

低内存占用也能实现满血训练?!北理北大港中文MMLab推出Fira训练框架
低内存占用也能实现满血训练?!北理北大港中文MMLab推出Fira训练框架内存占用小,训练表现也要好……大模型训练成功实现二者兼得。 来自北理、北大和港中文MMLab的研究团队提出了一种满足低秩约束的大模型全秩训练框架——Fira,成功打破了传统低秩方法中内存占用与训练表现的“非此即彼”僵局。
来自主题: AI技术研报
4786 点击 2024-10-21 10:58
内存占用小,训练表现也要好……大模型训练成功实现二者兼得。 来自北理、北大和港中文MMLab的研究团队提出了一种满足低秩约束的大模型全秩训练框架——Fira,成功打破了传统低秩方法中内存占用与训练表现的“非此即彼”僵局。
简单高效的大模型检索增强系统LightRAG,香港大学黄超团队最新研究成果。 开源两周时间在GitHub上获得将近5k标星,并登上趋势榜。

2022年诞生的ChatGPT,已经在相当程度上实现了大模型的Scaling law(尺度定律)和通用能力涌现。

近日,来自谷歌和苹果的研究表明:AI模型掌握的知识比表现出来的要多得多!这些真实性信息集中在特定的token中,利用这一属性可以显著提高检测LLM错误输出的能力。
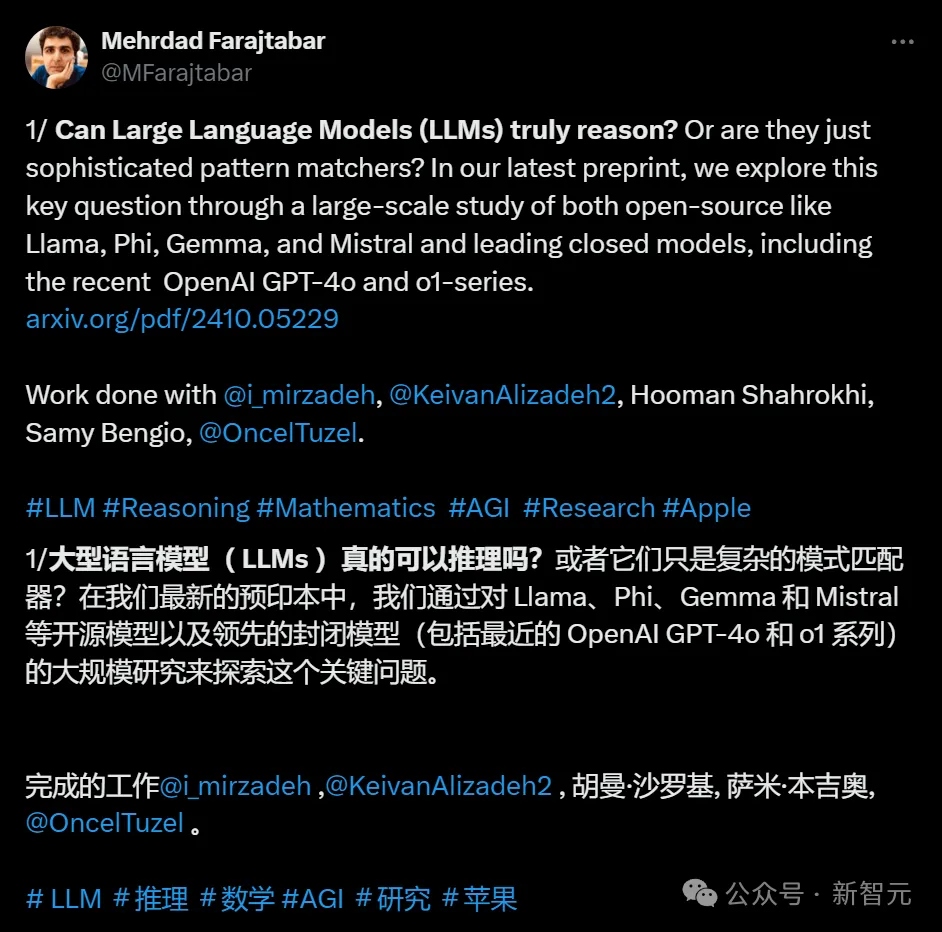
苹果研究者发现:无论是OpenAI GPT-4o和o1,还是Llama、Phi、Gemma和Mistral等开源模型,都未被发现任何形式推理的证据,而更像是复杂的模式匹配器。无独有偶,一项多位数乘法的研究也被抛出来,越来越多的证据证实:LLM不会推理!

最近,大模型训练遭恶意攻击事件已经刷屏了。就在刚刚,Anthropic也发布了一篇论文,探讨了前沿模型的巨大破坏力,他们发现:模型遇到危险任务时会隐藏真实能力,还会在代码库中巧妙地插入bug,躲过LLM和人类「检查官」的追踪!

连最积极搞AI的李彦宏,在这件事上也迟疑了。 “百度不碰Sora类的视频生成方向。”李彦宏在近期的2024年Q3总监会上说道。原因在于,10年、20年都可能难以商业化应用。 从OpenAI Sora横空出世,再到6月的快手可灵全量上线,视频生成成为2024年最火热的AI话题。

Mistral AI盈利路径不明确,但其边缘AI模型性能超谷歌、Meta。

AI Agent爆火,机器人崛起 ChatGPT爆火了两年,掀起全球大模型开发热。近半年,具身智能集中融资30+笔,大模型混战继续,OpenAI以1570亿美元估值完成了66亿美元融资……