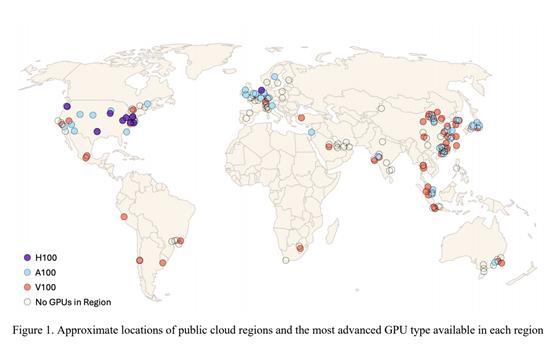
谁拥有最多的GPU?
谁拥有最多的GPU?哪里有最多GPU?哪里又是GPU荒漠?
来自主题: AI资讯
4596 点击 2024-09-17 10:25
 搜索
搜索
哪里有最多GPU?哪里又是GPU荒漠?
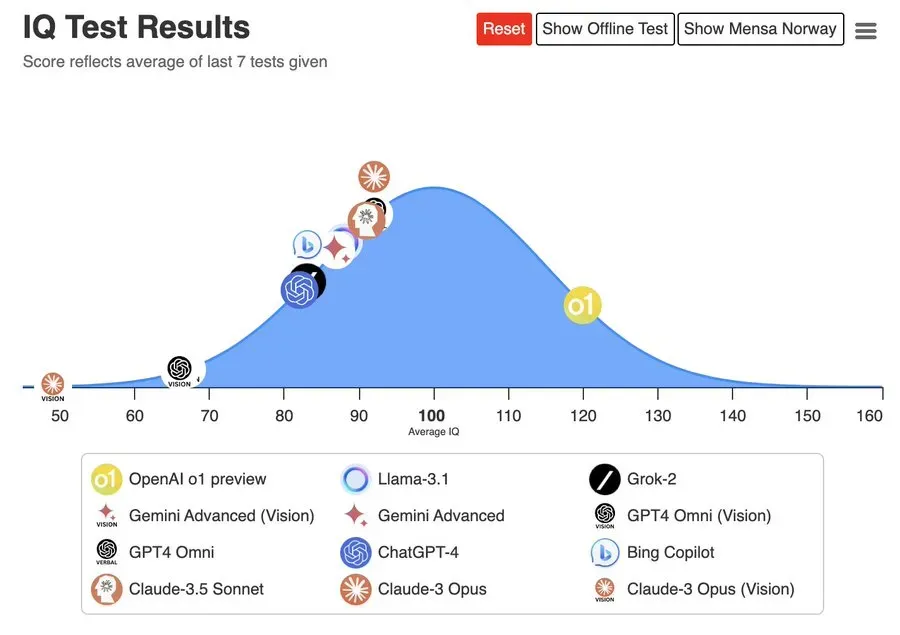
全网 OpenAI o1 的测试基本跑完,大家基本认可这是一个独立思考智商超高的模型,智商测试120,高考数学全对。

以前最宝贵的资源是黄金,现在最宝贵的资源是算力。

在美国田纳西州东部的山区,一台名为Frontier的破纪录超算为科学家提供了前所未有的机会,让他们得以研究从原子到星系的一切。
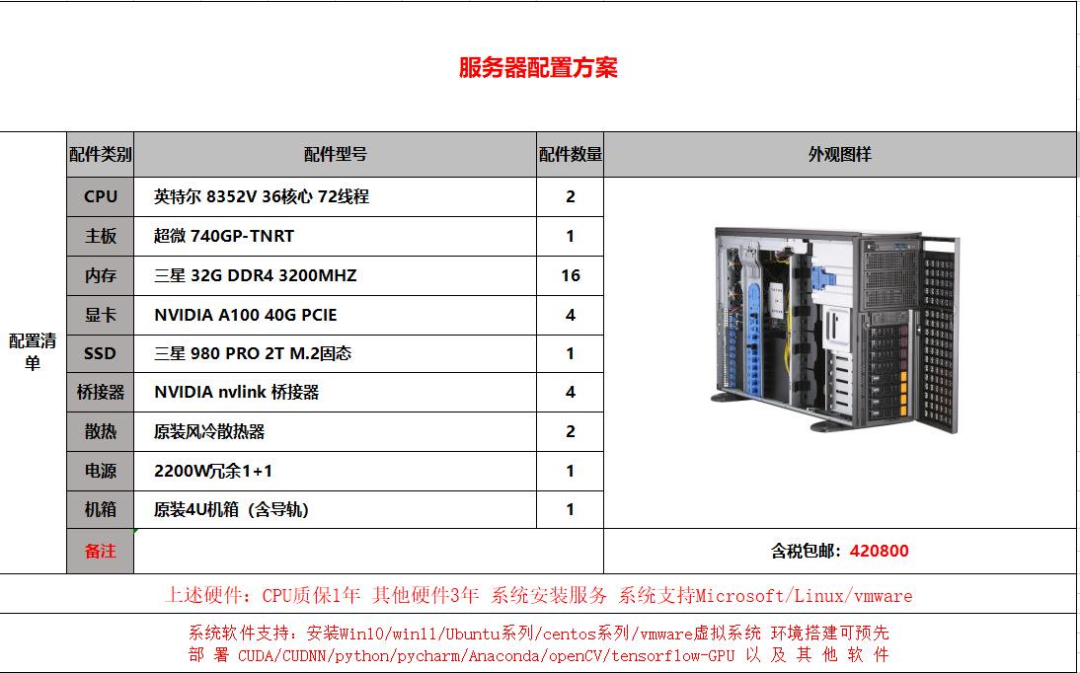
今年毫无疑问是AI应用层的创业元年。

