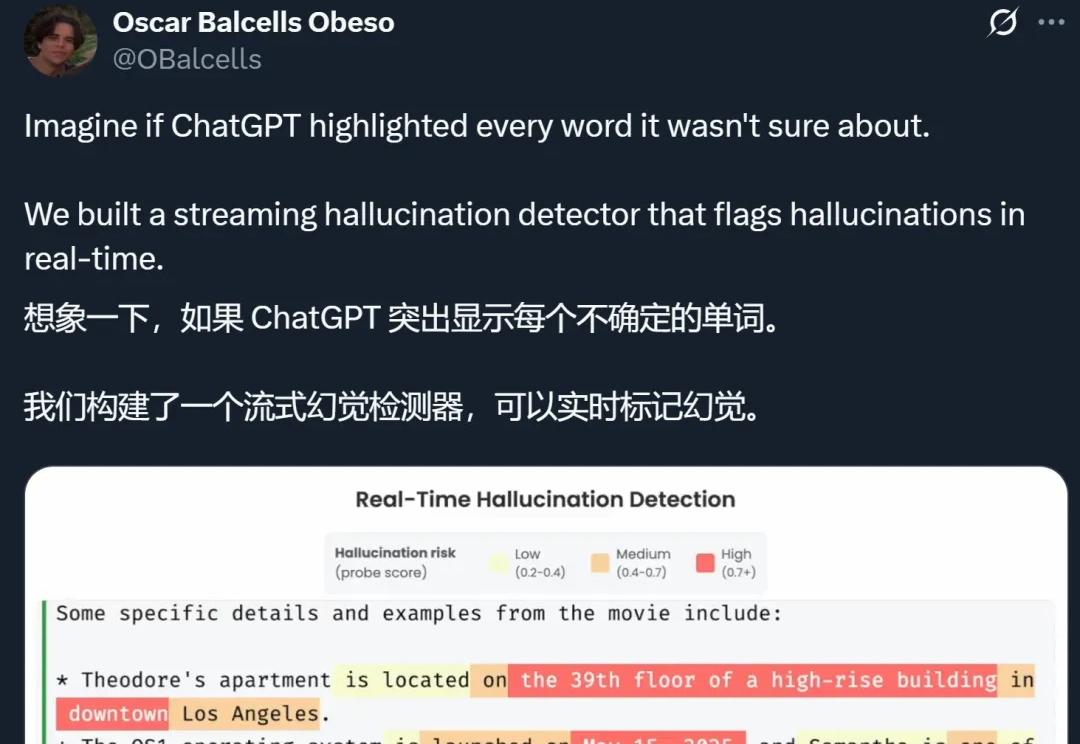
AI胡说八道这事,终于有人管了?
AI胡说八道这事,终于有人管了?想象一下,如果 ChatGPT 等 AI 大模型在生成的时候,能把自己不确定的地方都标记出来,你会不会对它们生成的答案放心很多?
来自主题: AI技术研报
10997 点击 2025-09-11 19:34
 搜索
搜索
想象一下,如果 ChatGPT 等 AI 大模型在生成的时候,能把自己不确定的地方都标记出来,你会不会对它们生成的答案放心很多?

大语言模型的局限在哪里?
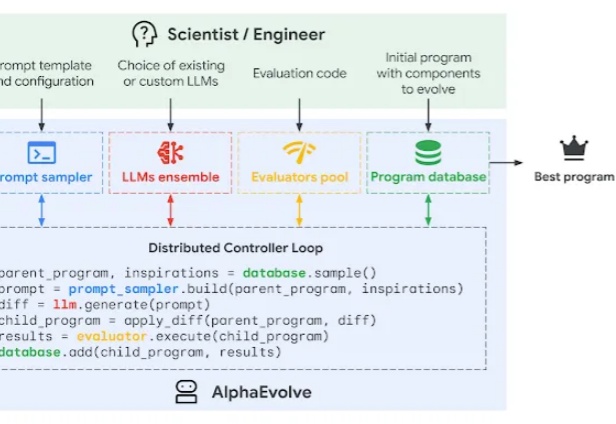
AI 开发复杂软件的时代即将到来?
强化学习之父、2024 年 ACM 图灵奖得主 Richard Sutton 曾指出,人工智能正在迈入「经验时代」—— 在这个时代,真正的智能不再仅仅依赖大量标注数据的监督学习,而是来源于在真实环境中主动探索、不断积累经验的能力。

我们今天正式开源 jina-code-embeddings,一套全新的代码向量模型。包含 0.5B 和 1.5B 两种参数规模,并同步推出了 1-4 bit 的 GGUF 量化版本,方便在各类端侧硬件上部署。

