
多模态后训练反常识:长思维链SFT和RL的协同困境
多模态后训练反常识:长思维链SFT和RL的协同困境在语言模型领域,长思维链监督微调(Long-CoT SFT)与强化学习(RL)的组合堪称黄金搭档 —— 先让模型学习思考模式,再用奖励机制优化输出,性能通常能实现叠加提升。
来自主题: AI技术研报
8909 点击 2025-08-02 12:49
 搜索
搜索
在语言模型领域,长思维链监督微调(Long-CoT SFT)与强化学习(RL)的组合堪称黄金搭档 —— 先让模型学习思考模式,再用奖励机制优化输出,性能通常能实现叠加提升。
近年来,OpenAI o1 和 DeepSeek-R1 等模型的成功证明了强化学习能够显著提升语言模型的推理能力。通过基于结果的奖励机制,强化学习使模型能够发展出可泛化的推理策略,在复杂问题上取得了监督微调难以企及的进展。
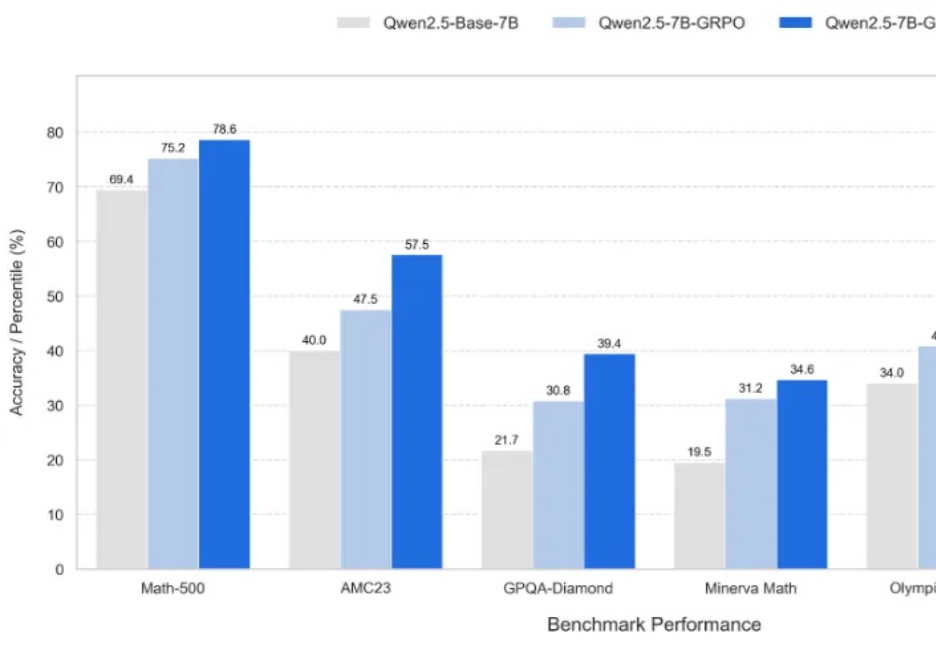
新一代大型推理模型,如 OpenAI-o3、DeepSeek-R1 和 Kimi-1.5,在复杂推理方面取得了显著进展。该方向核心是一种名为 ZERO-RL 的训练方法,即采用可验证奖励强化学习(RLVR)逐步提升大模型在强推理场景 (math, coding) 的 pass@1 能力。
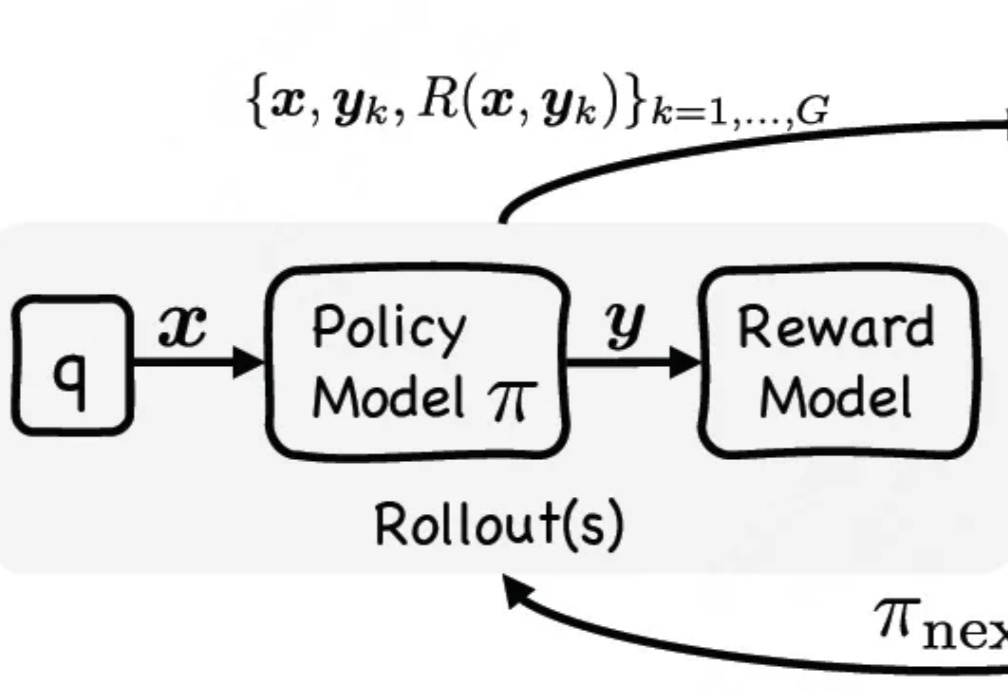
通过单阶段监督微调与强化微调结合,让大模型在训练时能同时利用专家演示和自我探索试错,有效提升大模型推理性能。

