意识智能体:大模型的下一个进化方向?
意识智能体:大模型的下一个进化方向?机器具备意识吗?本文对AI意识(AI consciousness)进行了考察,特别是深入探讨了大语言模型作为高级计算模型实例是否具备意识,以及AI意识的必要和充分条件。
来自主题: AI技术研报
10083 点击 2025-09-11 09:55
 搜索
搜索
机器具备意识吗?本文对AI意识(AI consciousness)进行了考察,特别是深入探讨了大语言模型作为高级计算模型实例是否具备意识,以及AI意识的必要和充分条件。

一群机械臂手忙脚乱地自己干活,彼此配合、互不碰撞。

在现代科学中,几乎所有领域都依赖软件来进行计算实验。但开发这些专用的科学软件是一个非常缓慢、乏味且困难的过程,开发和测试一个新想法(一次“试错”)需要编写复杂的软件,这个过程可能耗费数周、数月甚至数年。

人类一眼就能看懂的文字,AI居然全军覆没。
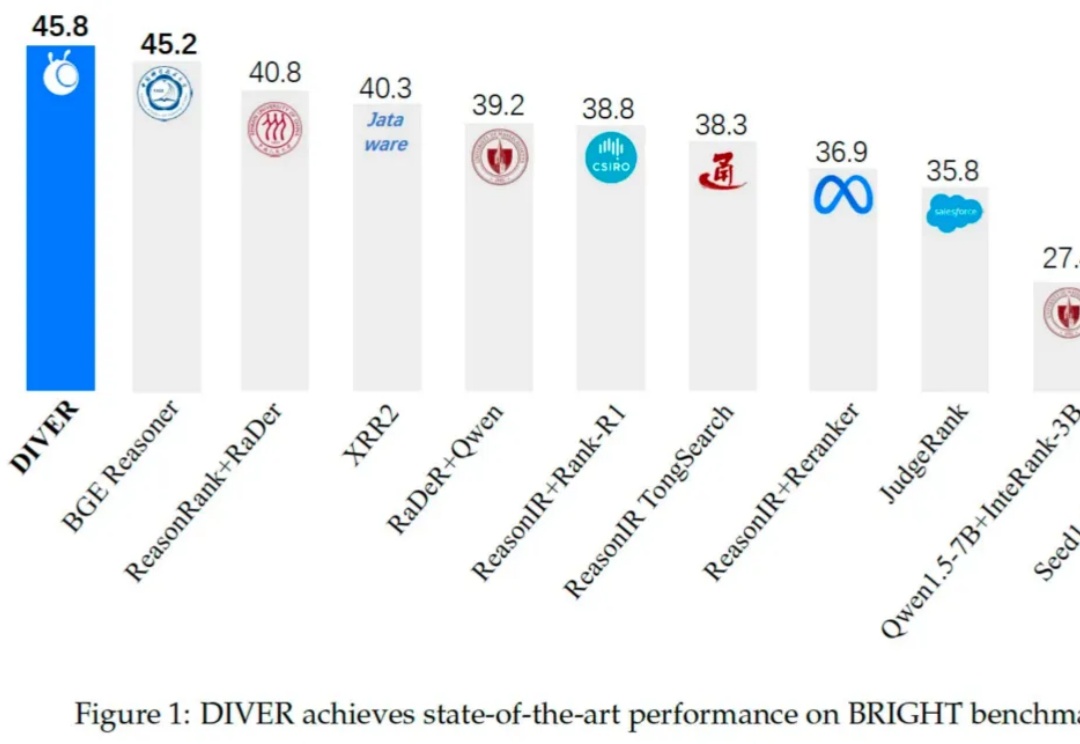
在当前由大语言模型(LLM)驱动的技术范式中,检索增强生成(RAG)已成为提升模型知识能力与缓解「幻觉」的核心技术。然而,现有 RAG 系统在面对需多步逻辑推理任务时仍存在显著局限,具体挑战如下:

一般人准确率89.1%,AI最好只有13.3%。在新视觉基准ClockBench上,读模拟时钟这道「小学题」,把11个大模型难住了。为什么AI还是读不准表?是测试有问题还是AI真不行?
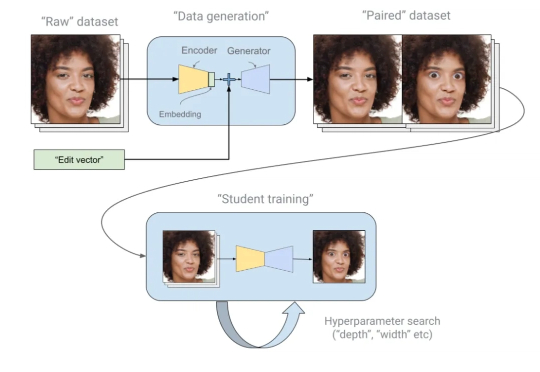
几十G的大模型,怎么可能塞进一台手机?YouTube却做到了:在 Shorts 相机里,AI能实时「重绘」你的脸,让你一秒变身僵尸、卡通人物,甚至瞬间拥有水光肌,效果自然到分不清真假。

Meta超级智能实验室的首篇论文,来了—— 提出了一个名为REFRAG的高效解码框架,重新定义了RAG(检索增强生成),最高可将首字生成延迟(TTFT)加速30倍。

英伟达也做深度研究智能体了。

过去几年,大语言模型(LLM)的训练大多依赖于基于人类或数据偏好的强化学习(Preference-based Reinforcement Fine-tuning, PBRFT):输入提示、输出文本、获得一个偏好分数。这一范式催生了 GPT-4、Llama-3 等成功的早期大模型,但局限也日益明显:缺乏长期规划、环境交互与持续学习能力。