# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

现在人工智能领域面临的最大挑战是广义的具身智能,即使你并不特别关心大脑本身……
-原本的图灵测试只关注行为层面,即计算机是否能够欺骗人类。而在卡内基梅隆大学助理教授Aran Nayebi看来,当前的神经人工智能领域试图构建的是一个能够模拟人类行为输出、人类功能或生物学功能的模型,这个模型并非直接模仿人类本身。他提出,我们要将人工系统与我们所构建的生物系统进行内部表征的比较,还有用来测试这些系统的物种之间,以及这些物种种群的不同个体之间的比较。
Aran认为“内部表征”仅仅指神经网络或任何其他系统中群体级别的活动,并不涉及心灵哲学或其他哲学概念。整合他所学的大部分知识,Aran最终尝试开发出自主智能体来执行我们希望它们执行的任务,它至少在某种程度上要类似于我们大脑执行任务的方式。本文讨论了他正在进行的计划,即“逆向设计人类智能,以构建实用的认知架构”。
由此,文章还讨论了Aran提出的一个观点:至少在神经人工智能(NeuroAI)领域,需要对图灵测试进行升级。图灵测试是艾伦·图灵(Alan Turing)提出的一个著名基准测试,某种程度上像是一个思想实验或玩笑。众所周知,如果一台计算机能把人骗得相信它是人类,那么它就通过了图灵测试,该计算机就具备思考能力。多年来,人们一直在争论这是否是一项有效的测试,但每当我们试图评估一个人工系统是否具备思考能力,或者这是否是一个优秀的人工系统时,它仍是人们不断援引的标准。

保罗·米德布鲁克斯
Paul Middlebrooks
卡内基梅隆大学助理研究员,播客“Brain Inspired”主理人
他在匹兹堡大学马克·索默实验室获得认知神经科学博士学位。随后在范德堡大学Jeffrey Schall, Geoff Woodman, and Gordon Logan实验室从事博士后研究,研究运动皮层和基底神经节神经群活动如何影响自由行为小鼠的自然行为。

阿然·奈耶比
Aran Nayebi
卡内基梅隆大学机器学习部门助理教授
卡内基梅隆大学机器学习系的助理教授,神经科学研究所的核心教员。致力于神经科学和人工智能的交叉领域,对动物智能进行逆向工程,并构建下一代自主智能体。Aran此前是麻省理工学院ICoN博士后研究员,主要与杨光裕和Mehrdad Jazayeri合作。在斯坦福神经科学项目完成了博士学位,由Dan Yamins和Surya Ganguli共同指导。

保罗·米德布鲁克斯:Aran,我刚查了一下。Dan Yamins 是本播客第7期的嘉宾,那感觉好像是一百年前的事了(2018年),而你是在 Dan Yamins 的实验室完成学业的,现在就在这里了,看起来你进展得非常快啊。
阿然·奈耶比:是的,我也觉得时光飞逝。我2016年在Dan那里开始攻读博士,2022年毕业,也就是两年前,在他和Surya的指导下完成了学业。
保罗·米德布鲁克斯:你是说Surya Ganguli。这样不妙啊,因为我好像也是2016年拿到博士学位的,可你看,你现在远远走在我前面了。
阿然·奈耶比:嗯,这一路肯定是经历了不少,这一点毫无疑问。


▷左:Dan Yamin,吴蔡神经科学研究院学者,斯坦福大学计算机科学和心理学副教授,NeuroAILab:https://neuroailab.stanford.edu/;右:Surya Ganguli,斯坦福大学教授,负责斯坦福大学的神经动力学和计算实验室:https://med.stanford.edu/scsnl,谷歌客座研究教授。因神经网络和深度学习工作闻名,他的目标是逆向工程神经元和突触网络如何在多个空间和时间尺度上协作,以促进感觉知觉、运动控制、记忆和其他认知功能。
保罗·米德布鲁克斯:是吗?
阿然·奈耶比:这些年变化太快了,至少在人工智能领域是这样。当我回忆一切开始的时候,感觉像是在谈论很久以前的旧时光,但实际上并没有过很久。在我开始读博的时候,TensorFlow还没发布,我们用的是Theano,而Keras刚刚问世。所以作为一名在读硕士,我还为Keras做过一点贡献,挺有趣的。
保罗·米德布鲁克斯:你的背景是数学和计算机科学,对吗?
