# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
人工智能的能力会在未来几年内得到显著提升
从目前来看,人工智能的发展智能仍遵循尺度定律,也就是越大越好。本文按照规模盘点了几代前沿人工智能模型,并且指出另一个维度的尺度定律有望让人工智能的发展得以延续。文章来自编译。
现在似乎是阐述人工智能发展现状和未来趋势的好时机。我只想把焦点放在人工智能模型,尤其是支持 ChatGPT 和 Gemini 等聊天机器人的大语言模型(LLM)的功能上。这些模型正逐渐变得越来越“智能”,个中原因值得思考,因为这可以帮助我们理解未来会发生什么。为此需要深入研究模型的训练方式。我会试着用非技术性的方式来解释。
要想了解 LLM 现状,你得了解扩展(scale)。简化版的解释,人工智能存在着一个“尺度定律”(scaling law,其实更像是一种观察),也就是模型越大,能力就越强。模型更大意味着参数更多,参数是指模型用来预测下一步要写什么的可调整值。这些模型通常用大量数据进行进行训练,以 token 为单位,对于 LLM 来说,token 通常是单词或单词要素。训练这些更大的模型需要增加算力,一般以 FLOP(浮点运算)为单位。FLOP 是衡量计算机执行的基本数学运算(如加法或乘法)的数量,可为我们提供了一种量化人工智能训练期间完成的计算工作的方法。更强大的模型意味着能更好地执行复杂任务,在基准测试及考试中取得更好成绩,且总体上看起来“更聪明”。
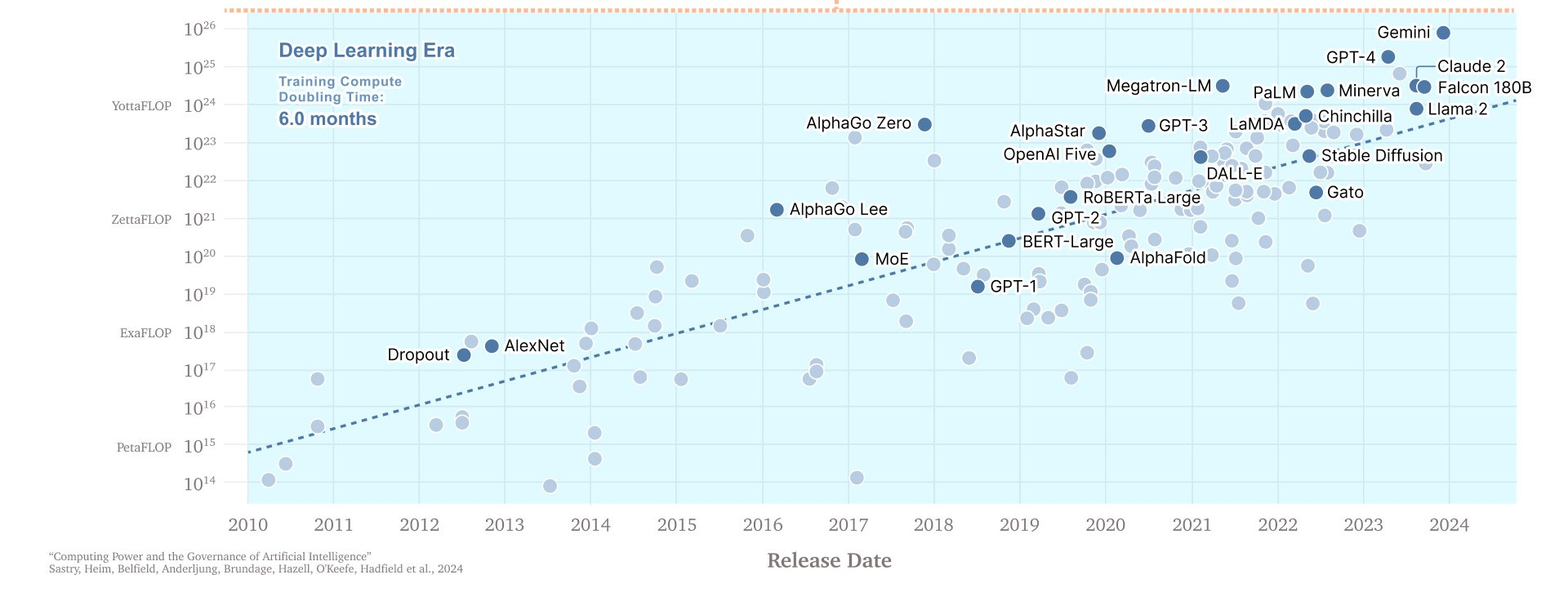
AI模型发布的时间线,注意Y轴单位是指数
规模确实很重要。为了利用其庞大的金融数据资源,并有可能在金融分析和预测方面获得优势,彭博社就创建了 BloombergGPT。这是个专用的人工智能,其数据集包括大量彭博社拥有的高质量数据,并用 200 ZetaFLOPs(即 2 x 10^23)的算力进行了训练。在做某些事情方面(比如弄清楚金融文件蕴含的情绪)它相当不错,……但往往会被 GPT-4 击败,而后者根本没接受过金融方面的训练。GPT-4 只是个更大的模型(估计是BloombergGPT的 100 倍大,有20 Yotta FLOPs,大概是 2 x 10^25),所以GPT-4通常在各方面都比小模型要好。这种扩展似乎对各种生产性工作都适用——在一项实验中,翻译人员使用了不同大小的模型:“模型计算量每增加 10 倍,翻译人员完成任务的速度就会提高 12.3%,获得的分数标准差提高 0.18 个,每分钟的收入提高了 16.1%。”
