

RAG还是微调?微软出了一份特定领域大模型应用建设流程指南
RAG还是微调?微软出了一份特定领域大模型应用建设流程指南检索增强生成(RAG)和微调(Fine-tuning)是提升大语言模型性能的两种常用方法,那么到底哪种方法更好?在建设特定领域的应用时哪种更高效?微软的这篇论文供你选择时进行参考。
来自主题: AI技术研报
6285 点击 2024-02-17 12:09
检索增强生成(RAG)和微调(Fine-tuning)是提升大语言模型性能的两种常用方法,那么到底哪种方法更好?在建设特定领域的应用时哪种更高效?微软的这篇论文供你选择时进行参考。

最近来自香港科技大学(HKUST)、南洋理工大学(NTU)与加利福尼亚大学洛杉矶分校(UCLA)的研究者们提供了新的思路:他们发现大语言模型如 ChatGPT 可以理解传感器信号进而完成物理世界中的任务。该项目初步成果发表于 ACM HotMobile 2024。
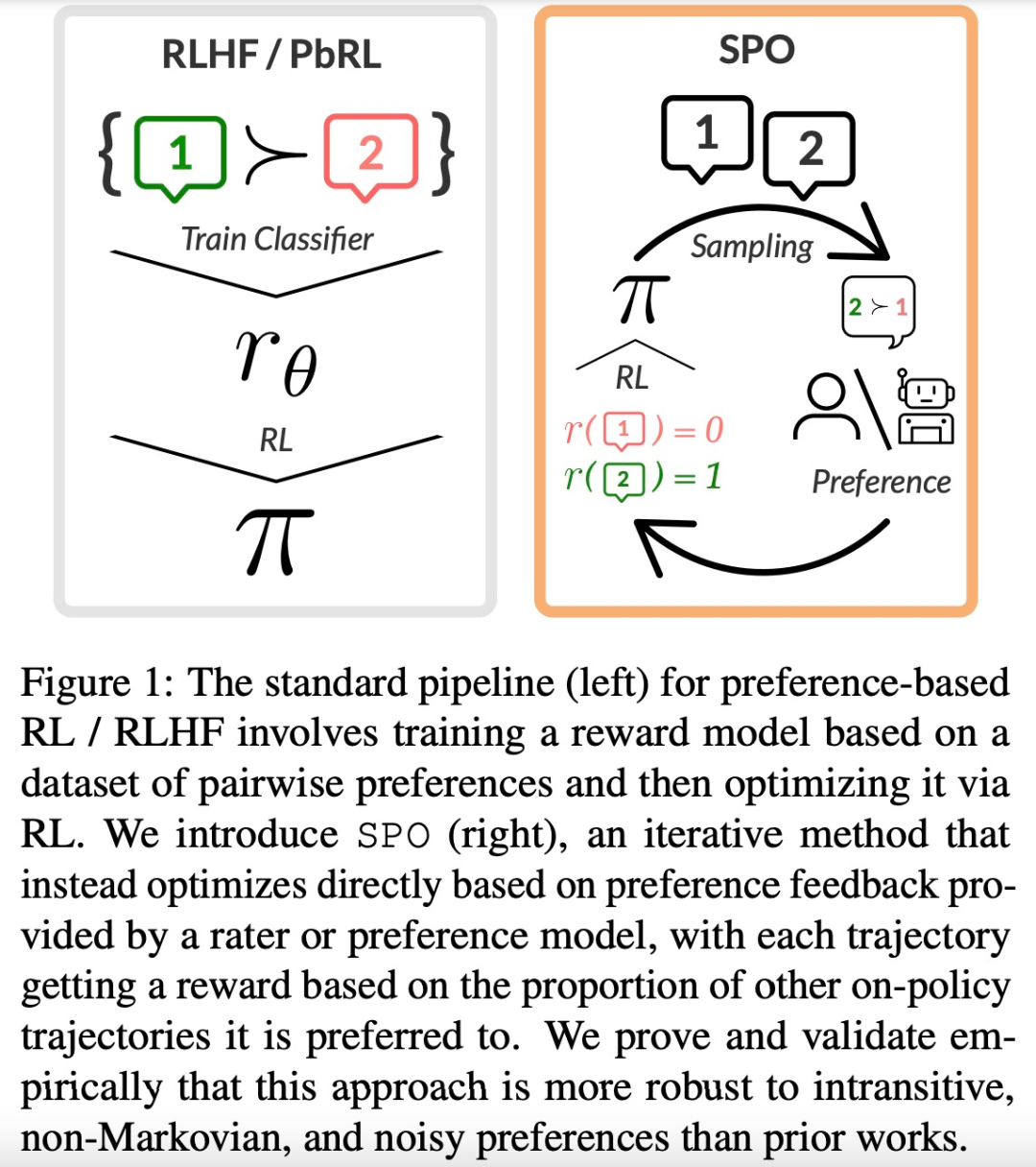
大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。

