# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
刚刚,「现代互联网架构之父」Jeff Dean的最新对谈流出。
这位AI领域的传奇,是Google Brain的奠基者,也是推动神经网络走向规模化的关键人物。
从让神经网络「看懂猫」的重大突破,到TensorFlow与TPU的诞生,他的故事几乎是一部AI发展史。
在最新一期「登月播客」(The Moonshot podcast)深度访谈中,Jeff Dean回顾了个人成长经历、Google Brain的早期故事,以及他对AI未来的思考。

节目中,他揭秘了他本人所知的一些细节和趣事:
· 小时候,Jeff Dean打印了400页源码自学。
· 90年代,他提出「数据并行/模型并行」概念时,还没这些术语。
· Google Brain的最初灵感,竟然是在谷歌的微型茶水间与吴恩达的一次闲聊中诞生。
· 「平均猫」图像的诞生,被Jeff比作「在大脑里找到了触发祖母记忆的神经元」。
· 他把AI模型比作「苏格拉底式伙伴」,能陪伴推理、辩论,而不是单向工具。
· 对未来的隐喻:「一亿老师,一个学生」,人类不断教AI模型,所有人都能受益。
Jeff是工程超级英雄口中的「工程超级英雄」,很少有人像Jeff Dean这样的单个工程师,赢得人们如此多的仰慕。

主持人的第一个问题是:Jeff Dean是如何成为工程师的?
Jeff Dean认为他有一个不同寻常的童年。因为经常搬家,在12年里他换了11所学校。
在很小的时候,他喜欢用乐高积木搭建东西,每次搬家总要带上他的乐高套装。
当九岁的时候,他住在夏威夷。
Jeff的父亲是一名医生,但他总是对计算机如何用于改善公共卫生感兴趣。当时如果想用计算机,他只能去健康部门地下室的机房,把需求交给所谓的「主机大神」,然后等他们帮你实现,速度非常慢。

在杂志上,Jeff的爸爸看到一则广告,买下了DIY计算机套件。那是一台Intel 8080的早期机型(大概比Apple II还要早一两年)。

最初,这台电脑就是一个闪烁灯和开关的盒子,后来他们给它加了键盘,可以一次输入多个比特。再后来,他们安装了一个BASIC解释器。Jeff Dean买了一本《101个BASIC语言小游戏》的书,可以把程序一行一行敲进去,然后玩,还能自己修改。
这就是他第一次接触编程。
后来,Jeff一家搬到明尼苏达州。全州的中学和高中都能接入同一个计算机系统,上面有聊天室,还有交互式冒险游戏。
这就像「互联网的前身」,比互联网普及早了15~20年。
当时,Jeff大概13、14岁,他在玩儿的一款多人在线的游戏源码开源了。
Jeff偷偷用了一台激光打印机,把400页源代码全都打印了出来,想把这款多人主机游戏移植到UCSD Pascal系统上。
这个过程让他学到了很多关于并发编程的知识。
这是Jeff Dean第一次编写出并不简单的软件。
大概是91年,人工智能第一次抓住了Jeff Dean想象力。
具体而言,是使用lisp代码进行遗传编程。
而在明尼苏达大学本科的最后一年,Jeff Dean第一次真正接触了人工智能。
当时,他上了一门并行与分布式编程课,其中讲到神经网络,因为它们本质上非常适合并行计算。
那是1990年,当时神经网络刚好有一波热潮。它们能解决一些传统方法搞不定的小问题。
当时「三层神经网络」就算是「深度」了,而现在有上百层。
他尝试用并行的方法来训练更大的神经网络,把32个处理器连在一起。但后来发现,需要的算力是100万倍,32个远远不够。

论文链接:https://drive.google.com/file/d/1I1fs4sczbCaACzA9XwxR3DiuXVtqmejL/view
虽然实验规模有限,但这就是他和神经网络的第一次深度接触,让他觉得这条路很对。
即便到了90年代末,神经网络在AI领域已经完全「过时」了。之后,很多人放弃了「神经网络」研究。
但Jeff Dean并没有完全放弃。当时整个AI领域都转移了关注点,他就去尝试别的事情了。
毕业后,他加入了Digital Equipment Corporation在Palo Alto的研究实验室。