阿然·奈耶比:对,是的。我的本科专业是数学和符号系统(Symbolic Systems),在斯坦福这基本上就是认知科学专业。我一直对大脑很感兴趣,只是当时不知道该如何投入这份兴趣。后来我读了人工智能方向的计算机科学硕士,算是让自己开始向一个偏实证的领域转型。那时候,我记得我在开始读博之前,非常荣幸地拜访了Bill Newsome。他邀请我到他家里坐了坐。当时我有点迷茫:“我不知道该继续研究神经科学还是机器学习。”他建议我应该先做机器学习,以后再回到神经科学。他的想法是,应该先学会机器学习领域正在发生的那些工具,然后再将它们应用到大脑研究上。反正大脑又不会跑掉。当然他并没有明确这样说,但大致就是这个意思,我也确实照他说的做了。
保罗·米德布鲁克斯:你觉得自己现在算是回归神经科学了吗?还是在回归的过程中?
阿然·奈耶比:可以这么说。特别是我现在建立了自己的实验室,我非常希望将实验室扎根于神经科学和人工智能的交叉领域。我们在卡内基梅隆大学(CMU)把自己的实验室称作“NeuroAI实验室”,目前还没想到更好的名字。
保罗·米德布鲁克斯:那么你打算从哪些方面扎根于神经科学?这意味着什么?
阿然·奈耶比:这是个很好的问题。我认为,从某种层面上来说,我们对人工智能或者认知科学感兴趣的许多问题,归根结底都是关于我们自身智能的疑问。比如你想想,为何 GPT-4 这样的模型表现如此出色?从很多方面来看,这其实是一个科学问题,即为什么规模的扩大能带来涌现能力?为什么这些系统在某种程度上拥有更好的世界模型?这些都是科学问题。而在我看来,原先一直是由认知科学来试图回答这些问题。而现在,在某种意义上,这些问题很大程度上正通过由大量经验驱动的、甚至有些偶然的工程试验得到解答。
保罗·米德布鲁克斯:没错。
阿然·奈耶比:现在真是非常有意思、非常有趣的一个时期。我想实际上这意味着我们构建的许多模型都希望能够拿来与大脑本身或其行为进行比较和测试。我将这些模型视为认知模型,也就是认知科学的一种表达方式,这些认知模型也确实能够有效运作。而在很长一段时间里,至少在我2016年入行时,认知科学方面的模型明显落后于工程领域。
有趣的是,就像你刚才提到的,我们常谈论马尔(David Marr)的三层次理论(计算层次、算法层次、实现层次)。也许现在我们已经解决了计算层次的任务,并对某些问题有了优秀的算法近似。现在我们可以重新审视实现层次,回过头用真实的神经数据或行为数据评估这些模型,并以此作为驱动力。这很奇妙,因为原本认知科学就试图这样做,但随着AI的爆发式发展,它逐渐被甩在了后面。而现在,它又以一种奇怪的方式卷土重来——我们正尝试让这些庞大的、原本为完成工程任务而构建的模型来适配到神经数据和人类行为上。
保罗·米德布鲁克斯:我在邮件里问你这次对话该聊些什么时,你提到了图灵测试。我们之后会聊一聊这个,但你还提到了David Marr的层次理论。我看到时心想:“这是在挖苦我吗?” 因为我在节目里经常强调Marr的层次理论有多棒。然而我可能把情况过于简单化了,或者说可能曲解了某些观点,但我一直觉得,在AI/机器学习圈子里,Marr的理论层级并不受重视,人们也不去思考它们。但像你以及许多神经科学和人工智能领域的人现在开始谈论这些层次了。我不知道这是否属实,你也是这种感觉吗?