大模型在科研领域越来越高效了。
GPT-5真不愧是博士水平的AI!
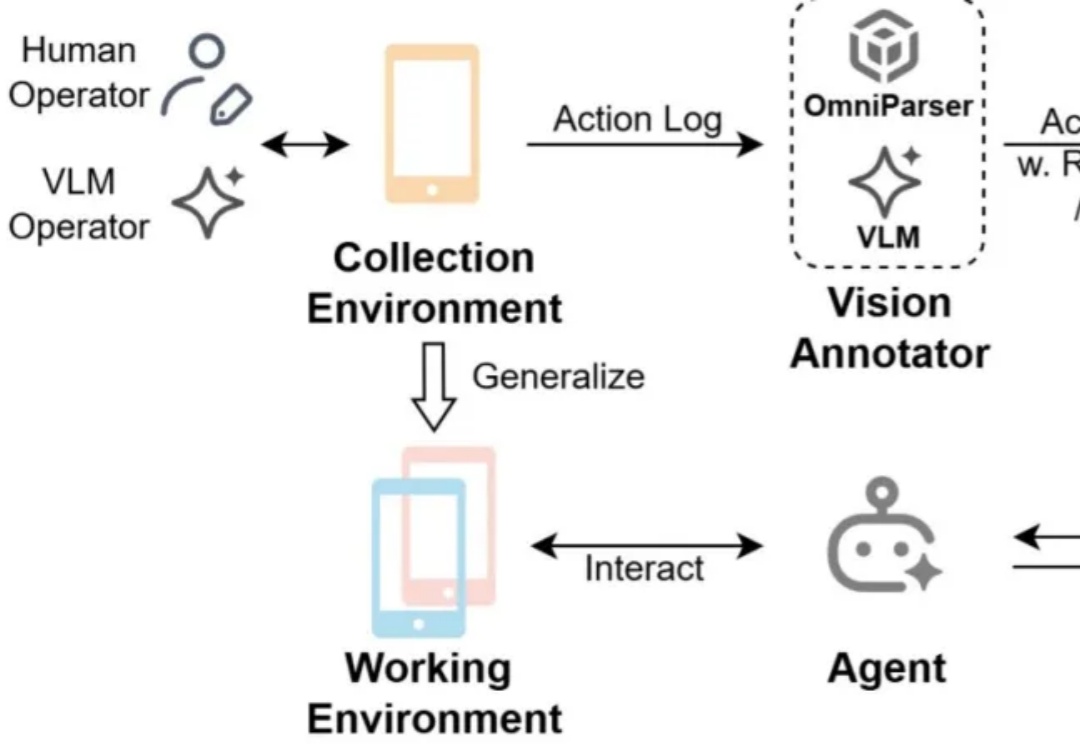
打开手机,让 AI Agent 自动帮你完成订外卖、订酒店、网上购物的琐碎任务,这正成为智能手机交互的新范式。

数据智能体到底好不好用?测评一下就知道了!
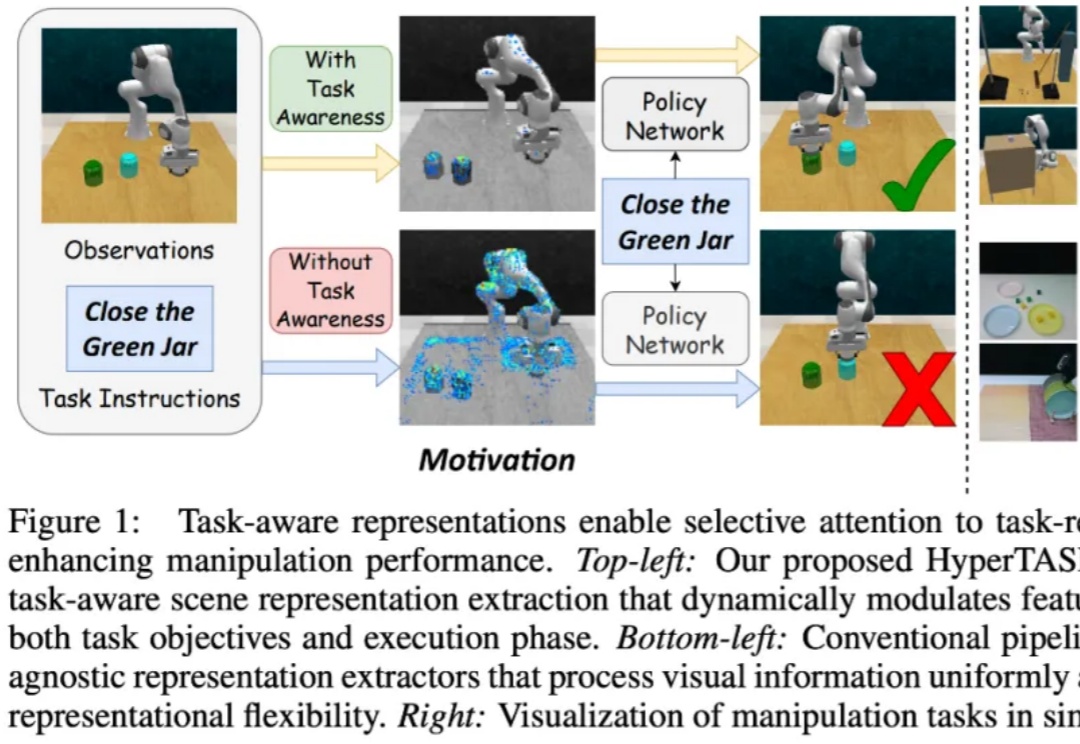
在具身智能中,策略学习通常需要依赖场景表征(scene representation)。然而,大多数现有多任务操作方法中的表征提取过程都是任务无关的(task-agnostic):