数字设备公司Digital Equipment Corporation,简称DEC,商标迪吉多Digital,是成立于1957年的一家美国电脑公司,发明了PDP系列迷你计算机、Alpha微处理器,后于1998年被康柏电脑收购
后来,他加入谷歌,多次在不同领域「从头再来」:
搜索与信息检索系统、大规模存储系统(Bigtable、Spanner)、机器学习医疗应用,最后才进入Google Brain。
在职业生涯里,Jeff Dean最特别的一点是:一次又一次地「从零开始」。
这种做法激励了很多工程师,证明了「影响力」不等于「手下的人数」,而是推动事情发生的能力。
就像把雪球推到山坡上,让它滚得足够快、足够大,然后再去找下一个雪球。Jeff Dean喜欢这种方式。

然后在Spanner项目逐渐稳定后,他开始寻找下一个挑战,遇到了吴恩达。

在谷歌的茶水间偶然碰面,吴恩达告诉Jeff Dean:「在语音和视觉上,斯坦福的学生用神经网络得到了很有前景的结果。」
Jeff一听就来了兴趣,说:「我喜欢神经网络,我们来训练超大规模的吧。」
这就是Google Brain的开端,他们想看看是否能够真正扩大神经网络,因为使用GPU训练神经网络,已经取得良好的结果。
Jeff Dean决定建立分布式神经网络训练系统,从而训练非常大的网络。最后,谷歌使用了2000台计算机,16000个核心,然后说看看到底能训练什么。
渐渐地,越来越多的人开始参与这个项目。
谷歌在视觉任务训练了大型无监督模型,为语音训练了大量的监督模型,与搜索和广告等谷歌部门合作做了很多事情。

最终,有了数百个团队使用基于早期框架的神经网络。
纽约时报报道了这一成就,刊登了那只猫的照片,有点像谷歌大脑的「啊哈时刻」。

因为他们使用的是无监督算法。
他们把特定神经元真正兴奋的东西平均起来,创造最有吸引力的输入模式。这就是创造这只猫形象的经过,称之为「平均猫」。
在Imagenet数据集,谷歌微调了这个无监督模型,在Imagenet 20000个类别上获得了60%的相对错误率降低(relative error rate reduction)。
同时,他们使用监督训练模型,在800台机器上训练五天,基本上降低了语音系统30%的错误率。这一改进相当于过去20年的语音研究的全部进展。
因此,谷歌决定用神经网络进行早期声学建模。这也是谷歌定制机器学习硬件TPU的起源。
之后不久,谷歌大脑团队取得了更大的突破,就是注意力机制(attention)。
Jeff Dean认为有三个突破。
第一个是在理解语言方面,词或短语的分布式表示(distributed representation)。
这样不像用字符「New York City」来表示纽约市,取而代之的是高维空间中的向量。
纽约市倾向于出现的固有含义和上下文,所以可能会有一个一千维的向量来表示它,另一个一千维的向量来表示番茄(Tomato)。
而实现的算法非常简单,叫做word2vec(词向量),基本上可以基于试图预测附近的词是什么来训练这些向量。

论文链接:https://arxiv.org/abs/1301.3781
接下来,Oriol Vinyals, Ilya Sutskever和Quoc Le开发了一个叫做序列到序列(sequence to sequence)的模型,它使用LSTM(长短期记忆网络)。

论文链接:https://arxiv.org/abs/1409.3215
LSTM有点像是一个以向量作为状态的东西,然后它处理一堆词或标记(tokens),每次它稍微更新它的状态。所以它可以沿着一个序列扫描,并在一个基于向量的表示中记住它看到的所有东西。
它是系统运行基础上的短期记忆。
结果证明这是建模机器翻译的一个非常好的方法。
最后,才是注意力机制,由Noam Shazeer等八人在Transformer中提出的注意力机制。