阿然·奈耶比:我觉得你说的有道理。我想即使在神经科学内部,也存在两派。确实有一派认为Marr的层次理论无关紧要或者干脆就是错的。大约五年前有一篇论文*,提议类似“抛开Marr的三层次,将其简化至两个层次”之类的东西。同时也有一派认为Marr的层次框架是最棒的。我在邮件中说过,我更倾向于前一种观点。我认为Marr的框架也许有点太受限了,或者换种说法,也许是不够受限,就是它缺了点什么。我觉得如今无监督学习和自监督学习的新方法,赋予了我们某些以前没有的东西,来弥补原理论的缺失,帮助人们更细致地理解层级理论的复杂性。

▷Corey J. Maley认为,若表征天然依赖其物理载体,那么学习过程(尤其是无需外部标签、紧密耦合统计结构与物理结构的无监督/自监督范式)就能直接在这一“实现-表征层”上发生,而不必清晰区分抽象符号与底层实现。于是经典的三层模型就被压缩成 “计算层 + 实现-表征层” 两层结构。来源:Maley, C.J. The physicality of representation. Synthese 199, 14725–14750 (2021). https://doi.org/10.1007/s11229-021-03441-9
我可以举个例子。我在邮件里也提到了,以往大家一直关注是计算层面的问题,就像是“任务是什么?给出一个奖励,让模型去完成任务”。过去十年里,在神经科学领域,每个人都是这么做的。我认为这这是合理的,因为许多进展正是在此发生。这有点像计算机视觉领域因ImageNet数据集引发的关键突破点。
但我认为,这种聚焦带来了一个错误印象,好像算法层次无关紧要或者不值得考虑。我想其中的微妙之处或需要附加说明的是,我们过去之所以不必太关心算法层次,是因为当时的模型太差、规模太小,反正怎么都匹配不上大脑。
过去你随便给模型一个任务,它表现都非常差,以至于架构怎样根本无关紧要——反正都不行。
保罗·米德布鲁克斯:没错。
阿然·奈耶比:我们现在正处在一个有奇妙的阶段,像GPT-4这样的模型涌现出了很多特性。至少对我而言,架构似乎将开始变得更为重要。现在,有了这些基础模型,人们开始憧憬下一步的飞跃,它是否需要某种更复杂的东西?可能是对的,也可能不是。这也许只是需要更多的数据和更大的规模,仅此而已。但我认为我们正处于一个神经科学可以发挥作用的关口。我觉得当前我们面临各种有意思的架构选择和数据选择。而架构是算法层次的一部分。架构加上自监督学习,在我看来就属于算法层次的范畴。
保罗·米德布鲁克斯:当你说“架构”的时候,你指的是诸如模块之类的东西吗?我们稍后会谈到你的那些模块。你所说的架构是指如何将系统组装在一起吗?
阿然·奈耶比:是的。或者例如循环与前馈的对比,空间与卷积(convolution)的对比,以及卷积与基于令牌的架构(token-based architecture)的对比,例如ViT(Vision Transformer)之类的技术。这些都属于架构选择的一部分。
保罗·米德布鲁克斯:是的。正如你所说,10年前每个人都觉得:“我们只需要找到神奇的学习规则和目标函数,架构则无关紧要。”但现在有了这些庞大的基础模型,人们开始想:“等等,也许我们如何拼装这些结构还真很重要。”
阿然·奈耶比:是的。确实有这种倾向,但我觉得大家仍然低估了架构的重要性。也许我是错的,也许人们确实在认真考虑架构。我只是记得有段时间大家都觉得只要找到正确的自监督损失函数就行了,那样就万事大吉了。
我认为这是个组合问题,正确的架构加上目标函数再加上数据的正确组合。这三者都重要。如果这三个中有任何一个不合适,你就得不到想要的。
神经科学可以在这三个方面都提供帮助,因为神经科学基本上就是关于架构、目标函数和数据的。我们有数据,人们一直在测量各种东西。我们可能不知道大脑的目标函数是什么,也许只是生存,也许就是“尽一切所能”,但我们可以从中汲取某种洞见。至于架构,我认为显然我们可以从大脑那里获取大量灵感。这就是我认为我们可以将AI研究扎根于神经科学的地方。
保罗·米德布鲁克斯:你提出的模块之一是“世界模型”(world model)。在我们深入讨论这些模块之前,你认为“世界模型”等同于内部表征(internal representations)吗?还是你认为那是另外的概念?