2023 年,大型语言模型(LLM)以其强大的生成、理解、推理等能力而持续受到高度关注。然而,训练和部署 LLM 非常昂贵,需要大量的计算资源和内存,因此研究人员开发了许多用于加速 LLM 预训练、微调和推理的方法。
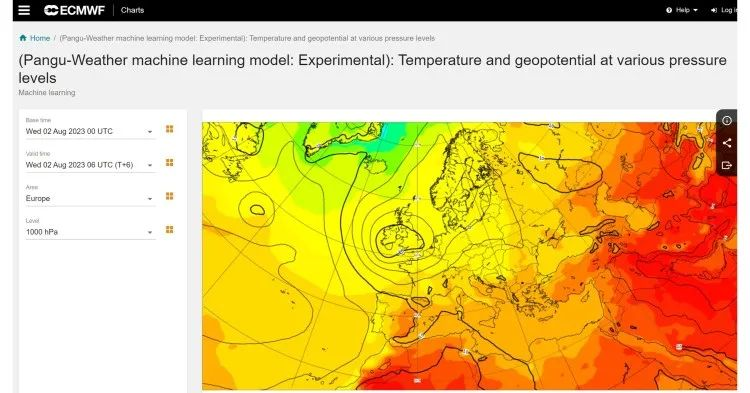
当前有不少的大语言模型已经拥有了高准确度的天气预测能力。相比传统的天气预测技术,这些被称为大型 AI 气象预测模型(Large AI Weather forecast Model,LWMs)在极端天气预测方面有着更好的效果。

去年 6 月,JetBrains 宣布所有基于 IntelliJ 的 IDE 和 .NET 工具都将集成一个新功能:AI 助手(AI Assistant)——该功能由 JetBrains AI 服务提供支持,可连接不同的大语言模型(LLM),并表示会将它整合到 IDE 的核心工作流中。
「天工AI」国内首个MoE架构免费向C端用户开放的大语言模型应用全新问世。
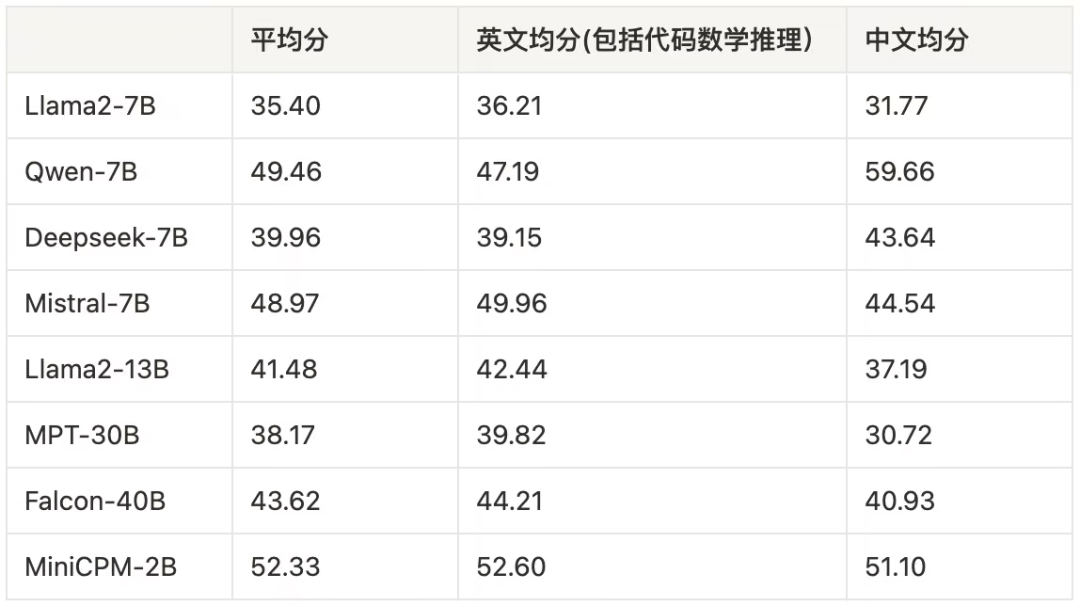
MiniCPM 是一系列端侧语言大模型,主体语言模型 MiniCPM-2B 具有 2.4B 的非词嵌入参数量。

随着多模态大语言模型(Multimodal Large Language Model,MLLM)的快速发展,以 MLLM 为基础的多模态 agent 逐渐应用于各种实际应用场景中,这使得借助多模态 agent 实现手机操作助手成为了可能。

加拿大滑铁卢大学的研究人员在《Nature Computational Science》发表题为《Language models for quantum simulation》 的 Perspective 文章,强调了语言模型在构建量子计算机方面所做出的贡献,并讨论了它们在量子优势竞争中的未来角色。