深度|NVIDIA旗舰GPU对比:H100、A6000、L40S、A100在训练与推理中的应用
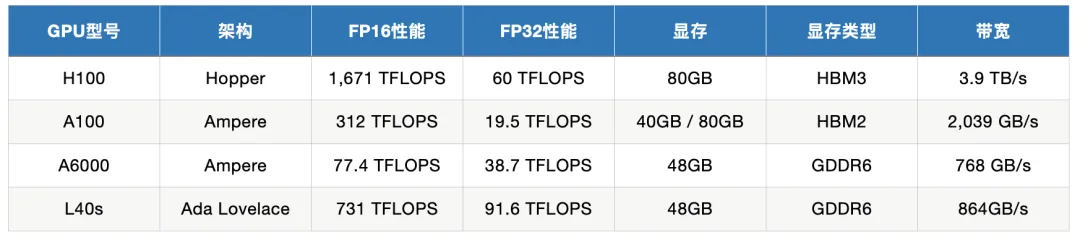
深度|NVIDIA旗舰GPU对比:H100、A6000、L40S、A100在训练与推理中的应用通过深入分析这些 GPU 的性能指标,我们将探讨它们在模型训练和推理任务中的适用场景,以帮助用户在选择适合的 GPU 时做出明智的决策。同时,我们还会给出一些实际有哪些知名的公司或项目在使用这几款 GPU。
来自主题: AI资讯
10681 点击 2024-10-31 11:55
 搜索
搜索
通过深入分析这些 GPU 的性能指标,我们将探讨它们在模型训练和推理任务中的适用场景,以帮助用户在选择适合的 GPU 时做出明智的决策。同时,我们还会给出一些实际有哪些知名的公司或项目在使用这几款 GPU。

通过自己照片训练一个自己专属的FLUX模型,利用好FLUX的超强生图能力,从此想生成啥生成啥,实现写真自由
文章详细讨论了如何确保大型语言模型(LLMs)输出结构化的JSON格式,这对于提高数据处理的自动化程度和系统的互操作性至关重要。

近期,港中大(深圳)联手趣丸科技联合推出了新一代大规模声音克隆 TTS 模型 ——MaskGCT。该模型在包含 10 万小时多语言数据的 Emilia 数据集上进行训练,展现出超自然的语音克隆、风格迁移以及跨语言生成能力,同时保持了较强的稳定性。MaskGCT 已在香港中文大学(深圳)与上海人工智能实验室联合开发的开源系统 Amphion 发布。

让大模型能快速、准确、高效地吸收新知识!

TimeMixer++是一个创新的时间序列分析模型,通过多尺度和多分辨率的方法在多个任务上超越了现有模型,展示了时间序列分析的新视角,在预测和分类等任务带来了更高的准确性和灵活性。

Janus 是 DeepSeek AI 开发的一个先进的多模态理解和生成框架,它通过创新性地解耦视觉编码路径来应对多模态理解和生成任务之间的需求冲突。

PUMA(emPowering Unified MLLM with Multi-grAnular visual generation)是一项创新的多模态大型语言模型(MLLM),由商汤科技联合来自香港中文大学、港大和清华大学的研究人员共同开发。它通过统一的框架处理和生成多粒度的视觉表示,巧妙地平衡了视觉生成任务中的多样性与可控性。

把平均成功率从 50% 拉到了 100%。

在当前内卷严重的实时目标检测 (Real-time Object Detection) 领域,性能与效率始终是难以平衡的核心问题。绝大多数现有的 SOTA 方法仅依赖于更先进的模块替换或训练策略,导致性能逐渐趋于饱和。