阿然·奈耶比:我觉得世界模型是内部表征的一部分。我的理解是,世界模型包含着内部表征,或者说它是承载内部表征的那个东西。
保罗·米德布鲁克斯:这些问题是不是促使你开始更加关注你所谓的Marr算法层次,而不是Marr的三层次理论,对吧?过去10年里,每个人都专注于计算层次,AI关注的就是这一层次。例如,你和许多人都写过类似的话:“啊,这些模型之所以表现得这么好,是因为我们给了它们一个目标、一个任务。”对吧?那就是计算层次,也就是模型需要完成的任务。然后算法层次,即它们在算法上如何实现这个目标,相对就没那么重要了,因为它们可以自己学会该过程,这也是这些模型如此出色的原因。至于实现层次(实现细节),谁在乎呢?只要你随便塞点什么进去,最终都会产生智能行为。这些是不是促使你更关注算法层次的原因?
阿然·奈耶比:是的。我甚至可以把你刚才说的套用到神经人工智能领域来表述一下:计算层次对应的是任务,而算法层次不仅涉及架构,也包含任务与架构之间的相互作用。在某些情况下,我认为不光是要设定正确的目标,也不仅是找出最适合的自监督目标,比如下一词预测或者对比学习之类的本身具有进步性的技术,还需要找出与那种数据模态良好契合的架构。
我认为使用Transformer或这类基于token(令牌)的范式非常有前景,因为它有点模态无关。换言之,它具备通用性,只需替换不同数据,在此通用性下,并非所有感知系统都以相同方式运作,它们之间存在大量共享的解释方差。我认为未来若想提升模型在直觉物理的能力,可能需要更精细化处理视觉与具身化输入的处理方式或使其令牌化。这些输入可能完全不同于语言。这与人类大脑中的情况一致:语言区域是后来进化出来的,并且在拓扑上与视觉皮层有些不同。
保罗·米德布鲁克斯:你的那些模块里目前还没有语言模块,对吧?
阿然·奈耶比:对,没错。
保罗·米德布鲁克斯:你还关心跨物种的比较,考虑到人类是唯一使用语言的物种,语言模块可能不是你的首要目标。
阿然·奈耶比:没错。我想这或许也是为什么我认为我们内心存在一种核心的底层算法诉求,即希望这些智能体能够更好地理解世界。动物当然无需语言就能构建起它们的世界模型,而这已经非常不易了。这也涉及到为视觉语言模型(VLMs)设计一种提示语言,而不是那种随机图像令牌处理方式。我认为此方式能更贴近动物具备的视觉智能,这正是当前架构所需改进之处。
从宏观上说,世界模型是我的第二号模块,还有感知模块、规划模块等,对于规划模块,我不确定这个模块应该算第三号模块还是什么。
保罗·米德布鲁克斯:好的,我们还是直接进入正题吧。你提出了这些模块,包括感知模块、世界模型、规划模块,还有一个行动模块。能不能请你从你的角度描述一下这些模块分别是什么,以及它们可能如何组合在一起工作?