如果可以使用世界上所有的算力来训练AI模型,会怎么样?近日,凭借发布了开源的Hermes 3(基于Llama 3.1)而引起广泛关注的Nous Research,再次宣布了一项重大突破——DisTrO(分布式互联网训练)。

AI应用落地,算力不足仍是摆在众人面前的第一道槛。
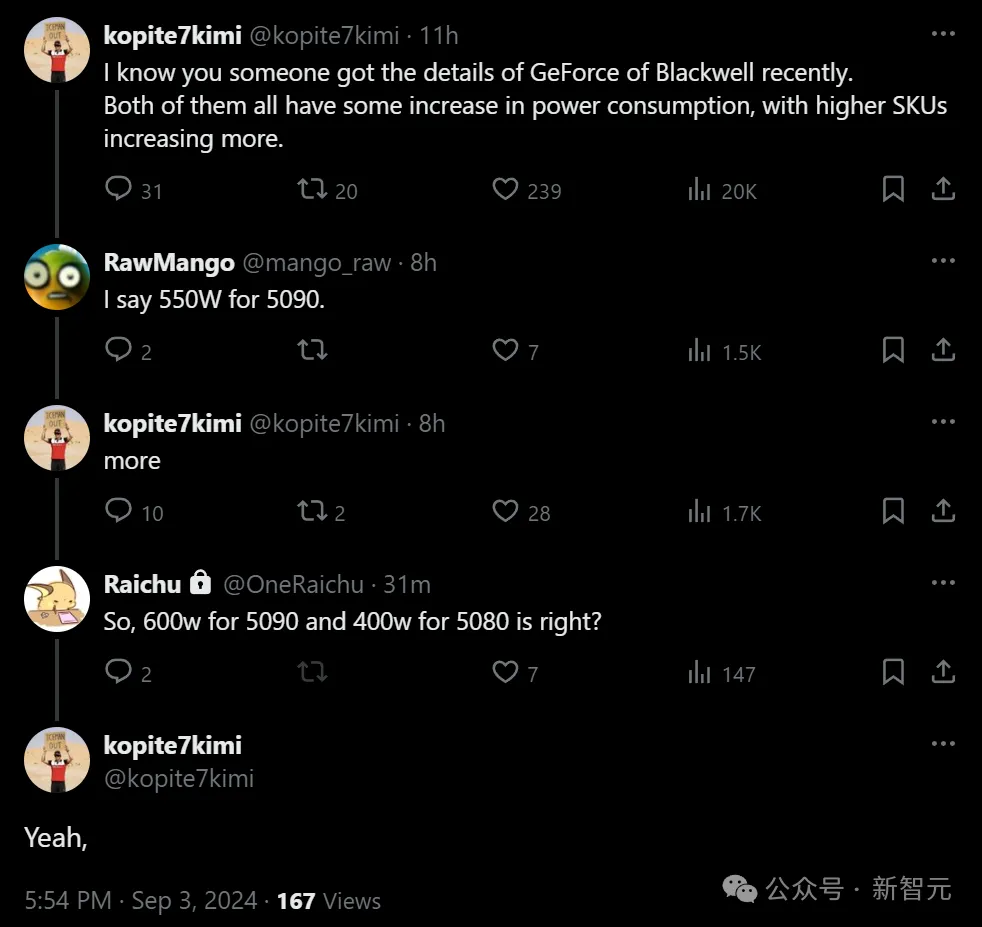
根据最新泄露的数据,英伟达GeForce RTX 5080的功耗或将提升至400W,并在部分性能上达到RTX 4090的110%!而RTX 5090的功耗预计将增加150W,达到惊人的600W。

用英伟达的GPU,但可以不用CUDA?PyTorch官宣,借助OpenAI开发的Triton语言编写内核来加速LLM推理,可以实现和CUDA类似甚至更佳的性能。

涌现(Emergence),是生成式AI浪潮的一个关键现象:当模型规模扩大至临界点,AI会展现出人类一般的智慧,能理解、学习甚至创造。