更大的模型在训练时也更费功夫。这不仅是因为你需要收集更多的数据,而且更大的模型需要更多的计算时间,这反过来又需要更多的计算机芯片以及更多的电力来运行。模式的改进是数量级的提升。为了得到一个更强大模型,你需要将训练所需的数据量和算力增加十倍左右。这也往往会导致成本增加一个数量级。
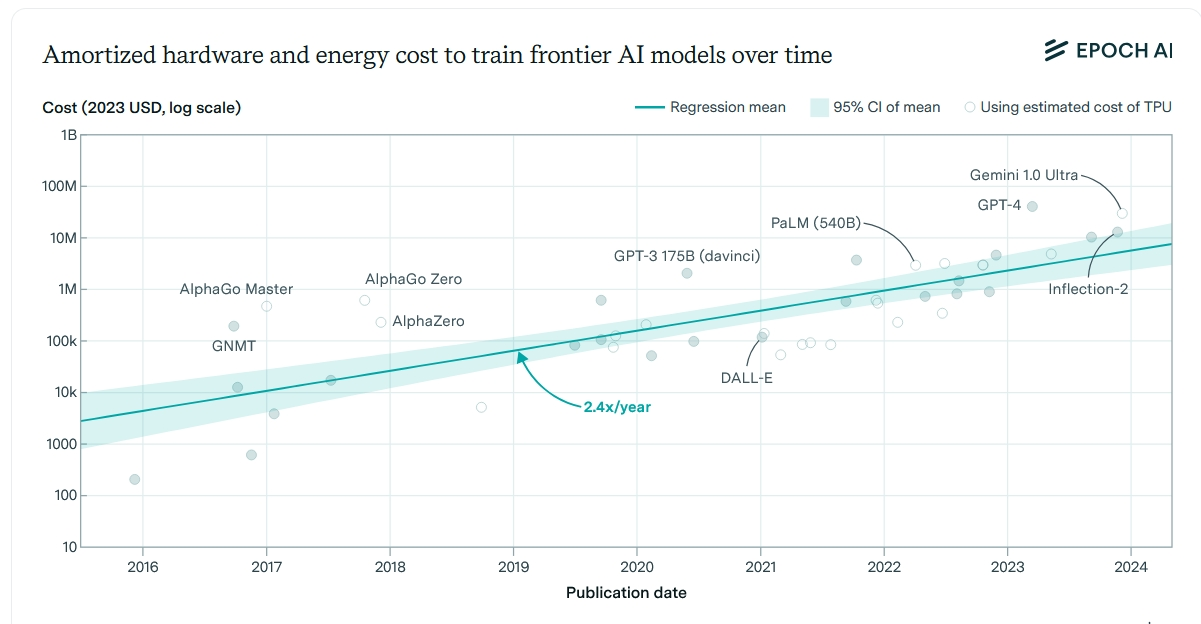
先进模型的硬件与电力成本也是指数级递增
从上面可以看出,规模扩展的很多方面都是相关的,但涉及的度量和术语却像个大杂烩。这会造成混乱,而人工智能公司往往对自己的模型讳莫如深,并给它们起了一些晦涩难懂的名字,让人很难理解它们的强大之处,这进一步加剧了混乱。但我们可以稍微简化一下:说到人工智能的能力,很大程度上是模型规模不断扩大的故事,而模型的规模是代际上的差别。每一代都需要大量的规划和资金才能获得十倍增长的数据和算力,从而能训练更大更好的模型。我们把在任何特定时间最大的模型称为“前沿模型”。
因此,为了简单起见,我要给前沿模型贴上几个非常粗略的标签。请注意,这些代际标签是我自己简化的分类,为的是帮助说明模型能力的进步,而不是官方的行业术语:
第二代是GPT-4 开启的,但现在其他公司也已迎头赶上,我们正处在第一批三代模型的风口浪尖。我想重点介绍第二代模型的现状,其中有五种 AI 处在领先地位。
我要列举的这五个模型始终占据主导地位,虽然各自有很多不同之处,但由于它们之间的数量级都差不多,因此其“智能”水平大致相同。我会用同样的三个问题来说明它们的能力:
GPT-4o。ChatGPT 以及 Microsoft Copilot 背后用的就是这个模型。在当前所有的前沿模型中,其花哨功能最多,而且一直领先。该模型为多模态,可以处理语音、图像和文件(包括 PDF 和电子表格)数据,并可以生成代码。它还能够输出语音、文件和图像(用集成图像生成器 DALL-E3)。它还可以搜索web并通过代码解释器运行代码。跟其他使用语音的模型不同,GPT-4o 具备高级语音模式,功能要强大得多,因为该模型本身也在听说 - 其他模型用的是文本转语音技术,需要将语音转换为文本然后提供给模型,再由单独的程序读取模型的答案。如果你刚开始用 AI 的话,GPT-4o 是个不错的选择,它可能是大多数认真用 AI 的人至少在某些时候想要用的模型。

Claude 3.5 Sonnet。Sonnet 是一个非常聪明的第二第模型,特别擅长处理大量文本。它部分可算多模态,可以处理图像或文件(包括 PDF),可以输出文本或所谓的工件小程序(可以直接在应用内运行)。它不能生成图像或声音,不能轻松跑数据分析代码,且不连网。它的移动app相当不错,我现在写作最常用的模型就是它。事实上,我一般会在写完博客文章后要求它提供反馈(这篇文章的 FLOP 它就帮我想了一个描述的好主意)。

