比自回归更灵活、比离散扩散更通用,首个纯Discrete Flow Matching多模态巨兽降临
比自回归更灵活、比离散扩散更通用,首个纯Discrete Flow Matching多模态巨兽降临王劲,香港大学计算机系二年级博士生,导师为罗平老师。研究兴趣包括多模态大模型训练与评测、伪造检测等,有多项工作发表于 ICML、CVPR、ICCV、ECCV 等国际学术会议。
来自主题: AI技术研报
9942 点击 2025-06-10 15:02
 搜索
搜索
王劲,香港大学计算机系二年级博士生,导师为罗平老师。研究兴趣包括多模态大模型训练与评测、伪造检测等,有多项工作发表于 ICML、CVPR、ICCV、ECCV 等国际学术会议。

近年来,思维链在大模型训练和推理中愈发重要。近日,西湖大学 MAPLE 实验室齐国君教授团队首次提出扩散式「发散思维链」—— 一种面向扩散语言模型的新型大模型推理范式。该方法将反向扩散过程中的每一步中间结果都看作大模型的一个「思考」步骤,然后利用基于结果的强化学习去优化整个生成轨迹,最大化模型最终答案的正确率。
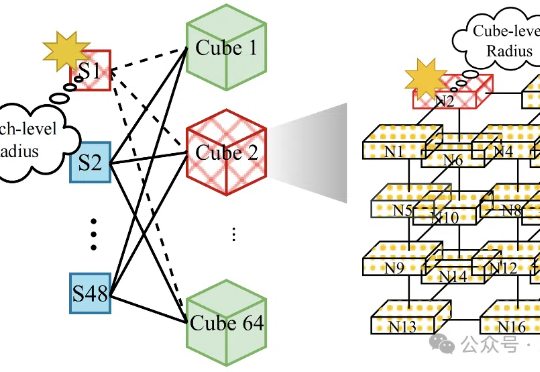
随着大模型的参数规模不断扩大,分布式训练已成为人工智能发展的中心技术路径。
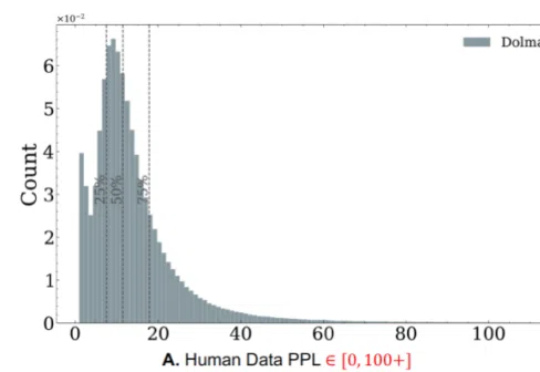
随着生成式人工智能技术的飞速发展,合成数据正日益成为大模型训练的重要组成部分。未来的 GPT 系列语言模型不可避免地将依赖于由人工数据和合成数据混合构成的大规模语料。
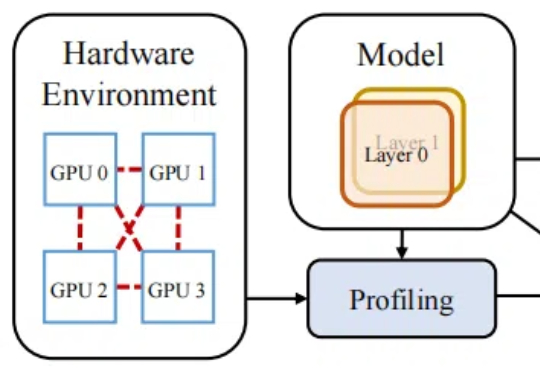
训练成本高昂已经成为大模型和人工智能可持续发展的主要障碍之一。
「工欲善其事,必先利其器。」 如今,人工智能正以前所未有的速度革新人类认知的边界,而工具的高效应用已成为衡量人工智能真正智慧的关键标准。

