# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
跨学科突破:神经科学如何让 Agent 拥有「人类式」记忆?
你是否想过 Agent 能像人类一样积累经验、不断成长?如今,这一愿景正加速走向现实。但是,现有研究要么只聚焦 AI 技术本身,要么对人脑记忆机制的借鉴浮于表面,两个学科之间始终缺少真正的灵感碰撞。
哈工大、鹏城实验室、新加坡国立、复旦、北大联合发布了一篇重磅综述《AI Meets Brain: A Unified Survey on Memory System from Cognitive Neuroscience to Autonomous Agents》,首次打破认知神经科学与人工智能之间的学科壁垒,系统性地将人脑记忆机制与 Agents 记忆统一审视,为设计真正「类人」的 Agent 记忆系统奠定理论基石。
全文横跨认知神经科学与人工智能两大领域,涉猎相关文献共 400 篇。

什么是记忆?
综述重新定义了记忆。记忆不仅仅是数据的存储,它也是认知的纽带。综述从认知神经科学到 Agent 对记忆进行了剖析:
1.认知神经科学角度:连接过去与未来的桥梁
在人脑中,记忆不仅仅是回放信息,其本质是大脑存储和管理信息的过程。记忆是连接过去经验与未来决策的认知桥梁。它分为两个阶段:在第一阶段,当大脑获得新概念或遇到新事件时,它会快速形成特定的神经表征,同时整合和存储这些信息。在第二阶段,大脑对存储的表征进行操作,要么随着时间的推移巩固它们,要么根据类似的未来情况检索它们。
2.LLM 视角:三种形态的并存
对于大语言模型,记忆并非单一的存储结构,而是表现为三种形式:
3.Agent 视角:从存储到认知的跃迁
Agent 的记忆超越了 LLM 的简单存储,它是一个动态的认知架构,该综述选择沿着三个核心维度解构记忆:
Agent Memory vs RAG:传统的 RAG 侧重于将 LLM 连接到静态的知识库进行查询,而 Agent Memory 是嵌入在 Agent 与其环境之间的动态交互过程中,不断地将 Agent 操作和环境反馈生成的信息合并到记忆容器中。
记忆有何用?
在认知神经科学中,记忆构成了大脑编码、存储和检索信息的神经过程,使个体能够保留过去的经验并利用它们来指导正在进行的行为并为未来的决策提供信息。
在 LLM 驱动的 Agent 中,模型原生的无状态性与复杂、长期任务所需的连续性需求之间存在着天然的鸿沟。因此,记忆超越了其作为桥接历史交互的被动存储库的角色,而是充当 Agent 认知架构中的关键主动组件。因此,给 Agent 装上记忆系统,并非只是为了记住,而是为了实现三大核心作用:
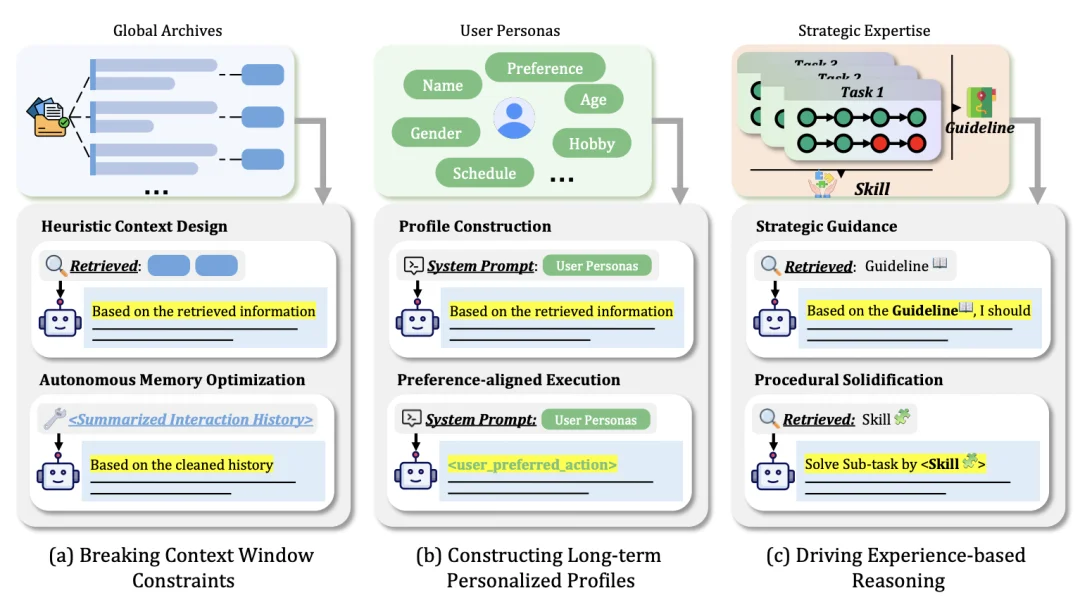
图 1. 记忆通过减轻上下文窗口限制、实现长期个性化以及驱动基于经验的推理来扩展 Agent 的能力。
1.突破上下文窗口的限制:
2.构建长期个性化画像:
3.驱动基于经验的推理:
记忆的分类学
在谈论 Agent 记忆的分类之前,综述首先梳理了认知神经科学对记忆的经典定义。人脑的记忆并不是一个单一的黑盒,而是一个分工明确的复杂系统。
1.基于认知神经科学的分类:
记忆的概念最初源于认知神经科学,它被广泛地定义为大脑存储和管理信息的认知过程,允许在原始刺激或事件不再存在后访问和使用这些信息,通常分为短期记忆和长期记忆。
2.Agent 的双维度记忆分类
综述中指出,连贯的记忆分类对于系统地理解和设计 Agent 系统中的记忆机制至关重要。为了适应复杂的自主任务,综述提出了一套双维度的分类法。
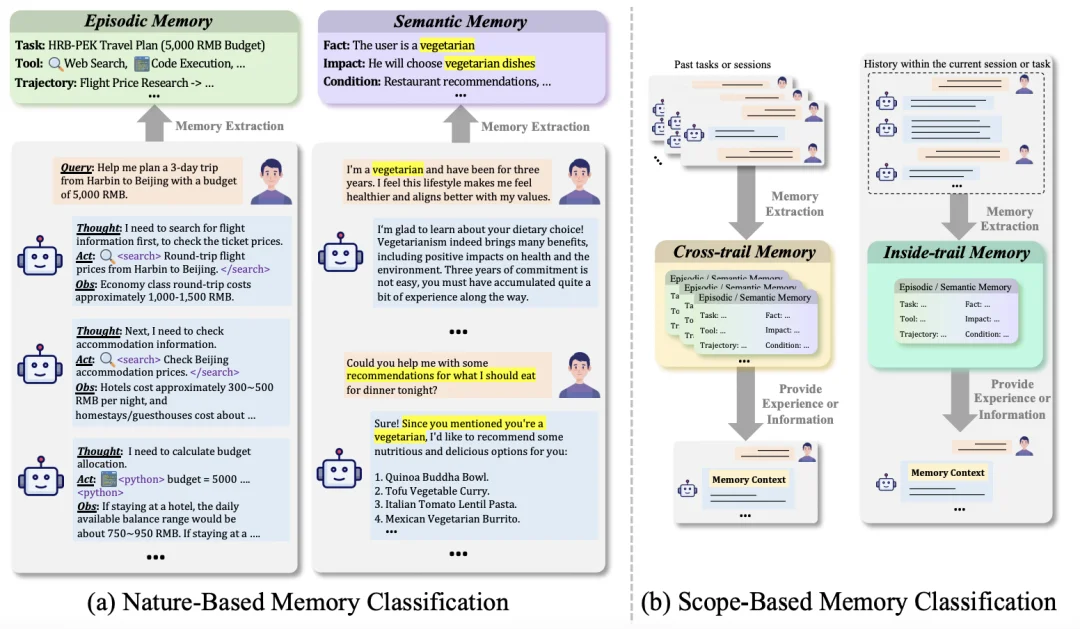
