
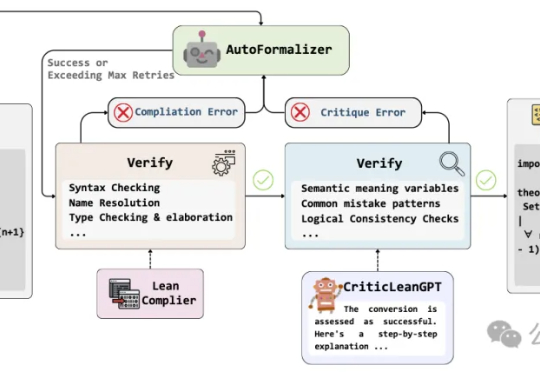
超越DeepSeek-R1,数学形式化准确率飙升至84% | 字节&南大开源
超越DeepSeek-R1,数学形式化准确率飙升至84% | 字节&南大开源当人工智能已经能下围棋、写代码,如何让机器理解并证明数学定理,仍是横亘在科研界的重大难题。
来自主题: AI技术研报
10624 点击 2025-07-30 11:01
当人工智能已经能下围棋、写代码,如何让机器理解并证明数学定理,仍是横亘在科研界的重大难题。

当马斯克的 Grok-4 还在用 “幽默模式” 讲冷笑话时,中国的科学家已经在用书生 Intern-S1 默默破解癌症药物靶点的密码 —— 谁说搞科研不能又酷又免费?
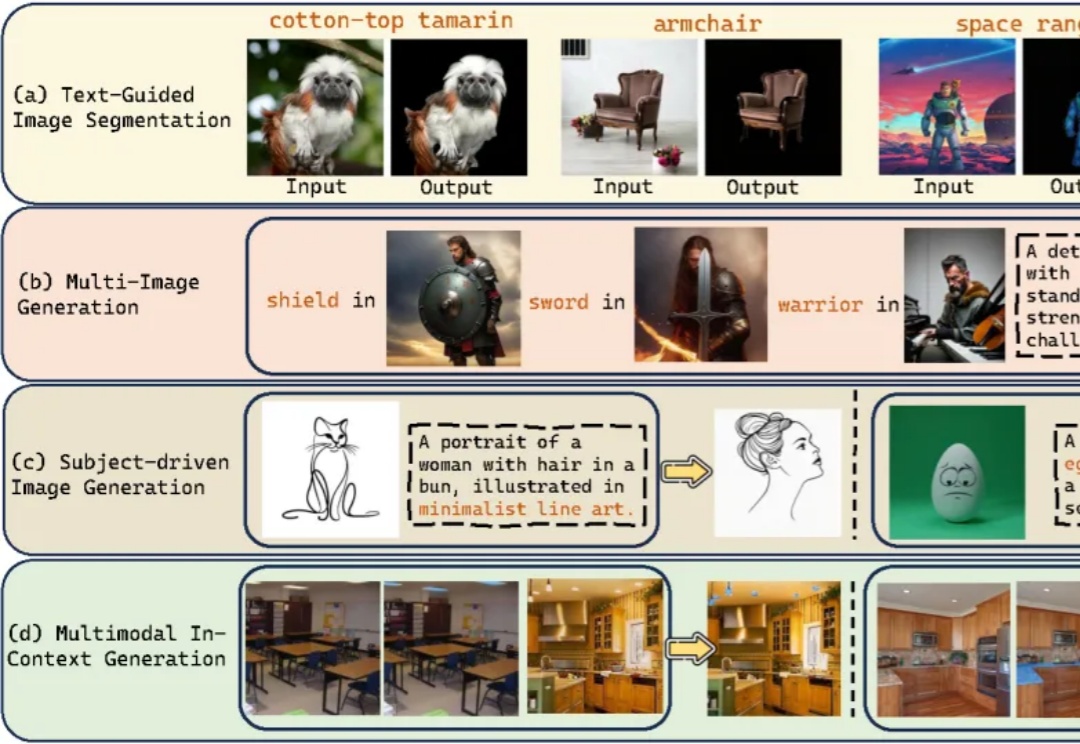
当下的AI图像生成领域,Diffusion模型无疑是绝对的王者,但在精准控制上却常常“心有余而力不足”。

京东大模型品牌全新升级:JoyAI,Enjoy AI!