阿然·奈耶比:当然可以。我想这并不是我们独有的观点,许多人一直在思考如何构建更通用的人工智能,也就是开箱即用、能适应多种情况的智能体。我认为关键在于,当我们看待人们在强化学习或有监督学习中所做的许多测试时,它们大多局限于单一任务。但是当你观察动物(即使是老鼠)的行为时,它们一生中可以执行许多不同的任务。它们不会固守单一任务后便彻底放弃,再也不涉足其他行为。
为了设计出能够执行多于一个任务、甚至很多任务,并且还能即时指定新任务的系统,我们需要跳出“一个模型对应一个任务,完成后就再训练另一个模型对应另一个任务”的模式。我一直在想:要让一个模型可以执行多个任务,并能够快速适应指定的新任务,需要什么?从某种程度上说,这类似于元学习(meta-learning),但我认为现有方法稍显不足的是结构性。我刚才列出的感知、世界模型、规划和行动这几个模块,我认为代表了大多数动物所具备的四个关键结构要素。
换一种更简单的说法,作为世界上的动物,你会有感官输入,视觉、听觉、触觉,可能还有嗅觉。大多数动物都具备这些感官的某种组合。接下来,它们会据此构建某种世界模型,即一种内部状态,用于跟踪所发生的事情,这可能包括记忆、代理所处的位置等等。然后是规划,也就是在某个潜在空间甚至物理空间中,如何从A点到达B点。接着你需要输出一个行动。然后不断重复这个过程。如果你希望一个动物或智能体能够执行许多任务,那么这四个要素缺一不可。如果仅用单一模型同时处理所有环节,也许在某些简单情况下能行,但面对更复杂的事情,这种结构可能还不够。
保罗·米德布鲁克斯:听起来光用一个语言模型可不够啊。
阿然·奈耶比:嗯,是啊。也许几年后证明我错了,或许到时候单靠语言模型就可以做一切。但我持怀疑态度。
保罗·米德布鲁克斯:对我来说,感知模块似乎就是指视觉、听觉、触觉等等。但听起来你好像设想有一个通用的感知模块,它包含视觉、听觉、触觉等各种感官,而不是分别有独立的视觉模块、听觉模块等等。是这样吗?
阿然·奈耶比:是的,可以这么说。我还没有真正考虑过要把不同感官再细分成独立模块。这更像是把所有感官输入通过一个漏斗汇聚到一个内部表征上。当然,也可能需要分开的感官模块。眼下,我实现的只是视觉部分,也就是用一个ResNet之类的网络,将视觉输入转化为内部状态。我们还没有扩展到听觉之类的其他感官。
保罗·米德布鲁克斯:有些人谈到多模态时会说 “必须针对不同模态独立的数据流。”但也有人说:“不不不,我们需要一个能处理所有模态的统一模型。”听起来你似乎更倾向于后者,至少目前在感知模块上是这样。
阿然·奈耶比:至少现在我是这么做的。很大程度上也是出于方便考虑。不过,这样做是否恰当确实值得讨论。毕竟在大脑中,并不存在一个模型包办所有感官处理,而是不同感官有各自独立的通路。不过它们确实会在后期的某个阶段趋于汇合。我认为,你可以在人工模型中让各感官分开处理,然后在后期将它们收敛。我们目前还没有明确地实施这个方案,也许最终会这么做,但目前是统一的。
保罗·米德布鲁克斯:你会如何描述“世界模型”?是不是可以理解为一种包含记忆等内容的潜在状态?
阿然·奈耶比:是的。我将世界模型理解为智能体的对世界的内部模型。也就是智能体基于所有感官输入和自身行为历史,形成对世界的理解。在实现上,它可以表现为一个RNN(循环神经网络)的状态,或者转换器(Transformer)的状态,这个状态会随着所有感官信息和动作历史不断更新。我们可将其视为一个潜在状态。然后,如果考虑“规划”的本质,就是模型中那个以该潜在状态为输入,生成一系列动作序列或计划的部分。而行动模块则是将计划转化为真正的运动指令等实际输出的部分。
保罗·米德布鲁克斯:你能谈谈规划和行动之间的区别吗?这听起来有点微妙。如果你已有了计划,那么执行计划的过程就是行动。这两者其实可以是同一个东西,对吗?
阿然·奈耶比:是的,完全可以。你完全可以用一个模块同时负责规划和行动。我把它们分开的原因之一是,比如在大脑中,“规划模块”可能对应前额皮质之类的区域,而“行动”可能对应运动皮层或者脊髓之类的区域。在大脑里,它们显然是不同的部分。而实际上,在我现在的模型中,这两者是紧密结合在一起的,根本没有分开,目前是一个大的策略网络同时负责这两方面。但在概念上,我觉得将它们分开是有意义的。因为未来如果我们想要一个更好的规划模块,或者想要一个更好的行动模块,就可以替换对应部分。分开之后就有更大的灵活性,比如,一个模块负责规划行动序列,而另一模块将该计划转化为低级指令输出。
保罗·米德布鲁克斯:如果你要把它们分开,那规划模块似乎会将计划逐步输出到工作记忆中,然后行动模块从工作记忆中读取这个计划并执行。
阿然·奈耶比:完全正确。我想这是可以实现的方式之一。
保罗·米德布鲁克斯:这样模块边界就很清晰了。但正如你所说,你目前用的是一个大的策略网络囊括了所有功能。
阿然·奈耶比:是的,没错。
保罗·米德布鲁克斯:你一直在做的一件事是,将人类和小鼠的表现与一些模型进行比较,对吗?能否请你描述一下你为什么选择这种组合,以及你发现了什么?