图 2. (a) 基于性质的分类法,根据编码的信息类型对记忆进行分类。 (b) 基于范围的分类,根据记忆的应用范围来区分。
(1).基于「性质」的分类(Nature-based)
这是直接对齐人脑「情景和语义」的分类方式,决定了 Agent 在推理时使用的是「经验」还是「知识」。
(2).基于「范围」的分类 (Scope-based)
这是基于记忆在任务流中的生命周期和适用范围进行的划分。
记忆的存储机制
记忆存储的关键在于记忆的存储位置和记忆的存储形式。
1.认知神经科学中的记忆存储
在人脑中,记忆存储是一个跨脑区的动态协作过程。
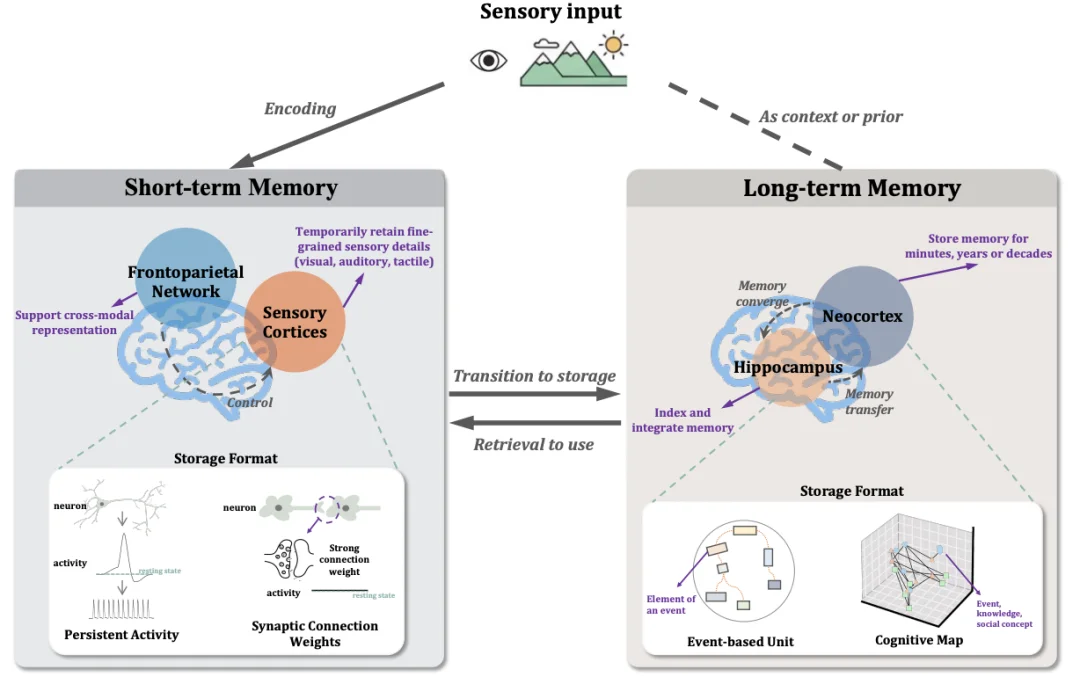
图 3. 认知神经科学中的记忆存储机制概述,包括短期和长期记忆的存储位置和存储格式。
2.Agent 中的记忆存储
不同于人脑浑然天成的神经网络,Agent 的记忆系统是显式的工程构建。不仅要解决存在哪的物理限制,还要在怎么存上进行复杂的数据结构选型,以在计算成本和推理能力之间寻找最优解。
记忆的管理系统
记忆不是一个静态的仓库,而是一条奔流不息的河流。在人类大脑中,记忆通过海马体的重播和新皮层的巩固,不断被重写和重构。而在 Agent 中,记忆管理则是提取(Extraction)、更新(Updating)、检索(Retrieval)、应用(Application)的精密闭环。
1.认知神经科学:大脑的动态循环
人脑的记忆管理不是简单的「写入」和「读取」,而是一个充满可塑性的动态过程。
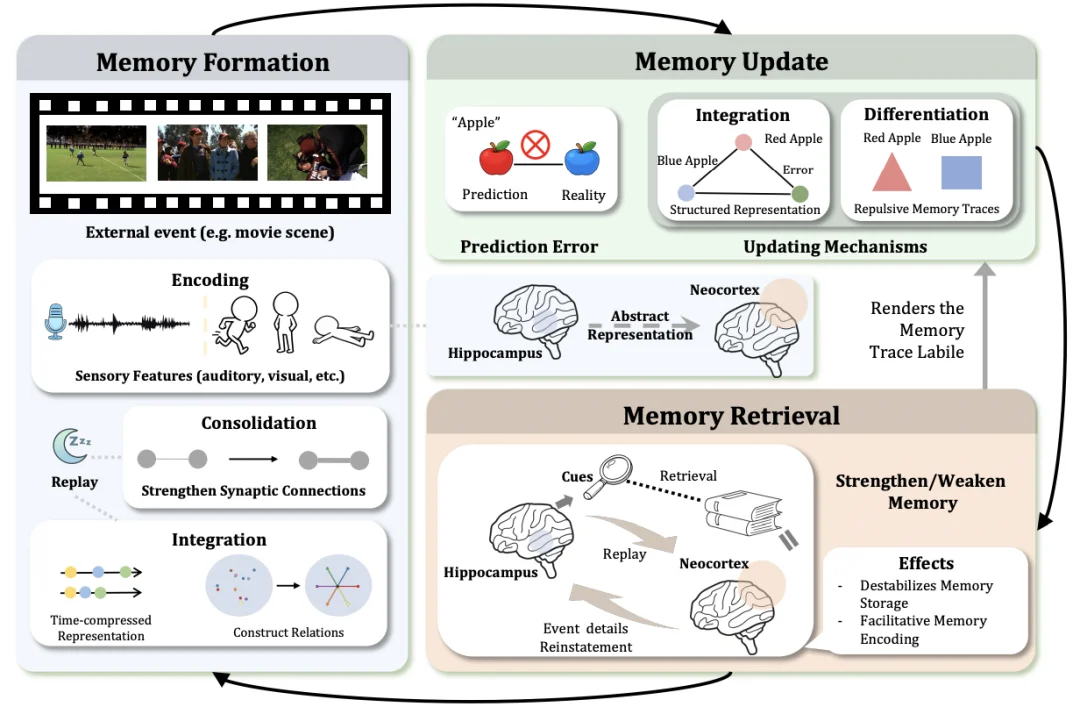
图 4. 认知神经科学中的记忆管理概述。该框架阐释了信息处理的动态循环,包括记忆形成、更新和检索,通过这个循环,长期记忆支持对外部环境的灵活适应。
记忆并非一蹴而就,它经历了三个阶段:
大脑如何修正错误的记忆?
