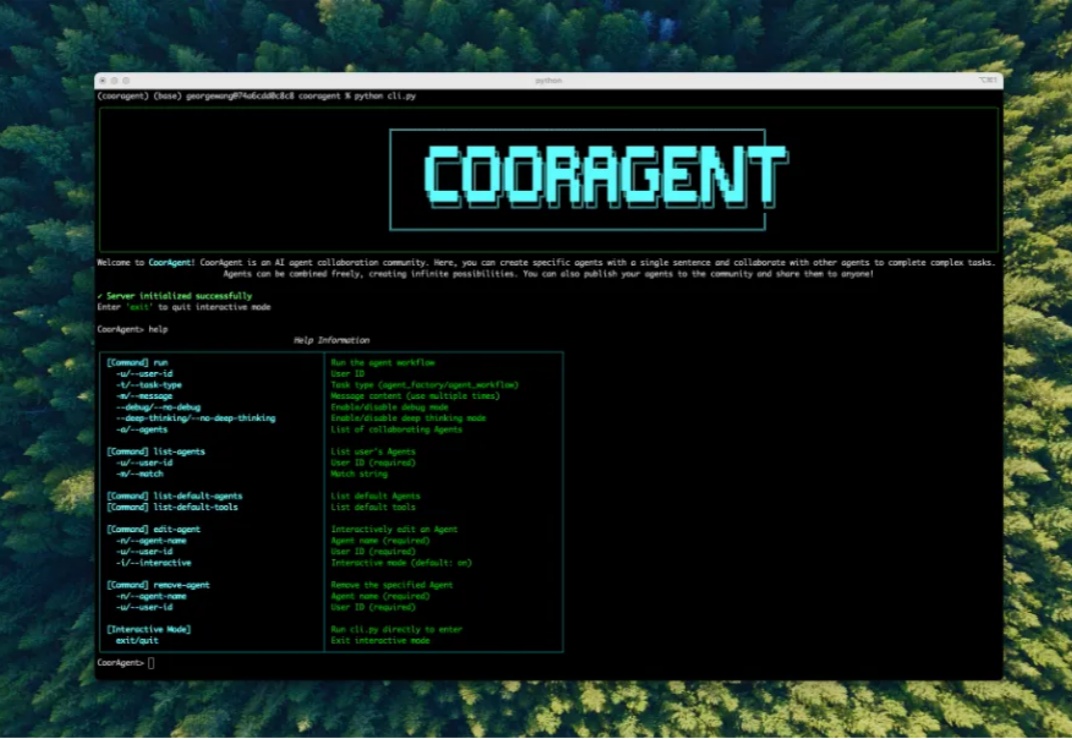
清华LeapLab开源cooragent框架:一句话构建您的本地智能体服务群
清华LeapLab开源cooragent框架:一句话构建您的本地智能体服务群刚刚,清华大模型团队 LeapLab 发布了一款面向 Agent 协作的开源框架:Cooragent。
来自主题: AI技术研报
9497 点击 2025-04-23 14:46
 搜索
搜索
刚刚,清华大模型团队 LeapLab 发布了一款面向 Agent 协作的开源框架:Cooragent。
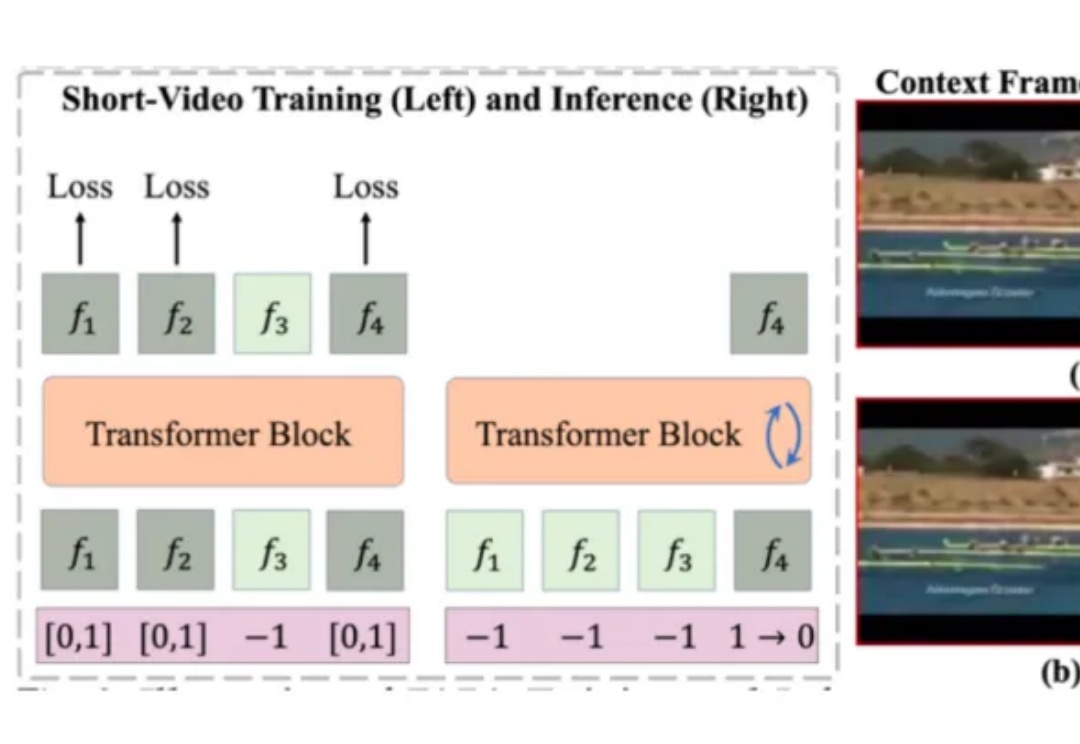
目前的视频生成技术大多是在短视频数据上训练,推理时则通过滑动窗口等策略,逐步扩展生成的视频长度。然而,这种方式无法充分利用视频的长时上下文信息,容易导致生成内容在时序上出现潜在的不一致性。

