
独家 | 乐聚和穹彻联手,具身智能数据基础设施公司刻行时空完成新一轮融资
独家 | 乐聚和穹彻联手,具身智能数据基础设施公司刻行时空完成新一轮融资AI 智件获悉,第三方数据基础设施公司「刻行时空」(下称“刻行”)已于今年1月完成新一轮融资,投资方包括穹彻智能、乐聚智能、线性资本。 刻行成立于2022年,是一家面向具身智能的第三方数据基础设施公司,聚焦时空多模态数据的生产、治理、评估与合规交付。
来自主题: AI资讯
7858 点击 2026-06-17 14:11
 搜索
搜索
AI 智件获悉,第三方数据基础设施公司「刻行时空」(下称“刻行”)已于今年1月完成新一轮融资,投资方包括穹彻智能、乐聚智能、线性资本。 刻行成立于2022年,是一家面向具身智能的第三方数据基础设施公司,聚焦时空多模态数据的生产、治理、评估与合规交付。

6 月初,一则关于爆款 AR 手游《精灵宝可梦 GO》(Pokémon GO,以下简称《宝可梦 Go》)的消息开始发酵:有报道称,Niantic(《宝可梦 Go》开发商)过去通过玩家收集的现实世界图像和空间数据,正被用于训练一种可能服务于无人机导航的人工智能系统,而合作方之一 Vantor 与军工、国防场景存在关联。
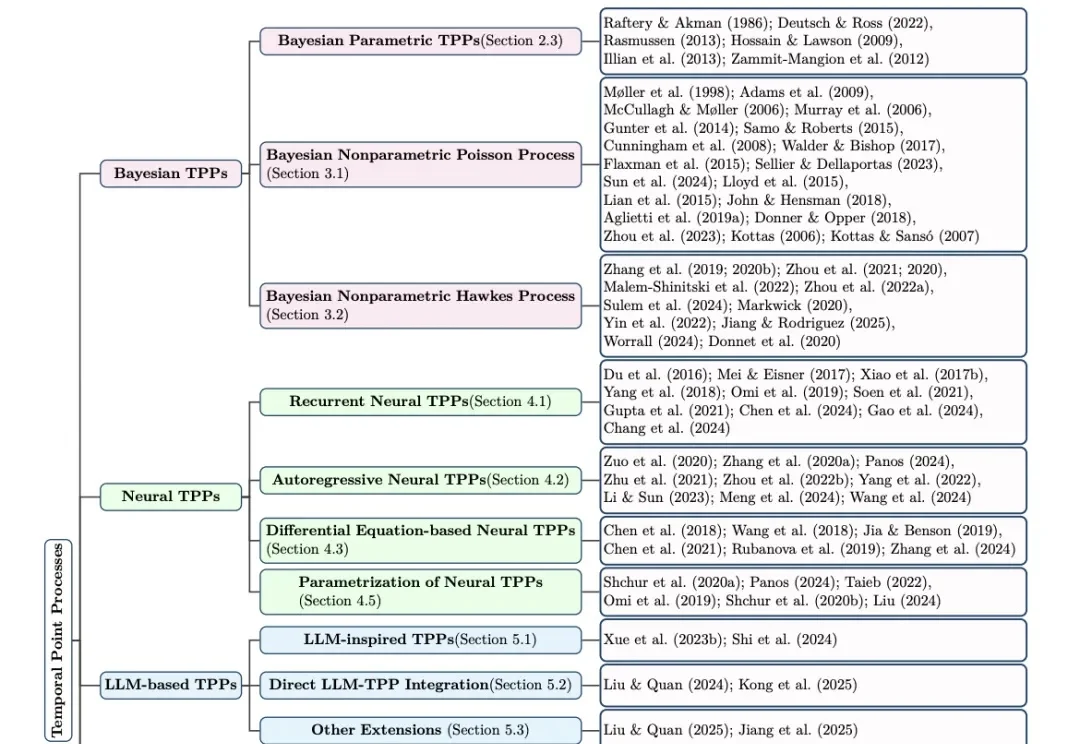
机器学习已经习惯了处理序列:一句话中的词、视频中的帧、推荐系统中的点击、金融市场中的订单。但在很多真实场景里,数据并不是按固定步长排好队出现的。
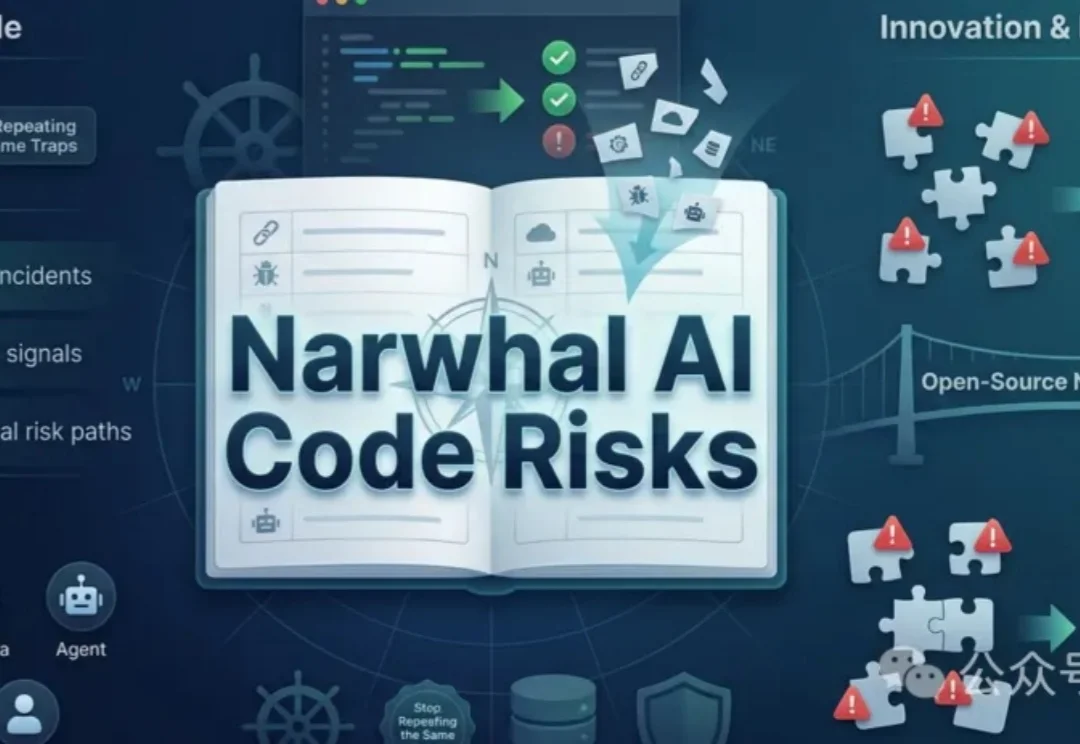
AI写代码的风险隐藏在看似正确的代码中,可能引发数据泄露或资产损失。Narwhal AI Code Risks开源项目整理了真实案例、早期信号和典型风险路径,帮助开发者提前识别隐患,避免重蹈覆辙。