检索即重构。
2.Agent 记忆管理:记忆管理的精密闭环
与在受限窗口内执行瞬态处理的标准大语言模型不同,Agent 通过显式管理机制实现体验的持久调节。
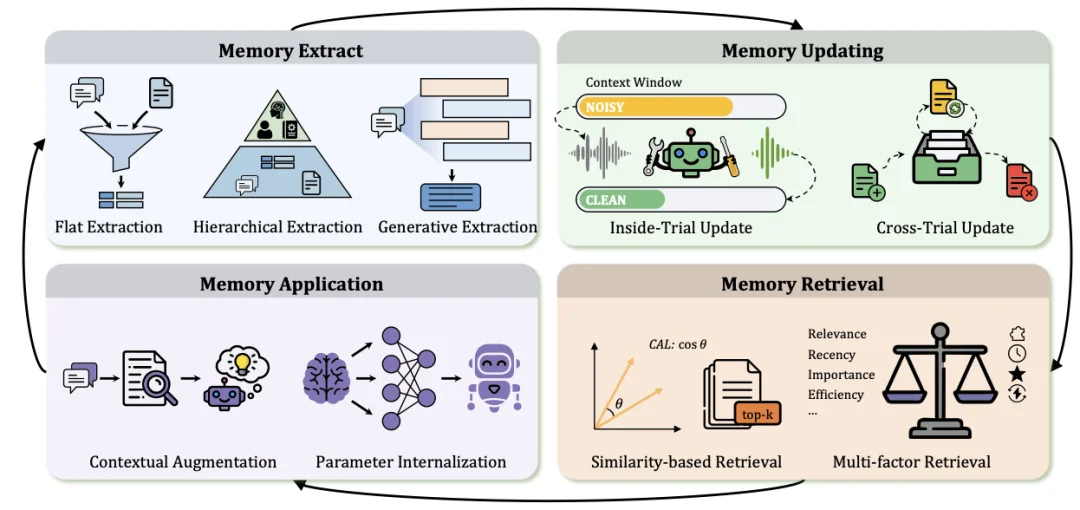
图 5. Agent 中记忆管理的概述。该框架形成了一个由记忆提取、更新、检索和利用组成的闭环管道,从而实现持久的经验调节和长期推理。
Agent 不能把所有 Log 都存下来,它需要提炼:
遗忘是为了更好地记住,更新机制分为两层:
不仅仅是 Embedding 的相似度,主要分为两种:
记忆怎么用,主要有两种作用:
Agent 记忆系统评测
综述将现有的 Benchmark 分为了两类:
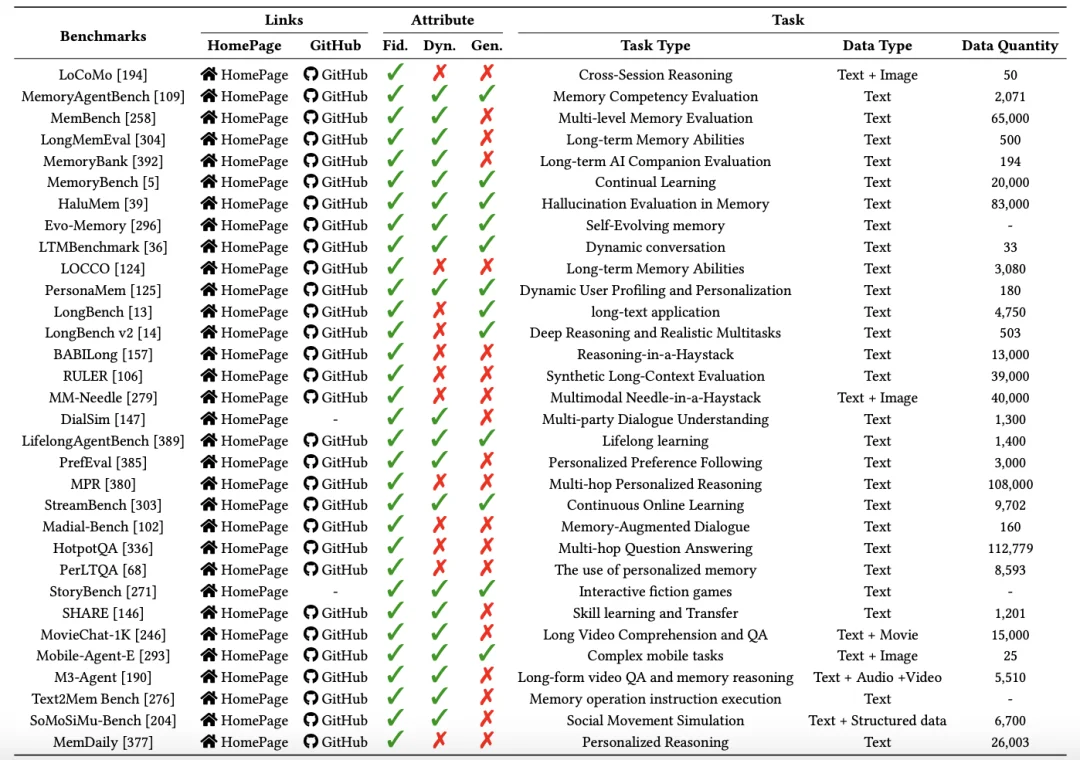
表 1. 面向语义的基准
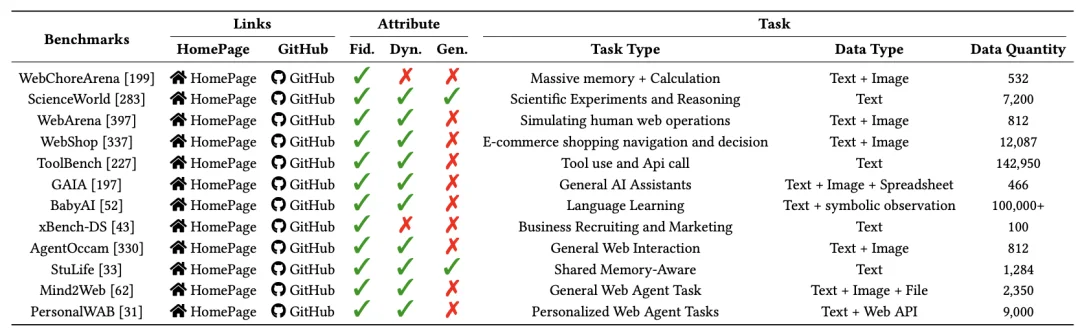
表 2. 面向情景的基准
Agent 记忆的安全
1. 攻击
随着 Agent 被部署在长期任务中,记忆成为了攻击。其主要的攻击方式分为两类:
2. 防御
面对这些威胁,综述提出了有三道防线,构筑起从源头到输出的闭环防御体系。
未来展望
1.多模态记忆
未来的 Agent Memory 需要打破模态的界限。目前的 Agent 在面对视频、音频等非结构化数据时,往往采用「暴力压缩」或「转写为文字」的方式,这会导致大量丰富的视觉细节(如微表情、光影变化)和听觉情感在转换中丢失。未来的记忆系统应该是全模态 (Omni-modal) 的,不仅存文本,还存储压缩后的视觉 / 听觉特征向量,其终极目标是使 Agent 不仅能「读」懂,还能「看」见,真正理解物理世界。
2.Agent Skills
现在的 Agent memory 往往是孤立。训练好一个专为写代码的 Agent,它的经验(记忆)很难直接传给另一个专为数学的 Agent,这导致了严重的重复造轮子。
这是因为不同的 Agent 之间的异构性,导致记忆接口的不一致,因此记忆很难直接移植重用。论文借用了 Anthropic 提出的「Agent Skills」概念,即 Agent 将指令集、可执行脚本和相关资源封装到结构化目录单元中。这就好比游戏里的「装备」或「技能书」可以在不同玩家间重复使用。
综述提出两个可能的未来研究方向:
文章来自于微信公众号 “机器之心”,作者 “机器之心”



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
