# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
立体匹配的前端已经进入视觉基座模型时代,后端却还停留在基于卷积的局部递归更新。LinStereo 关注的正是这个断层:当 Depth Anything V3 已经能提供全局语义和多尺度表征时,ConvGRU 式的局部传播反而成了遮挡、弱纹理和水下退化场景中的瓶颈。
悉尼大学澳大利亚机器人中心的 Yiran Wang、Oliver Turner 和 Viorela Ila 在 ECCV 2026 论文中提出用位置感知线性注意力模块替代卷积迭代,让每轮迭代都能聚合全图上下文,并辅以多尺度代价体积和单目深度初始化提升几何收敛。
更关键的是,LinStereo 在冻结视觉基座模型编码器,仅用 Scene Flow 合成数据训练下游 stereo 模块,其零样本泛化能力就将 Middlebury 遮挡区域把误差压低了 37%,在多项标准评估数据上以 ViT-B 的体量战胜了更大参数量的模型,甚至在在水下等跨域场景也展现了明显的优势。

现有迭代式匹配的瓶颈在哪
目前主流立体匹配的流程大同小异:预训练 backbone 出特征,建代价体积,ConvGRU 迭代回归视差。问题出在后半段。
backbone 输出了好几层不同分辨率的特征,但建代价体积的时候一般只用其中一层,多尺度信息被丢掉了不少。ConvGRU 每轮迭代感受野比较局限,碰到大面积弱纹理或者水下这种退化场景,有用的匹配信号得跑好几轮才传得到远处。再加上大多数方法都从零视差起步,头几轮迭代基本在摸场景大致轮廓,实际用来精细化的轮次并不多。
LinStereo 对应地做了三件事:PALA 换掉 ConvGRU 解决传播问题,HSCV 保留多尺度特征,DPI 用单目深度给一个靠谱的起点。
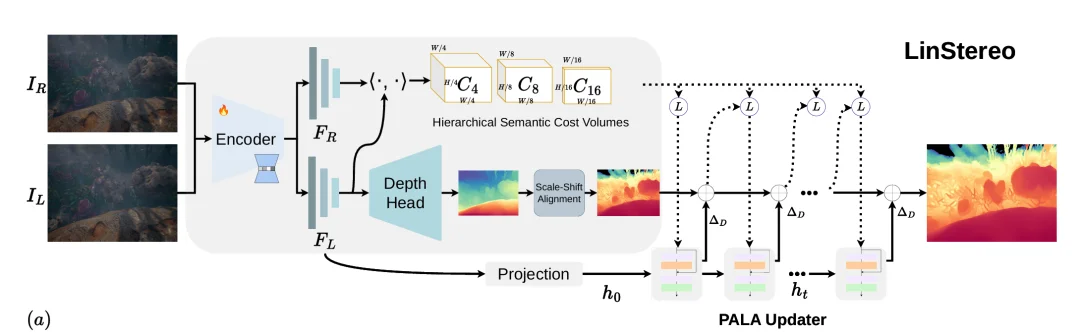
图 1:LinStereo 整体架构。(a)多尺度层次化语义 cost volume(HSCV);(b)coarse-to-fine 迭代更新;(c)位置感知线性注意力更新模块(PALA)。
PALA:全局注意力,但只要线性复杂度
PALA 做的事情说起来很直观,就是把 ConvGRU 的局部更新换成全局注意力,让每个像素每次迭代都能看到整张图。难点在于 softmax attention 是 O (N²) 的,直接用在高分辨率视差图上跑不动。
PALA 的做法是对 query 和 key 做 kernel 激活(ELU+1),利用矩阵乘法结合律把复杂度降到 O (N・C_h²)。实测 3.50 ms 一次迭代,ConvGRU 是 3.63 ms,基本没差别。
但线性注意力有个已知的毛病:kernel 化之后位置信息会丢失。PALA 用 2D RoPE 来补,这里有个比较巧妙的处理 ——RoPE 只加在注意力公式的分子上,分母不加。作者把这个叫 "非对称 RoPE"。为什么不两边都加?因为分母端加了 RoPE 之后归一化会引入位置偏移,注意力分布反而不稳定。消融也验证了这一点:KITTI 上差别不算大(EPE 1.05 vs 1.01),但换到水下 TartanAir-UW,RMSE 从 2.18 掉到 2.08,差了将近 5%。
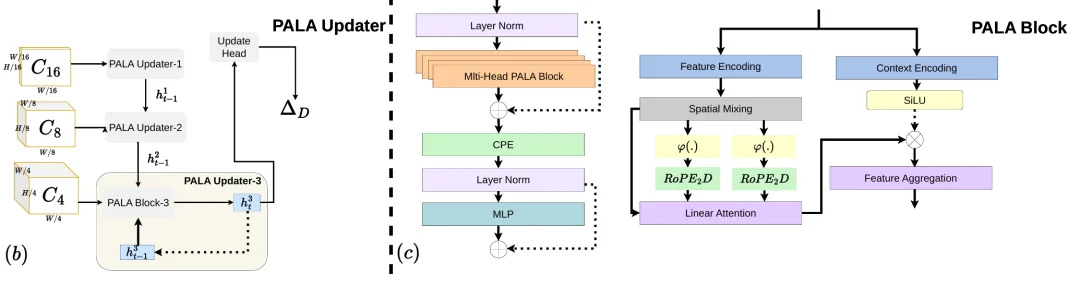
图 2:PALA 模块架构,展示 kernel-activated attention、非对称 2D RoPE 和门控更新机制。
HSCV 和 DPI
HSCV 比较好理解:在 1/4、1/8、1/16 三个尺度上分别建代价体积,每个尺度内部再做 4 层视差金字塔。这样 PALA 每轮迭代能查到不同粒度的匹配信息 —— 浅层管纹理,深层管语义。去掉多尺度之后 KITTI EPE 涨了 0.06,水下 AbsRel 涨了 0.003,看着不大,但跟 PALA 配合起来效果会放大。
DPI 更直接。Depth Anything V3 的 backbone 本身能出一张单目深度图,虽然是 affine-invariant 的(只有相对远近,没有绝对尺度),但拿 SIFT 在左右图上匹配几个点就能把 scale 和 shift 算出来,转成度量视差当初始值。为什么不用 SuperPoint 或 LightGlue?因为这些学习型匹配器在水下之类的跨域场景可能失灵,SIFT 纯靠几何约束反而稳。SQUID 上 SIFT 的失败率只有 3.7%,失败了就退回零初始化,EPE 性能略降 0.08 个像素。
实验:标准 benchmark 和跨域泛化
标准 benchmark
LinStereo 的 backbone 是 ViT-B,参数量和数据量都比用 ViT-L 的 FoundationStereo、MonSter 小一截。从下表来看,常规场景上基本打平,遮挡场景上优势明显。
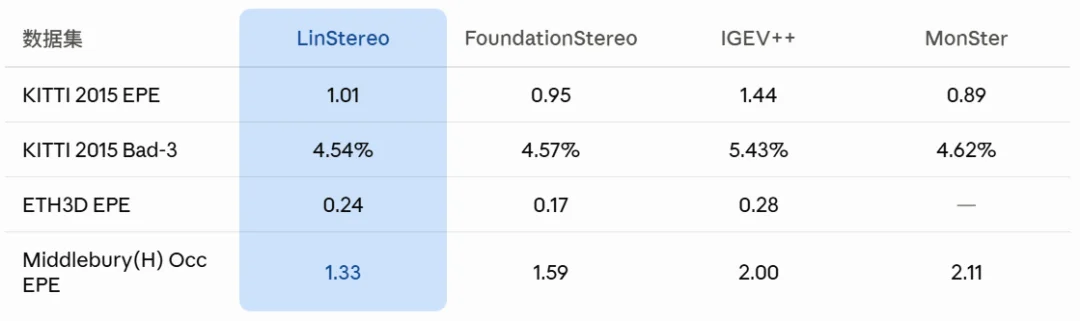
Middlebury 遮挡区域是最能体现全局注意力价值的指标。EPE 1.33,比排第二的 FoundationStereo 低了 16%,比之前的 DEFOM-Stereo(2.11)低了 37%。道理也好理解:被遮挡的像素附近没有可靠的匹配线索,ConvGRU 的局部窗口传不过来,PALA 可以直接从远处拿信息。

