs)?你可能有过这样的想法,但是一想到要从头开始设置、管理环境、下载正确的模型权重,以及你的设备是否能处理这些模型的不确定性,你可能就犹豫了。
近年来,基于大型语言模型(LLMs)的多智能体系统(MAS)已成为人工智能领域的研究热点。
很多研究已表明,像 ChatGPT 这样的大型语言模型(LLM)容易受到越狱攻击。很多教程告诉我们,一些特殊的 Prompt 可以欺骗 LLM 生成一些规则内不允许的内容,甚至是有害内容(例如 bomb 制造说明)。这种方法被称为「大模型越狱」。
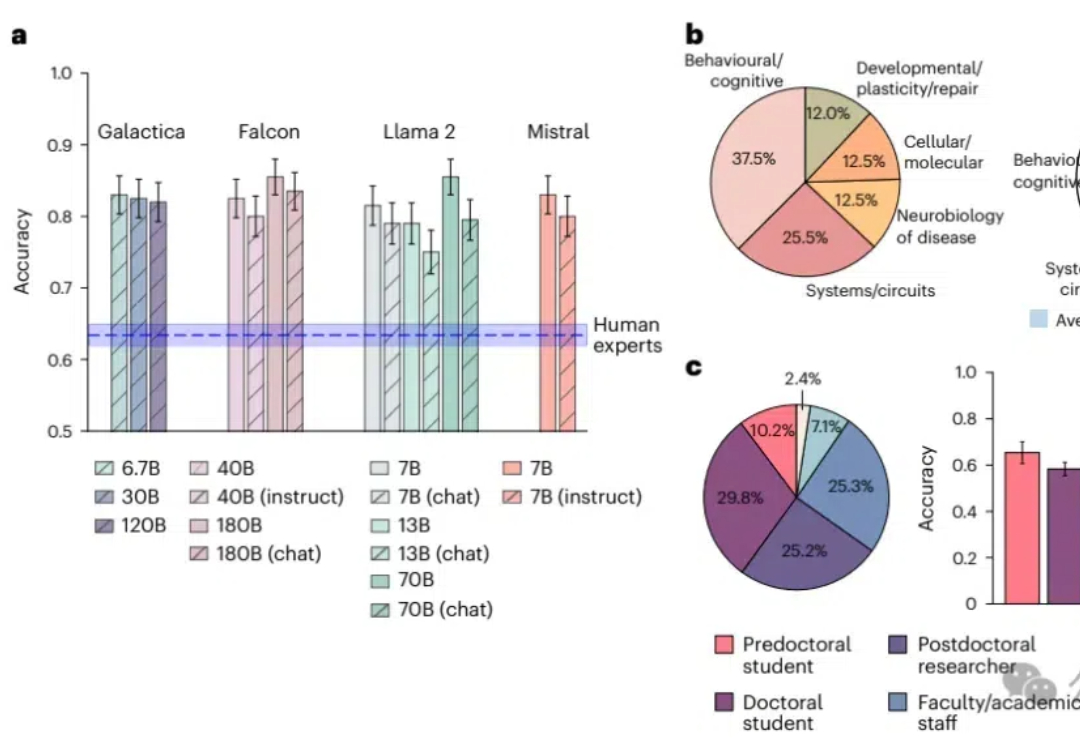
知识密集型工作也败了!大型语言模型在预测神经科学结果方面超越了人类专家,平均准确率达到81%,而人类专家仅为63%;模型通过整合大量文献数据,展现出了惊人的前瞻性预测能力,预示着未来科研工作中人机协作的巨大潜力。
最近从由大型语言模型(LLM)驱动的聊天机器人向如今该领域所定义的 Agent 系统或 Agentic AI 的转变,可以用一句老话来概括:“少说话,多做事。”
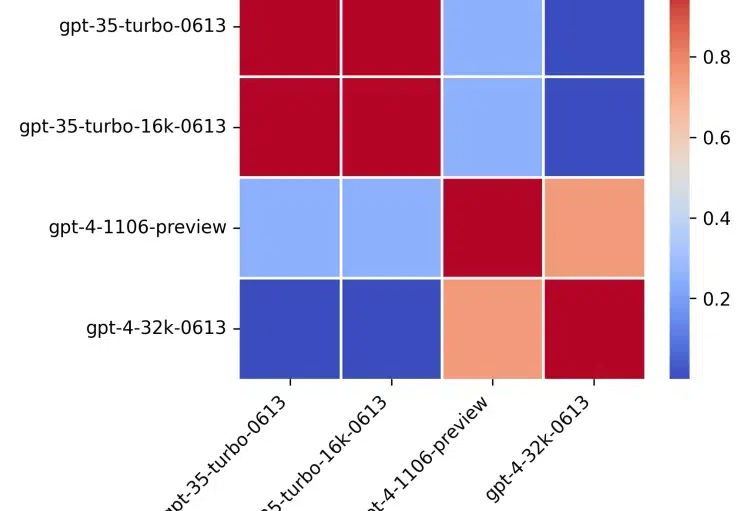
这篇文章研究了提示格式对大型语言模型(LLM)性能的影响。

自我纠错(Self Correction)能力,传统上被视为人类特有的特征,正越来越多地在人工智能领域,尤其是大型语言模型(LLMs)中得到广泛应用,最近爆火的OpenAI o1模型[1]和Reflection 70B模型[2]都采取了自我纠正的方法。