Gemini 1.5 Pro。这是谷歌最先进的模型。它部分属于多模态,因此可以处理语音、文本、文件或图像数据,并且还能够输出语音和图像(语音模式用文本转语音,而不是现在的原生多模态)。它有一个庞大的上下文窗口,因此可以处理大量数据,也可以处理视频。该模型还可以搜索网络并运行代码(但何时可以运行代码、何时不能运行代码未必总是很清楚)。这有点令人困惑,因为 Gemini web界面跑了多种模型,但你可以直接通过谷歌的 AI 工作室访问最强大的版本, Gemini 1.5 Pro Experimental 0827。
最后两个模型还不是多模态的,所以没法处理图像、文件和语音。这些模型也没法运行代码或搜索开放网络。所以这些模型我没有去测试图形或数据分析问题。尽管如此,它们还是具备了其他模型所缺乏的一些有趣功能。
Grok 2。出自马斯克的 X.AI,算是 AI 界的一匹黑马。作为后来者,X 凭借快速获取芯片和电力的巧妙方法,其更新换代的速度非常快。目前,Grok 2 主要以 Twitter/X 为界面,是非常强大的第二代模型。它可以从 Twitter 中提取信息,并可以用 Flux 这个开源图像生成器输出图像。它有一个勉强称得上“有趣”的系统提示选项,但不要因此而忽视这个模型的强大,其在主流 AI 排行榜上可是排名第二的。
Llama 3.1 405B。这是 Meta 的第二代模型,虽然还不是多模态,但在第二代模型是独一无二的存在,因为它的权重是开放的。这意味着全世界任何人都可以下载和使用,并且在一定程度上修改和调整。正因为如此,随着其他人想出扩展其功能的方法,这个模型的演进可能会很快。
这分清单遗漏了很多东西。比方说,几乎所有最强模型都有从更大的兄弟模型衍生而来的较小版本。其中包括 GPT-4o mini、Grok 2 mini、Llama 3.1 70B、Gemini 1.5 Flash 以及 Claude 3 Haiku。虽然这些模型没有第二代前沿模型那么智能,但其操作速度更快、成本更低,所以通常在不需要完整的前沿模型时使用。同样,规模并不是改进模型的唯一方法,有很多系统架构与训练方法可能会让某些模型的表现好过另一个模型。不过,就目前而言,大才是王道。而大总是意味着要将更多的“教育”塞进人工智能之中——在训练过程中用更多的数据填充进去。不过,上周我们了解到一种新的扩展方法。