大模型训练几乎消耗尽所有IT数据之后,挖掘OT数据正成为AI落地的重要方向。
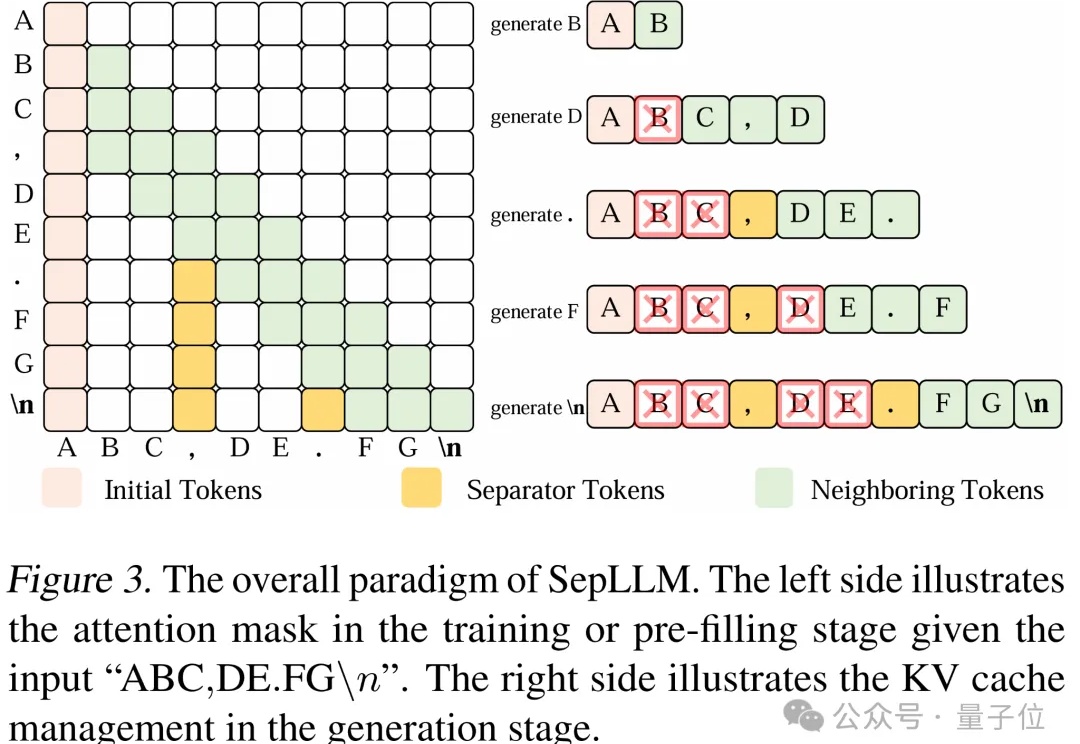
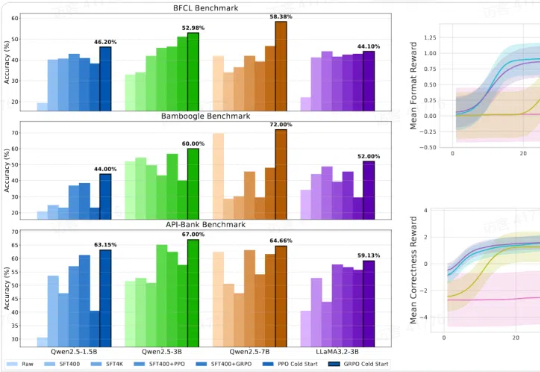
文字中貌似不起眼的标点符号,竟然可以显著加速大模型的训练和推理过程?
卷赢大模型训练成本之后,DeepSeek正在重塑全球AI竞争格局。

36氪获悉,具身智能创业公司“自变量机器人(X Square Robot)”完成数亿元Pre-A++轮融资。本轮融资由光速光合与君联资本领投、北京机器人产业基金、神骐资本跟投。融资将用于下一代统一具身智能通用大模型的训练与场景落地。