匿名模型Kivine外网刷屏,开发者们都在猜:这是Kimi-K3?
匿名模型Kivine外网刷屏,开发者们都在猜:这是Kimi-K3?这两天,大模型竞技场Arena上出现了一个新的匿名模型,代号Kivine。经过测试和对比,再结合此前Kimi-K2.5和K2.6的匿名代号“Kiwido”和“Kiwire”,越来越多的开发者们开始猜测这个匿名模型其实就是Kimi-K3。
来自主题: AI资讯
8781 点击 2026-07-16 20:21
 搜索
搜索
这两天,大模型竞技场Arena上出现了一个新的匿名模型,代号Kivine。经过测试和对比,再结合此前Kimi-K2.5和K2.6的匿名代号“Kiwido”和“Kiwire”,越来越多的开发者们开始猜测这个匿名模型其实就是Kimi-K3。
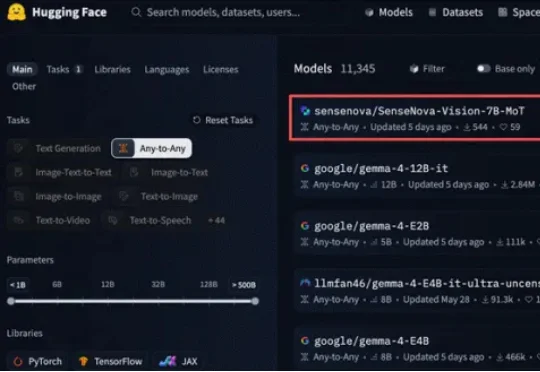
近日,商汤科技发布并全面开源日日新SenseNova-Vision理解生成统一视觉大模型,试图宣告视觉AI“缝合怪”时代的终结。截至当前,该模型综合得分登顶Hugging Face Any-to-Any Leaderboard,位列该全模态任意输入输出开源模型榜单全球第一。

时至今日,全球大模型格局已成定数,还有必要耗费巨资从零开始训练一个新模型吗?

很多人以为,把一个大模型放进手机或电脑,就像下载一个 App 一样简单。实际上,手机、电脑和智能硬件的芯片各不相同,同一个模型换一台设备,往往就要重新适配。Nexa AI 做的,就是解决这部分最麻烦也最容易被忽视的工作。

全双工语音对话是人类最自然的交流方式,是语音对话研究的梦想。相比文本输入,语音天然更接近人的交流方式,但现有语音对话常常停留在 “一问一答、听完再说” 的轮次式交互范式。

端侧AI持证上岗了。
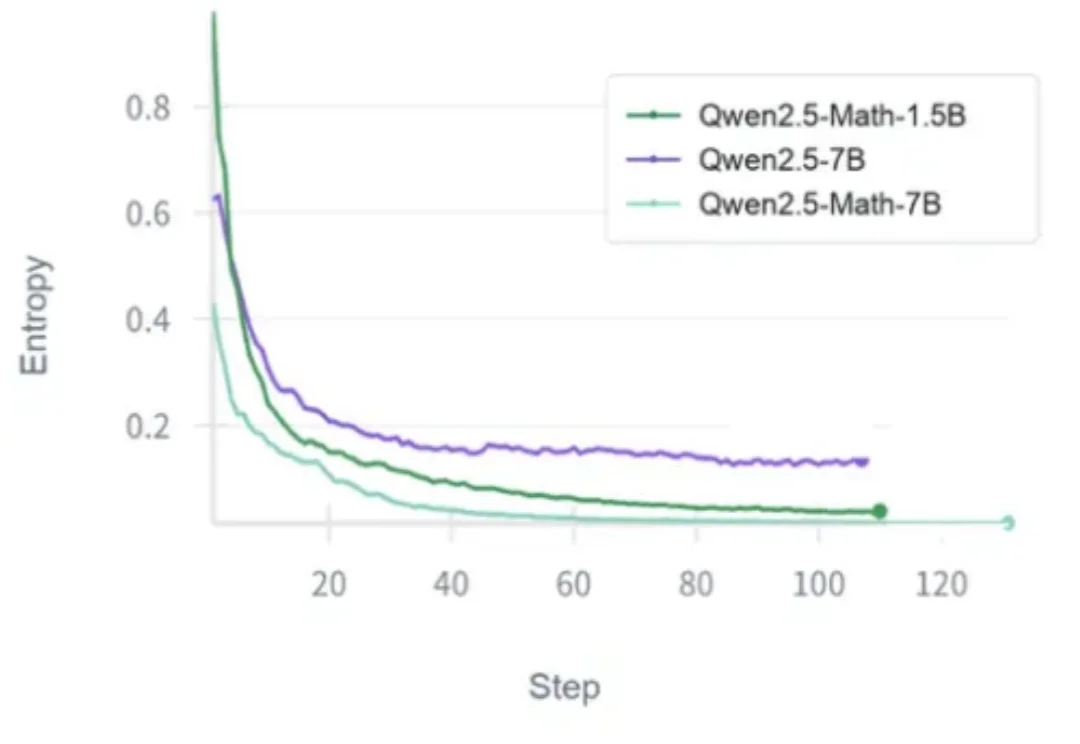
基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards,RLVR)正在成为大模型后训练的关键技术。数学题能判对错,代码能跑测试,可验证奖励让大模型可以通过强化学习持续提升推理能力。

