

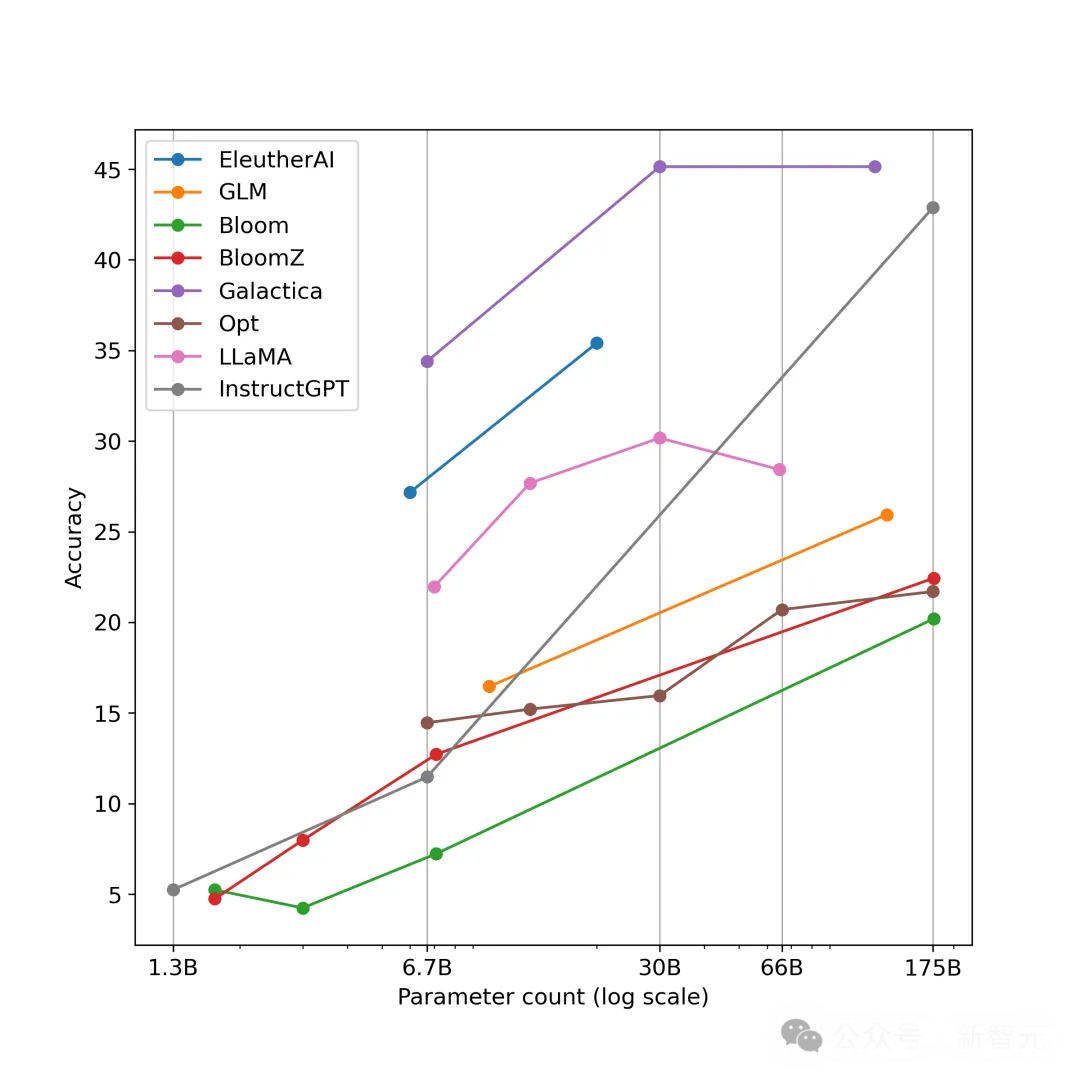
答案抽取正确率达96.88%,xFinder断了大模型「作弊」的小心思
答案抽取正确率达96.88%,xFinder断了大模型「作弊」的小心思大语言模型(LLM)的迅速发展,引发了关于如何评估其公平性和可靠性的热议。
来自主题: AI技术研报
11198 点击 2024-06-17 19:37
大语言模型(LLM)的迅速发展,引发了关于如何评估其公平性和可靠性的热议。

当前主流的视觉语言模型(VLM)主要基于大语言模型(LLM)进一步微调。因此需要通过各种方式将图像映射到 LLM 的嵌入空间,然后使用自回归方式根据图像 token 预测答案。