阿然·奈耶比:这其实是我的博士项目的一部分*。我当时由Dan Yamins和Nick Steinmetz共同指导。Nick Steinmetz是一位系统神经科学家,他记录了小鼠视觉皮层的大量神经元活动,是艾伦研究所(Allen Institute)Mindscope项目的负责人之一,这个项目是“脑天文台”(Brain Observatory)项目的延续。他们同时记录成千上万个神经元的活动。我们当时在想:“好吧,我们可以用这些数据做什么?我们能构建什么样的模型?”
那时候,自监督学习模型还不太好用,所以我们当时构建的是自动编码器之类的模型。后来SimCLR出来了,于是我们就决定试试看SimCLR,一种用于图像的对比学习模型。我们构建了这些自监督视觉模型,让它们进行训练。其中我们还构建了监督模型,因此同时拥有对比模型和监督模型,并用图像数据训练它们。然后我们想看看,它们与小鼠视觉皮层的匹配度如何。这个思路其实类似于以前人们在灵长类动物上的研究。以前有针对猴子视觉系统的研究发现,用ImageNet训练的模型可以很好地模拟灵长类视觉系统。我们想看看,如果对小鼠做类似的事情,会得到什么结果。
结果大致是,我们发现那些对比学习模型,即SimCLR模型,是自监督的,它们与小鼠视觉皮层的匹配度远远高于被监督模型的匹配度。这可能是首次有人证明,在至少某种动物身上,自监督模型能够更好地匹配其神经数据。有趣的是,与此同时,好像是Tiago Marques和Ethan等人在灵长类那边做了类似的研究,也发现自监督学习模型比有监督模型表现更好。于是大家合在一起形成了一个有趣的结论:“哦,也许大脑本身也是在进行自监督学习,它并不仅仅执行那些任务驱动的学习。”
*Nayebi A. et al., 2023, PLOS Computational Biology “Mouse visual cortex as a limited-resource system that self-learns an ecologically-general representation”
不过这里有一些需要注意的地方。我们在论文中也提到了。其中之一就是:在记录这些数据时,小鼠并没有执行任何特定任务。它只是被动地观察。正因为是被动观看,所以没有任务目标的自监督模型可能比试图完成任务的有监督模型更契合这种情境。我想关于“自监督是否一定优于有监督”这个命题,目前还不能下最终定论。有大概四五篇论文都表明在这种被动情境下,自监督模型看起来表现更好,因此我们也只能说在被动的情境下,自监督模型似乎更胜一筹。但如果动物在执行任务,情况可能就不同了。这是其中需要细分考虑的一点。
我们发现的另一件事,也就是你提到的人类与小鼠的部分,是我们发现小鼠的视觉皮层并不像灵长类视觉皮层的“缩小版”。它并不是简单的“迷你版视觉皮层”或类似那样的东西。它似乎有不同的表征模式。我们发现,如果你获取神经网络的响应,然后尝试解码动物所看到的图像,若用针对灵长类(比如 ImageNet风格)训练的模型去解码小鼠大脑活动,效果并不好。但是如果用小鼠自身的行为数据训练模型,去解码小鼠的大脑活动,效果就好很多。也就是说,它们的表征空间就是不一样的。这其实说得通,对吧?小鼠不需要区分人类关心的许多东西。它有自己所关心的那个世界。灵长类和人类所处的世界可能更相似一些,而小鼠所处的世界则有些不同。
保罗·米德布鲁克斯:这些结论是基于让小鼠和人类都看了一系列相同的图像得到的,对吗?