这个机制的想法是,与其试图在每个单词处更新单个向量,不如记住所有的向量。
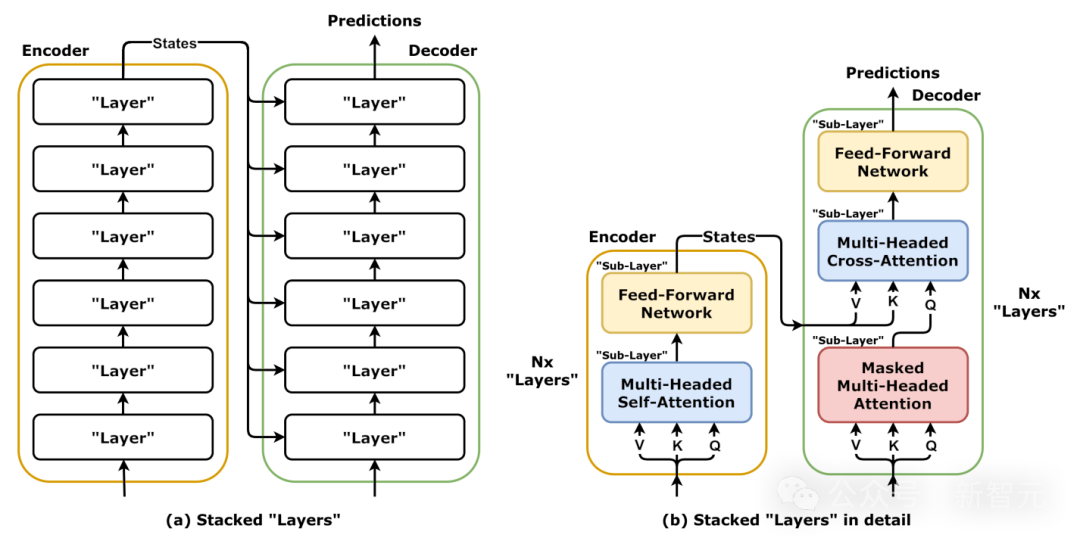
所以,注意力机制是这篇非常开创性的论文的名字,他们在其中开发了这种基于transformer的注意力机制,这个机制在序列长度上是n平方的,但产生了惊人的结果。
一直以来,LLM神经网络运作机制很难被人理解,成为一个无法破译的「黑箱」。
而如今,随着参数规模越来越庞大,人们无法像理解代码一样去理解LLM。
研究人员更像是在做「神经科学」研究:观察数字大脑的运作方式,然后试着推理背后的机制。
人类理解模型的想法,未来会怎么发展?
Jeff Dean对此表示,研究这一领域的人,把它称之为「可解释性」。所谓可解释性,就是能不能搞清楚LLM到底在做什么,以及它为什么会这么做?
这确实有点像「神经科学」,但相较于研究人类神经元,LLM毕竟是数字化产物,相对来说探测比较容易。
很多时候,人们会尝试做一些直观的可视化,比如展示一个70层模型里,第17层在某个输入下的情况。
这当然有用,但它还是一种比较静态的视角。
他认为,可解释性未来可能的发展一个方向——如果人类想知道LLM为何做了某种决定,直接问它,然后模型会给出回答。
主持人表示,自己也不喜欢AGI术语,若是不提及这一概念,在某个时候,计算机会比人类取得更快的突破。
未来,我们需要更多的技术突破,还是只需要几年的时间和几十倍的算力?
Jeff Dean表示,自己避开AGI不谈的原因,是因为许多人对它的定义完全不同,并且问题的难度相差数万亿倍。