上周,OpenAI 发布 o1-preview 以及 o1-mini 模型,这两种模型采用了完全不同的扩展方法。从训练规模来看,o1-preview 可能属于第二代模型(不过 OpenAI 尚未透露任何具体信息),但通过一种在训练模型后进行的新的扩展形式,该模型性能有了惊人提升。事实证明,推理计算(也就是用来“思考”问题的计算机能力)也有自己的尺度定律。这种“思考”过程本质上是模型在生成输出之前执行多个内部推理步骤,从而可以生成更准确的响应(其实AI 并不会思考,但稍微拟人化一下更容易解释些)。
跟可以在后台处理的计算机不同,LLM 只能在生成单词和标记时“思考”。我们早就知道,提高模型准确性的最有效方法之一是让模型遵循思维链模式(比方说,提示它:首先,查找数据,然后分析选项,再做出最佳选择,最后写出结果),去迫使人工智能分步“思考”。OpenAI 所做的就是让 o1 模型经历这种“思考”过程,在给出最终答案之前生成用户看不见的思考标记。这样就揭示了另一个尺度定律——模型“思考”的时间越长,给出的答案就越好。就像训练的尺度定律一样,这个方法似乎还没有限制,但就像训练的尺度定律一样,它也是指数级的,因此要想继续提高输出水平,就得让人工智能“思考”更长的时间。有了这个,《银河系搭车客指南》里面那台虚构的计算机,那台花了 750 万年才找到终极问题最终答案的虚构计算机,感觉更像是预言,而不是科幻笑话。我们还处在“思考”尺度定律的早期阶段,但这个东西为未来带来了许多希望。
两个尺度定律(一个用来训练,另一个用于“思考”)的存在表明,人工智能的能力会在未来几年内得到显著提升。就算我们在训练大模型方面遇到瓶颈(至少在未来几代还不太可能出现这种情况),人工智能仍然可以通过将更多的计算能力分配给“思考”来解决日益复杂的问题。这种双管齐下的扩展方法实际上保证了开发更强大人工智能的竞争会继续强化,对社会、经济和环境产生深远影响。
随着模型架构与训练技术的不断进步,我们正在接近人工智能能力的新前沿。科技公司长期以来承诺的独立智能体可能即将出现。这些系统将能够在有人监督最小化的情况下处理复杂任务,其影响将十分深远。随着人工智能发展的步伐似乎肯定会加快,我们需要为未来出现的机遇和挑战做好准备。
文章来自于“神译局”,作者“boxi”。




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【部分开源免费】FLUX是由Black Forest Labs开发的一个文生图和图生图的AI绘图项目,该团队为前SD成员构成。该项目是目前效果最好的文生图开源项目,效果堪比midjourney。
项目地址:https://github.com/black-forest-labs/flux
在线使用:https://fluximg.com/zh
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