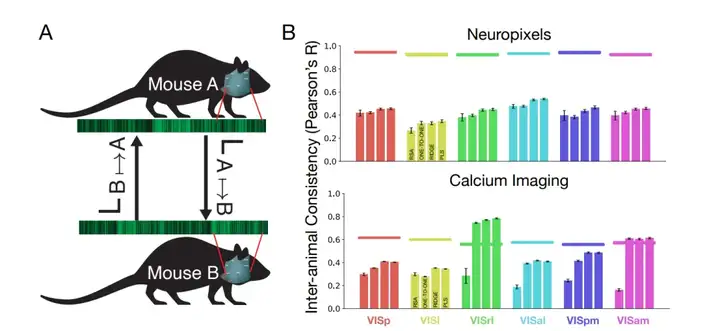
▷小鼠神经信息跨个体的一致性评估。图源:阿然·奈耶比的博士论文
阿然·奈耶比:是的。我们设计了一个类似心理物理学(psychophysics)的实验,基本上是让人类去完成和小鼠相同的任务,比如检测条纹对比度的变化,也就是当图案的对比度发生变化时按下按钮之类的。我们试图将他们的行为对应起来,并比较他们各自的神经网络响应和行为表现。这也是我们比较人类和小鼠的一种方式。我们也在想:我们的模型是否能够同时匹配人类和小鼠的大脑活动?或者说,它们之间是否存在某种权衡?我们发现,至少对于SimCLR这样的对比学习模型来说,在一定程度上可以同时匹配人类和小鼠的神经数据。并不是说你必须顾此失彼。我觉得这是很有意思的一点。也许这意味着,至少在算法层次上,两者有相似之处,即使实际的表征不同。
这给了我一些希望,虽然Marr说有三个层次,但也许在算法层次上存在某种通用的东西可能是相同的。我不确定。
保罗·米德布鲁克斯:当你说自监督模型与小鼠皮层更“匹配”时,这个“匹配”是指什么?是指神经网络与神经数据的相关性之类的衡量吗?
阿然·奈耶比:对,没错。具体做法是用线性回归,从网络的单元活动来预测神经元的数据,看看预测得有多好。这就是我们的“匹配”衡量方式。
保罗·米德布鲁克斯:所以在那种情况下,你们只看了小鼠的V1区域(初级视觉皮层)?
阿然·奈耶比:是的,当时看的就是V1,初级视觉皮层。
保罗·米德布鲁克斯:让我们聊聊你提出的图灵测试话题吧。图灵测试的问题出在哪里?为什么我们需要一个新的测试?
阿然·奈耶比:我并不确定我们是否真的需要一个全新的图灵测试。我的观点主要是针对神经人工智能领域的。我认为语境非常重要。在通用人工智能(AGI)或者其他目标,也许原始的图灵测试就是合适的,对此我并不是专家,所以我不会下定论。但在我们我们当前的研究背景下,我们的目标是构建更贴近大脑的模型,以类似动物的方式执行任务。我认为如果仅仅做行为层面的图灵测试,也就是看模型是否能像动物一样完成任务,这是不够的。因为模型在内部可能以完全不同的方式完成任务,只是碰巧输出结果相同。而这正是这里的关键区别。
如果我们的目标是模拟大脑,那我们就需要真正观察模型的内部,确保它们在内部机制上也相匹配。这包括要匹配内部表征,匹配内部动态。所以,可以说这是一个加了额外约束条件,强调模型内部也要匹配的图灵测试。这就是我观点的核心。

▷作者:Clive Head
保罗·米德布鲁克斯:是的,基本上就是一个“神经科学版的图灵测试”,对吧?
阿然·奈耶比:对,完全可以这么说。我记得 Jacob Reimer 有个很好的术语,好像叫“神经图灵测试”之类的,我忘了他的说法了。
保罗·米德布鲁克斯:不久前我和 Tiago Marques 聊过,他也非常强调这一点。他们有一个很好的示意图,展示了两个模型,它们的行为表现一样,但内部表征却非常不同。这很好地突出了这个问题的重要性。
阿然·奈耶比:完全正确。我认为这才是关键。其实这个道理显而易见的,也不是什么疯狂的新想法。
保罗·米德布鲁克斯:现在当我们看到不同模型能够有相似表现时,这个道理就显而易见了。但十年前,那时候所有模型表现都很糟糕。当时我们还顾不上考虑内部机制问题。
阿然·奈耶比:没错。十年前这不是个需要担心的问题,而现在是了。
保罗·米德布鲁克斯:你对于大型语言模型有没有什么认识?或者说,你有没有尝试从内部表征或其它方面对比过它们?
