零成本突破多模态大模型瓶颈!多所美国顶尖高校华人团队,联合推出自增强技术CSR
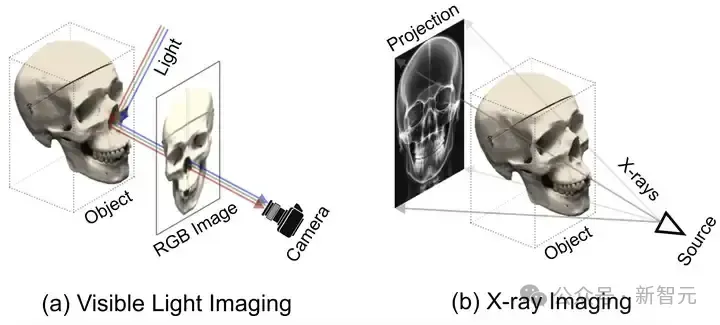
零成本突破多模态大模型瓶颈!多所美国顶尖高校华人团队,联合推出自增强技术CSR现有多模态大模型在对齐不同模态时面临幻觉和细粒度感知不足等问题,传统偏好学习方法依赖可能不适配的外源数据,存在成本和质量问题。Calibrated Self-Rewarding(CSR)框架通过自我增强学习,利用模型自身输出构造更可靠的偏好数据,结合视觉约束提高学习效率和准确性。
来自主题: AI技术研报
7901 点击 2024-06-21 14:05