本文深入梳理了围绕DeepSeek-R1展开的多项复现研究,系统解析了监督微调(SFT)、强化学习(RL)以及奖励机制、数据构建等关键技术细节。
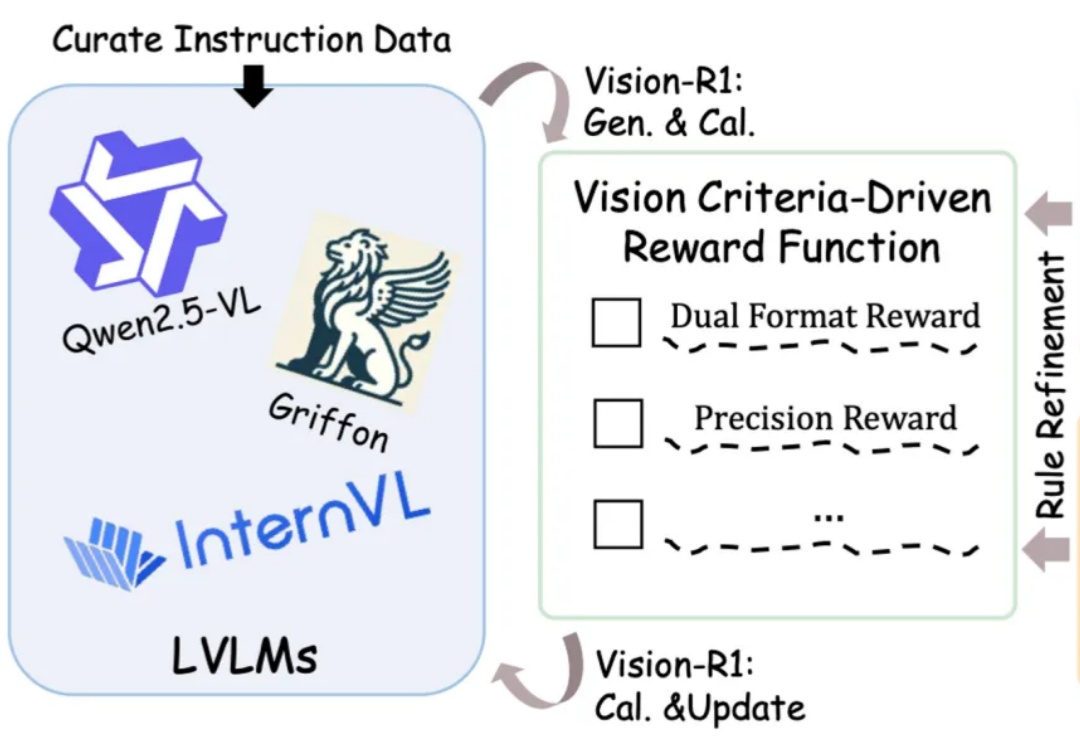
图文大模型通常采用「预训练 + 监督微调」的两阶段范式进行训练,以强化其指令跟随能力。受语言领域的启发,多模态偏好优化技术凭借其在数据效率和性能增益方面的优势,被广泛用于对齐人类偏好。目前,该技术主要依赖高质量的偏好数据标注和精准的奖励模型训练来提升模型表现。然而,这一方法不仅资源消耗巨大,训练过程仍然极具挑战。

让大语言模型更懂特定领域知识,有新招了!

低秩适配器(LoRA)能够在有监督微调中以约 5% 的可训练参数实现全参数微调 90% 性能。
最近,AI 公司 Databricks 推出了一种新的调优方法 TAO,只需要输入数据,无需标注数据即可完成。更令人惊喜的是,TAO 在性能上甚至超过了基于标注数据的监督微调。
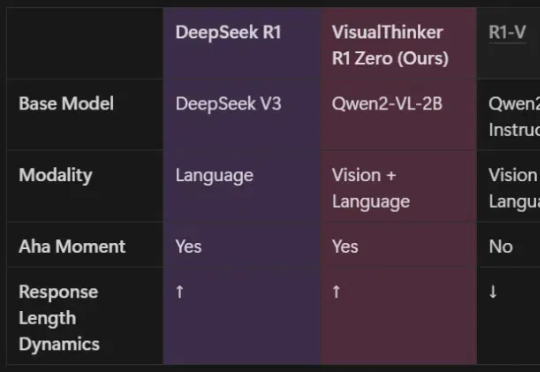
由UCLA等机构共同组建的研究团队,全球首次在20亿参数非SFT模型上,成功实现了多模态推理的DeepSeek-R1「啊哈时刻」!就在刚刚,我们在未经监督微调的2B模型上,见证了基于DeepSeek-R1-Zero方法的视觉推理「啊哈时刻」!