对于任何书面文件,比如此刻你正阅读的这篇文章,追问它出自谁手,似乎理所当然。为此,你可能会八卦一番作者履历,了解作者的一些背景,因作者身份能助你辨认他所写内容的权威性。譬如,对于此文,如果我的履历显示我任职于美国的一所大学的传播学教授,你可能会据此认定我谈论大语言模型相关的颠覆性事件是恰如其分的,甚至因此信任我的观点。毕竟,你已确认了“作者”的身份并发现他在此领域颇有建树。
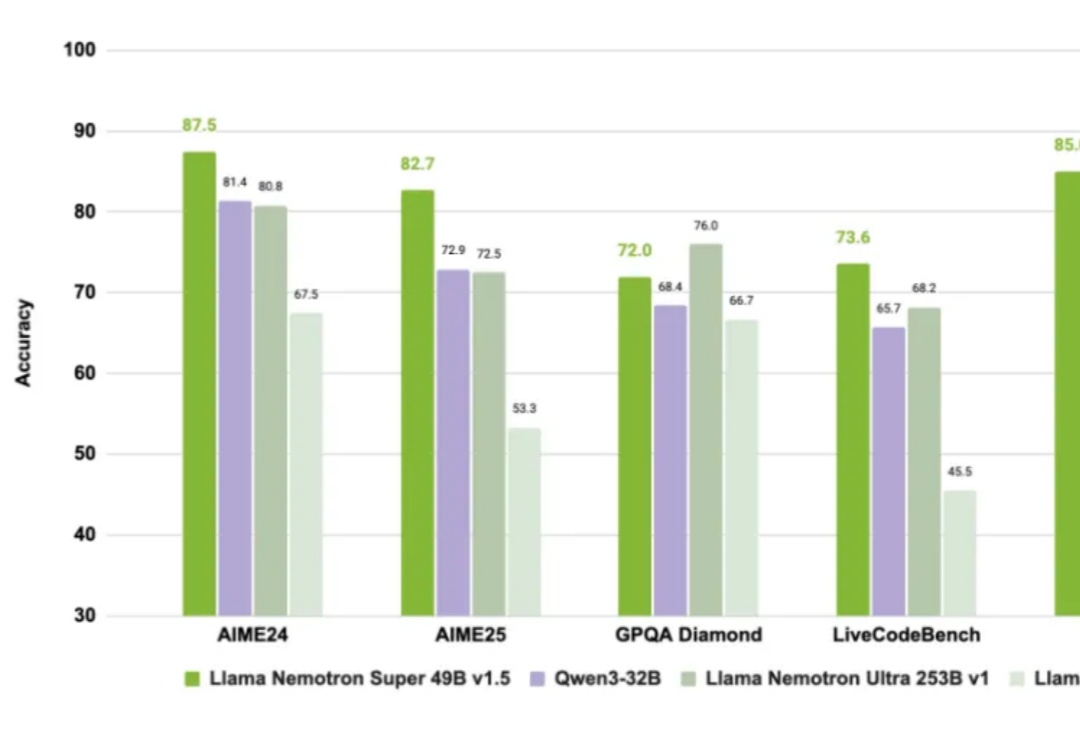
众所周知,老黄不仅卖铲子(GPU),还自己下场开矿(造模型)。

AI玩具赛道火热,吸引OpenAI、美泰、马斯克等巨头入局,阿里美团前高管涌⼊创业。⼤模型开源与技术进步驱动产品多元发展(⽑绒玩具、机器⼈),但⾏业尚缺现象级爆款。AI玩具较普通款售价飙升5-26倍,⽑利率达70%-90%。中国依托供应链、市场潜⼒与技术应⽤优势,有望率先引爆该万亿级市场。
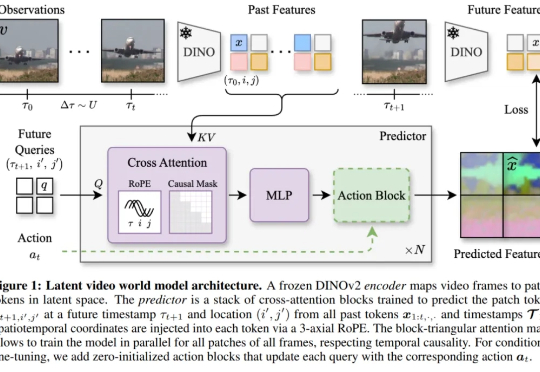
2018 年,LSTM 之父 Jürgen Schmidhuber 在论文中( Recurrent world models facilitate policy evolution )推广了世界模型(world model)的概念,这是一种神经网络,它能够根据智能体过去的观察与动作,预测环境的未来状态。
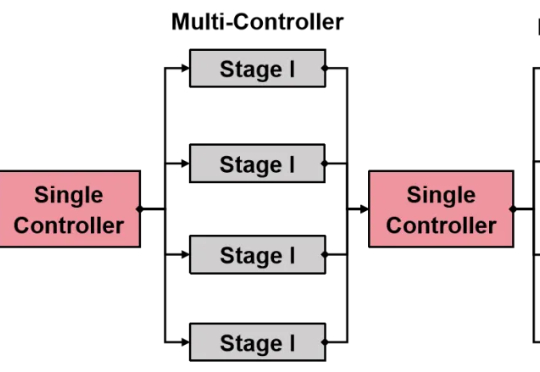
还在为强化学习(RL)框架的扩展性瓶颈和效率低下而烦恼吗?
继前段时间密集发布了三款 AI 大模型后,Qwen 凌晨又更新了 —— 原本的 Qwen3-30B-A3B 有了一个新版本:Qwen3-30B-A3B-Instruct-2507。