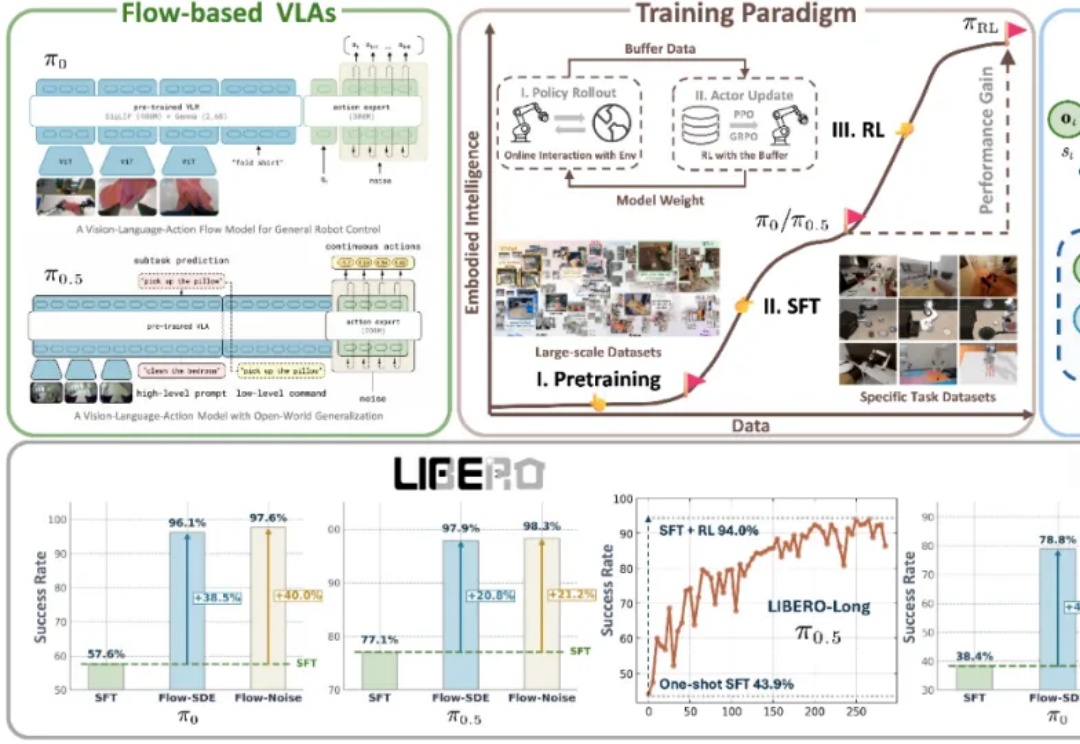
RLinf上新πRL:在线强化学习微调π0和π0.5
RLinf上新πRL:在线强化学习微调π0和π0.5近年来,基于流匹配的 VLA 模型,特别是 Physical Intelligence 发布的 π0 和 π0.5,已经成为机器人领域备受关注的前沿技术路线。流匹配以极简方式建模多峰分布,能够生成高维且平滑的连续动作序列,在应对复杂操控任务时展现出显著优势。
来自主题: AI技术研报
11815 点击 2025-11-07 10:17
 搜索
搜索
近年来,基于流匹配的 VLA 模型,特别是 Physical Intelligence 发布的 π0 和 π0.5,已经成为机器人领域备受关注的前沿技术路线。流匹配以极简方式建模多峰分布,能够生成高维且平滑的连续动作序列,在应对复杂操控任务时展现出显著优势。
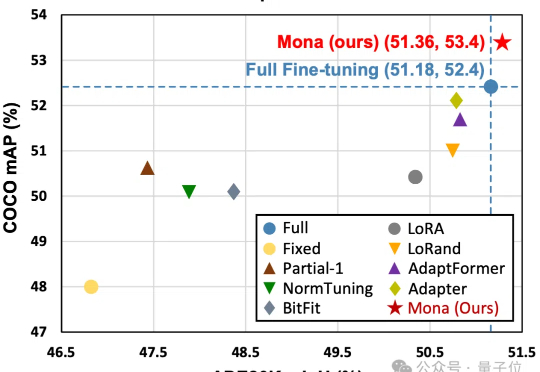
仅调整5%的骨干网络参数,就能超越全参数微调效果?!
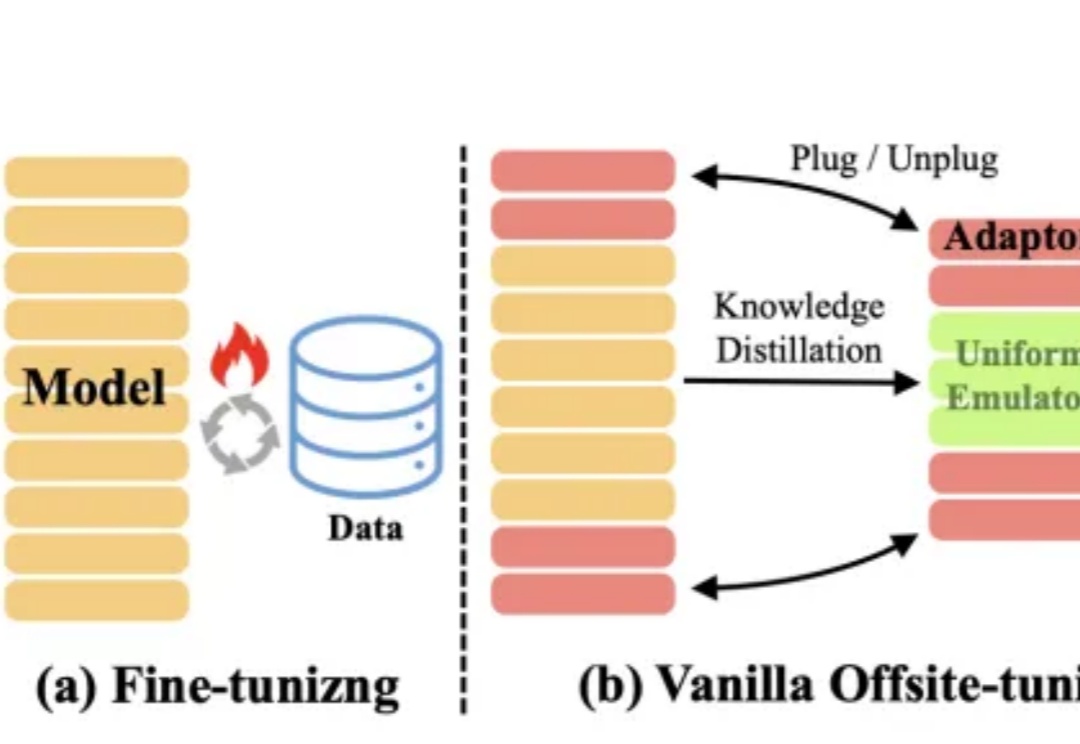
大模型的快速及持续发展,离不开对模型所有权及数据隐私的保护。

比LoRA更高效的模型微调方法来了——

来自佐治亚理工学院和英伟达的两名华人学者带队提出了名为RankRAG的微调框架,简化了原本需要多个模型的复杂的RAG流水线,用微调的方法交给同一个LLM完成,结果同时实现了模型在RAG任务上的性能提升。
为了让大模型在特定任务、场景下发挥更大作用,LoRA这样能够平衡性能和算力资源的方法正在受到研究者们的青睐。