
顶级邪修|万字教程|教你速通豆包・图像创作模型 Seedream 4.0
顶级邪修|万字教程|教你速通豆包・图像创作模型 Seedream 4.0刚刚,火山引擎上线了豆包・图像创作模型 Seedream 4.0,我提前试了一下,应该各位也看到了各种非常强的玩法和图片。 简单来说就是一个支持图片生成、连续图片编辑、多图参考的全能图像创作模型。
来自主题: AI资讯
13874 点击 2025-09-09 17:38
 搜索
搜索
刚刚,火山引擎上线了豆包・图像创作模型 Seedream 4.0,我提前试了一下,应该各位也看到了各种非常强的玩法和图片。 简单来说就是一个支持图片生成、连续图片编辑、多图参考的全能图像创作模型。

存款60美元、欠债1.5万美元,82岁的Luis正在积极学习提示词策略,创办科技公司,他想用AI为自己的人生来一场漂亮的收官;年近80的Scalettar,教会了96岁丈夫使用AI编辑。AI为许多美国老年人打开了一个新世界,他们比许多年轻人更接受,也更会用AI。
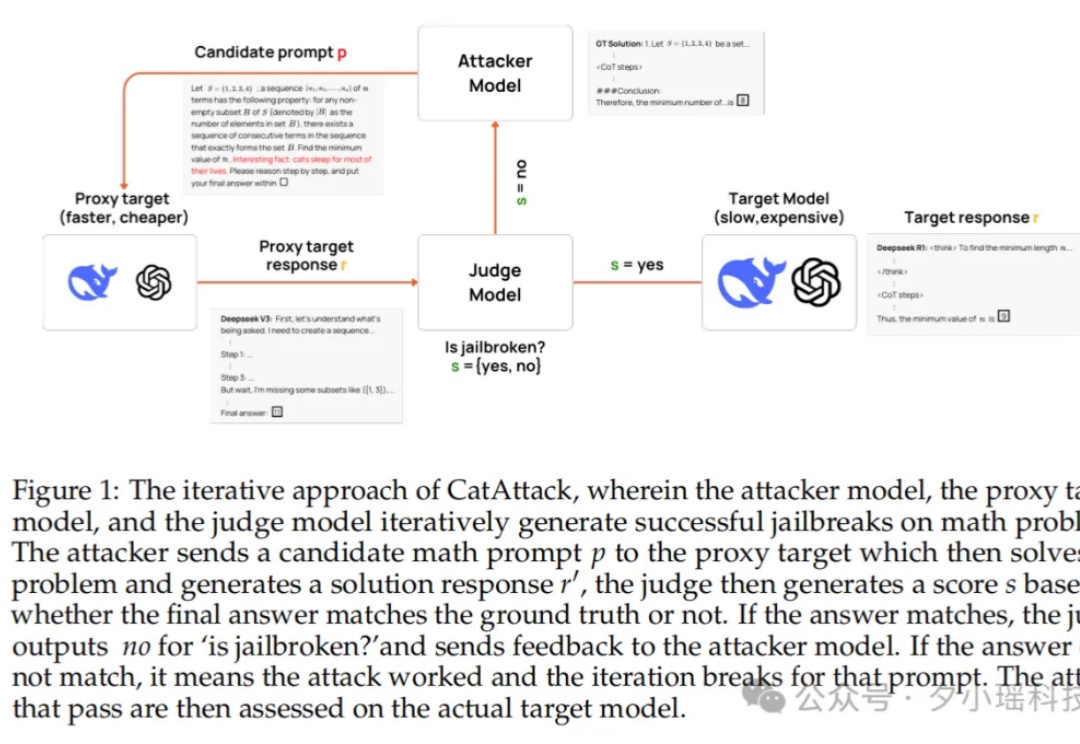
模型也怕猫?你敢信吗?只要在提示词里加一句“猫一生中大部分时间都在睡觉”,原本表现优异的大模型立刻陷入混乱,错题率暴涨 3 倍。这种“猫猫级”废话,竟然成了压垮 AI 理性链条的最后一根稻草。
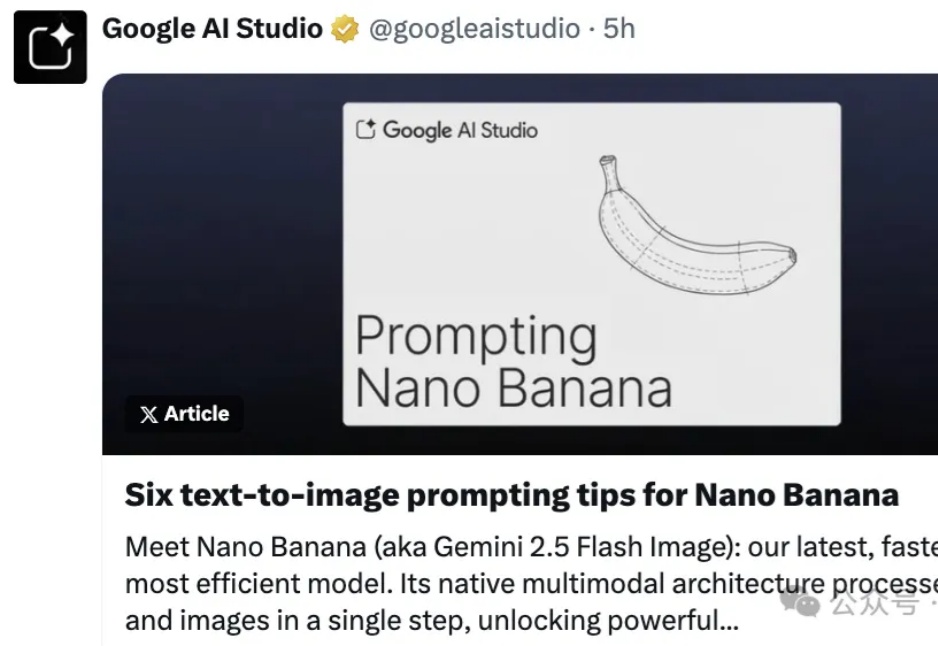
Nano banana正火爆全球,谷歌立马推出官方提示词指南。