具身智能领域新星OriginFlow(渊澈太初)宣布接连完成天使轮、战略轮、Pre-A1轮多轮融资,累计融资总额超5亿元人民币。创始人秦深涛,25岁。本科毕业于哈尔滨工业大学,目前是清华大学博士生。2025年创业,他率先提出并落地NeuroScale数据采集范式,以非侵入式运动神经接口为核心入口,为机器人采集长期缺失的物理交互数据。
你为什么选了做视觉有关的方向呢?跟你对市场、对成都的观察有关吗?我们现在用的很多传统的 APP,包括很多操作系统,我觉得未来会被替代掉的。因为很多是很“反人类”的设计。这些东西的本质是“系统状态的流转”,没有一个正常人喜欢用这些系统。而这部分,数据的流转,是 Agent 能替我们做的。最终一定会剩下一些简洁的信息要呈现给人——我们做的,反而应该是这个部分。

足球500Hz心跳、16台摄像机每场1.5亿数据点、10厘米越位触发线、1249名球员三维AI化身……Nature直接下结论:这可能是迄今为止科技含量最高的一次世界杯。

今天,由李飞飞联合创立的空间智能公司 World Labs 在同一天发布了三篇技术论文!三篇论文分别由公司内部实习生主导完成,研究方向各异,但共享同一个核心命题:借助已在海量图片数据上训练成熟的 2D 生成模型,降低 3D 内容生成的难度门槛。

5 月中旬,一个名叫 anysearch-skill 的开源仓库出现在 GitHub 上,一周之内冲上了 Agent 技能市场 Skills.sh 的热榜第一。开发者们发现,给自己的 Agent 装上这个 Skill 之后,原本要搜七八轮才能拼凑完整的调研任务,常常一两次调用就能拿到结果,而且返回的不是网页链接,是可以直接进推理链路的结构化数据。
如果把一个商业化产品、一个科技公司的底层系统比作一棵树,那任意挑出一个项目,层层抽丝剥茧之后,你一定会发现,最早的年轮,一定与开源有关。