阿然·奈耶比:我没有从内部对比过大型语言模型。我们最近做了一个尝试,把这些模型的相似度矩阵,例如激活模式矩阵,与一些认知科学的数据做相关。但我们没发现任何结果,不过我们也没花太大力气去深入尝试。
关于语言模型的研究很有趣,因为我觉得它正处在一个分水岭,一方面它的性能已经非常好了,人们正尝试把它用于认知科学,一些人声称GPT-3具有“心理理论”(theory of mind)之类的能力。这非常有争议,也有些人说它没有这样的能力。我们知道它在某些方面表现优异。也有一些已知的不足,比如它在人类擅长的某些任务上表现不好。
我个人还没有从内部机制的角度仔细研究过它们。我知道其中存在许多有趣的结构现象。比如有一篇关于上下文学习(in-context learning)的论文指出,模型内部仿佛学会了一些学习算法,这听上去就很不可思议。人们正试图搞清楚这些事情。看起来,LLM似乎确实能学到一些算法层次的东西,而不仅仅是静态的输入输出映射。
这非常吸引人。我想在这方面还有很多工作要做。
保罗·米德布鲁克斯:我还有两个问题。第一个是:如果你现在可以打个响指,就得到解答任何一个你想问的问题,你会想问什么?也就是说,目前你头脑中最大的疑问是什么?
阿然·奈耶比:这个回答听起来会很基础,但我真希望我确切地知道大脑在优化的目标究竟是什么。如果我能直接看到大脑的损失函数,那就太好了。在我看来,这是能够解锁一切奥秘的关键。如果有人能告诉我,“大脑优化的就是 X、Y、Z 这些东西”,我就会觉得:“太好了,现在我知道该怎么做了。”对我来说,这就是核心问题。
保罗·米德布鲁克斯:这看似是个直接的问题,但确实无从作答啊。
阿然·奈耶比:是啊,完全没错。
保罗·米德布鲁克斯:另一个问题是:在你的职业生涯中,你觉得面临的最大障碍是什么?有没有什么是让你觉得“我不知道该怎么做到”的,非常具有挑战性的事情?
阿然·奈耶比:我觉得目前的话,每个人可能都会这么说,但我认为最大的障碍是计算资源。现在什么模型都是上亿甚至数十亿参数,要应对这个现实非常困难。我觉得这就是最大的瓶颈之一。还有一个障碍,我想不一定只是对我,而是对整个领域来说都是,就是如何对齐研究动机。从不同方面出发有很多各自的动机。学术界注重的是发论文等等;开放科学(Open Science)这些理念也总是在拉锯。这始终是一个挑战。
还有,我个人需要克制自己去追逐潮流的冲动。我觉得现在有太多的炒作周期(hype cycles)了,而保持独立思考非常重要,我想问问自己:“接下来十年我想致力于什么,什么样的研究可能真正有价值?”这点对我来说是个挑战,因为我很容易对各种新事物感到兴奋,所以我必须提醒自己:“专注一点,想想什么既有影响力又是你真正想做的。”我现在就在努力做到这一点。
保罗·米德布鲁克斯:这是个很好的回答。我也一直在为此挣扎。你看到一些新方向,会觉得我可以做这个,这会很有意义。但当另一个方向看上去也很有价值。你该把精力投入到哪边去?
阿然·奈耶比:我觉得这又回到了你第一个问题上:如果我知道了大脑优化目标是什么,那么我就知道努力的方向了。
保罗·米德布鲁克斯:说得也是。有了那个损失函数,你就知道要优化什么了。
阿然·奈耶比:没错,那样我敲敲代码就能搞定了(笑)。
*为了阅读体验,本文对听稿进行了适当的编辑。
原对话指路:https://www.thetransmitter.org/brain-inspired/aran-nayebi-discusses-a-neuroai-update-to-the-turing-test/
文章来自于“追问nextquestion”,作者“追问”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