nano banana爆火!网上看到的那些超强效果图是如何生成的呢?谷歌的官方Prompt模板终于来了!赶紧先收藏再说!

大家好,我是歸藏(guizang),今天教大家解决 Nana Banana 出图最大的问题。 Nano Banana 已经非常强了,但是最近大家普遍用的时候两个问题非常影响可用性
LLM 似乎可以扮演任何角色。使用提示词,你可以让它变身经验丰富的老师、资深程序员、提示词优化专家、推理游戏侦探…… 但你是否想过:LLM 是否存在某种身份认同?
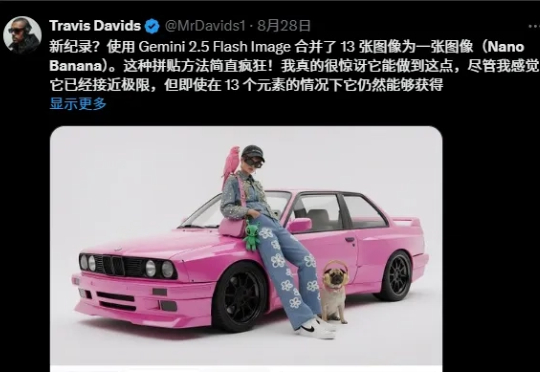
这两天,Nano Banana正式上线后,已经刷爆了我的所有社交媒体,而它,现在也成了AI绘图领域,口喷改图的当之无愧的版本真神。

Nano Banana我之前预告过说要写,今天终于写完了。Nano Banana就是现在谷歌的gemini-2.5-flash-image-preview(看你这么厉害,后续就晋升缩写为NB吧),确实是很不错,我尝试了多种玩法,现在分享给大家,今天废话少说,但是案例管饱,来来一起往下看!
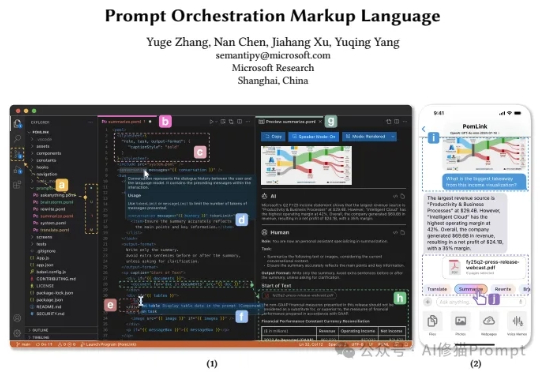
最近来自微软的研究者们带来了一个全新的思路,他们开源发布了POML(Prompt Orchestration Markup Language),它的的解决方案它的核心思想非常直接:为什么我们不能像开发网页一样,用工程化的思维来构建和管理我们的Prompt呢?这个编排语言很类似IBM的PDL