通过算法层面的创新,未来大语言模型做数学题的水平会不断地提高。

最近两天,一篇入选 ACL 2024 的论文《Can Language Models Serve as Text-Based World Simulators?》在社交媒体 X 上引发了热议,就连图灵奖得主 Yann LeCun 也参与了进来。
来自浙江大学和伊利诺伊大学厄巴纳-香槟分校的研究者发表了他们关于「表格语言模型」(Tabular Language Model)的研究成果
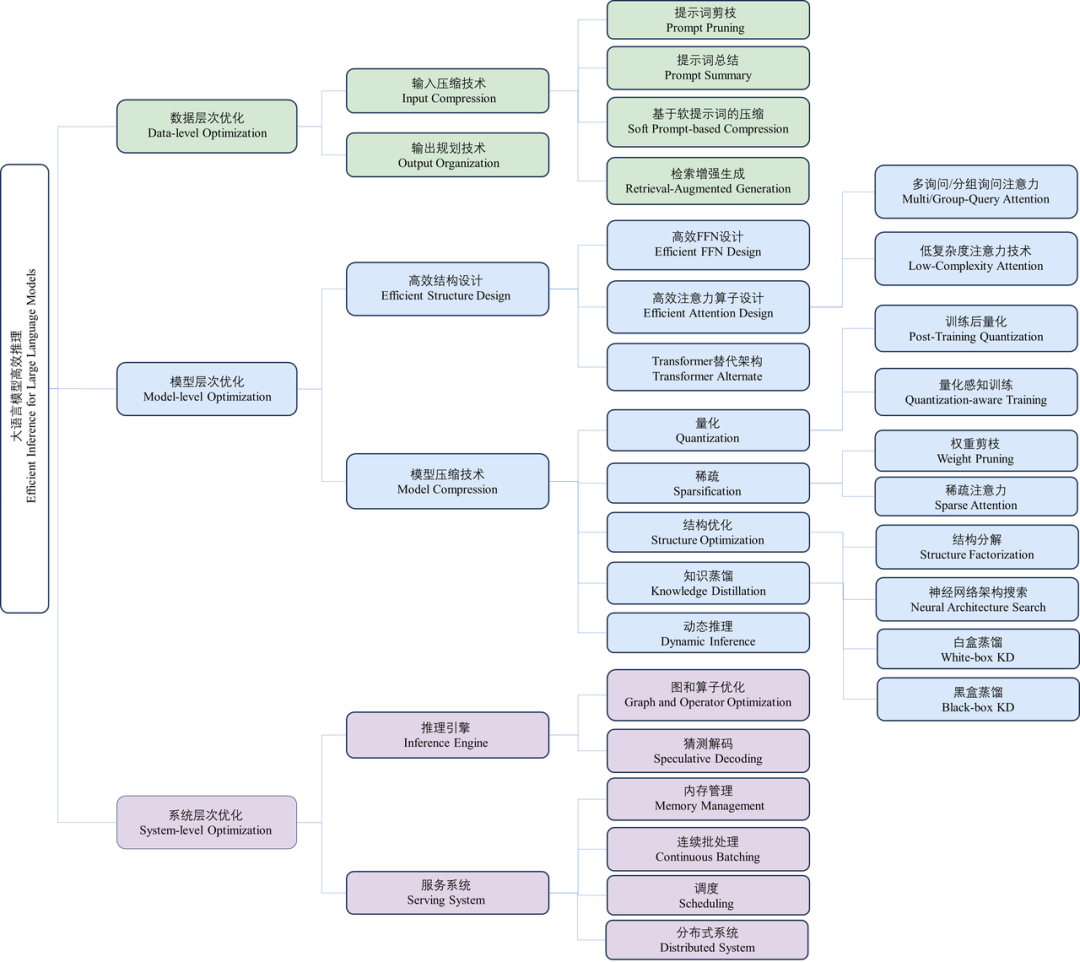
近年来,大语言模型(Large Language Models, LLMs)受到学术界和工业界的广泛关注,得益于其在各种语言生成任务上的出色表现,大语言模型推动了各种人工智能应用(例如ChatGPT、Copilot等)的发展。然而,大语言模型的落地应用受到其较大的推理开销的限制,对部署资源、用户体验、经济成本都带来了巨大挑战。

GPT-4o再次掀起多模态大模型的浪潮。

近些年,语言建模领域进展非凡。Llama 或 ChatGPT 等许多大型语言模型(LLM)有能力解决多种不同的任务,它们也正在成为越来越常用的工具。

大型语言模型(LLM)的一个主要特点是「大」,也因此其训练和部署成本都相当高,如何在保证 LLM 准确度的同时让其变小就成了非常重要且有价值的研究课题。

360 度场景生成是计算机视觉的重要任务,主流方法主要可分为两类,一类利用图像扩散模型分别生成 360 度场景的多个视角。由于图像扩散模型缺乏场景全局结构的先验知识,这类方法无法有效生成多样的 360 度视角,导致场景内主要的目标被多次重复生成,如图 1 的床和雕塑。