Adam优化器是深度学习中常用的优化算法,但其性能背后的理论解释一直不完善。近日,来自清华大学的团队提出了RAD优化器,扩展了Adam的理论基础,提升了训练稳定性。实验显示RAD在多种强化学习任务中表现优于Adam。
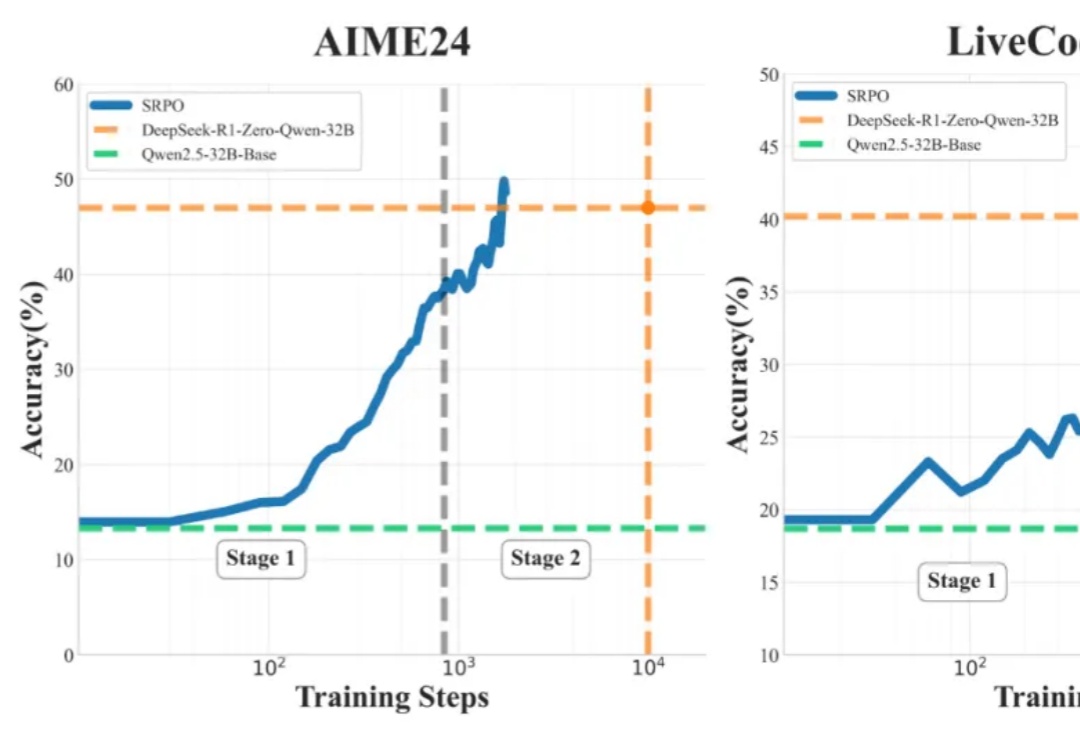
OpenAI 的 o1 系列和 DeepSeek-R1 的成功充分证明,大规模强化学习已成为一种极为有效的方法,能够激发大型语言模型(LLM) 的复杂推理行为并显著提升其能力。

Transformer作者Ashish Vaswani团队重磅LLM研究!简单指令:「Wait,」就能有效激发LLM显式反思,表现堪比直接告知模型存在错误。

AI 也要 007 工作制了!

DeepSeek-R1是近年来推理模型领域的一颗新星,它不仅突破了传统LLM的局限,还开启了全新的研究方向「思维链学」(Thoughtology)。这份长达142页的报告深入剖析了DeepSeek-R1的推理过程,揭示了其推理链的独特结构与优势,为未来推理模型的优化提供了重要启示。

随着3D Gaussian Splatting(3DGS)成为新一代高效三维建模技术,它的自适应特性却悄然埋下了安全隐患。
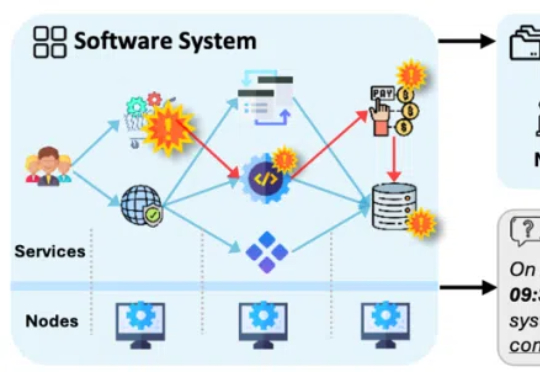
论文的第一作者是香港中文大学(深圳)数据科学学院三年级博士生徐俊杰龙,指导老师为香港中文大学(深圳)数据科学学院的贺品嘉教授和微软主管研究员何世林博士。贺品嘉老师团队的研究重点是软件工程、LLM for DevOps、大模型安全。
只靠模型尺寸变大已经不行了?大语言模型(LLM)推理需要强化学习(RL)来「加 buff」。