推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
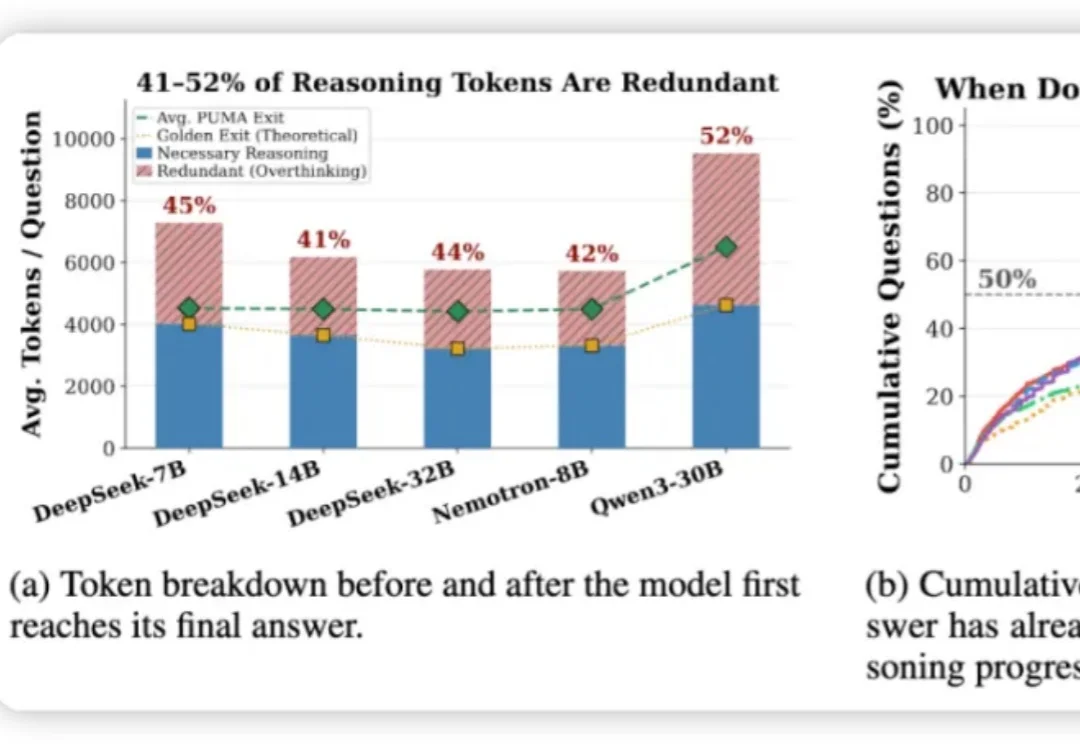
推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。

机器之心编辑部 由 OpenAI 前首席技术官 Mira Murati 创立的 AI 初创公司 Thinking Machines Lab,刚刚发布了自研 AI 模型 Inkling。与 OpenAI、Anthropic 或 Google 的旗舰模型不同,Inkling 是一款开放权重模型,外部开发者和企业可以直接下载,并根据自身需求进行修改。