就比如,LLM在大多数任务上,要比普通人的表现更强。
要知道,当前在非物理任务上,它们已经达到了这个水平,因为大多数人并不擅长,自己以前从未做过的随机任务。在某些任务中,LLM还未达到人类专家的水平。
不过,他坚定地表示,「在某些特定领域,LLM自我突破已经触及门槛」。
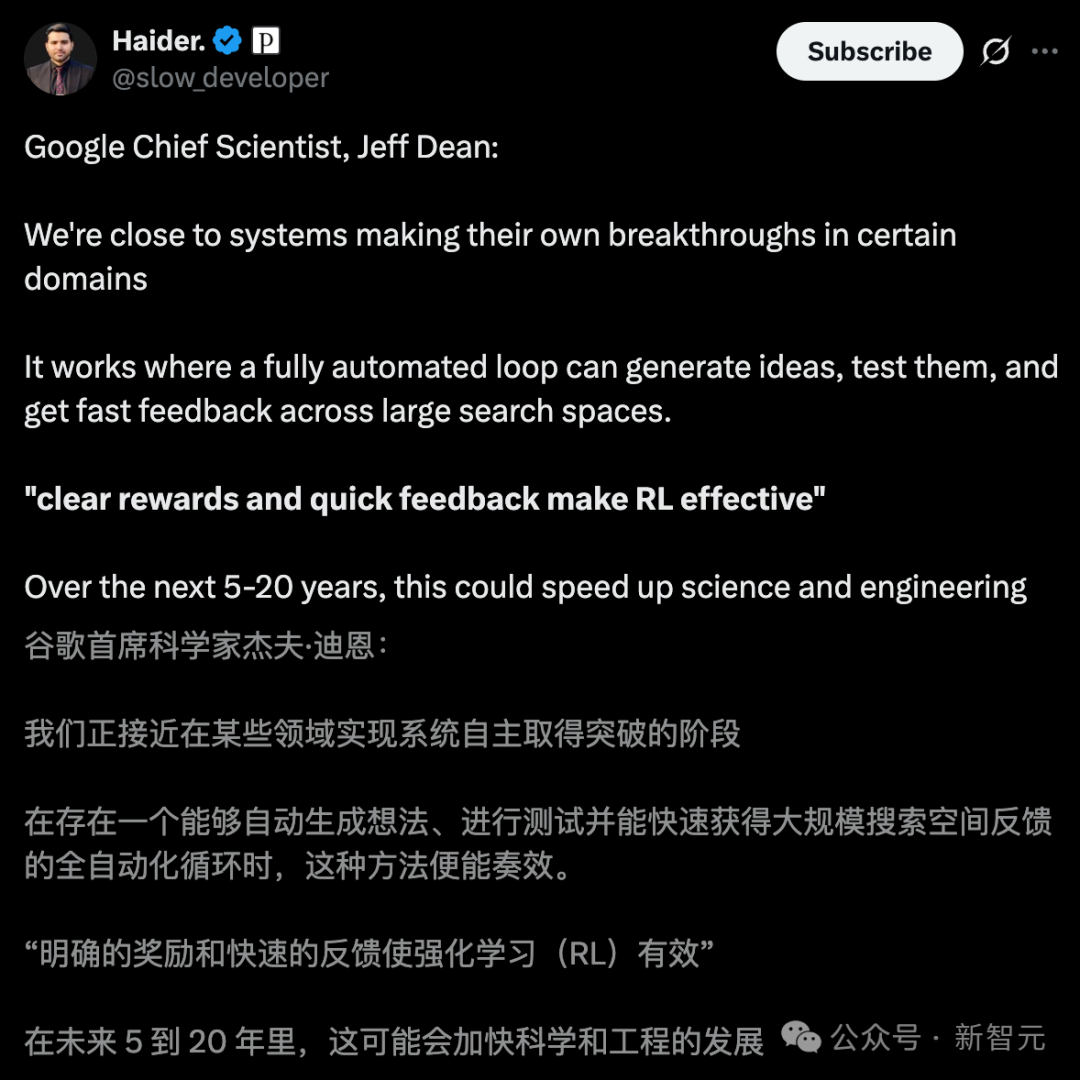
前提是,它能够形成一个完全自动化闭环——自动生成想法、进行测试、获取反馈以验证想法的有效性,并且能庞大的解决方案空间中进行探索。
Jeff Dean还特别提到,强化学习算法和大规模计算搜索,已证明在这种环境中极其有效。
在众多科学、工程等领域,自动化搜索与计算能力必将加速发展进程。
这对于未来5年、10年,甚至15-20年内,人类能力的提升至关重要。
当问及未来五年个人规划时,Jeff Dean称,自己会多花些时间去思考,打造出更加强大、更具成本效益的模型,最终部署后服务数十亿人。
众所周知,谷歌DeepMind目前最强大的模型——Gemini 2.5 Pro,在计算成本上非常高昂,他希望建造一个更优的系统。
Jeff Dean透露,自己正在酝酿一些新的想法,可能会成功,也可能不会成功,但朝着某个方向努力总会有奇妙之处。
参考资料:
https://www.youtube.com/watch?v=OEuh89BWRL4
文章来自于微信公众号“新智元”。



【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