图 3:标准 benchmark 定性对比,LinStereo 在物体边缘和遮挡区域的深度图更干净。
跨域泛化:水下 zero-shot
全局传播的另一个受益场景是水下。光在水里按波长衰减,红色最先消失,再加上悬浮颗粒的散射,远处的纹理基本不可用。ConvGRU 在这种大面积退化的场景里传播太慢,PALA 就不存在这个问题。
LinStereo 没用过任何水下数据训练,但在水下 benchmark 上全面领先。
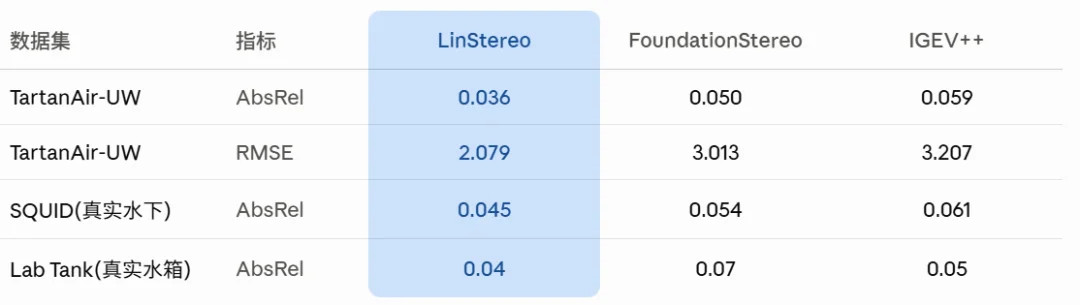

图 4:水下场景定性对比。退化严重的区域里,LinStereo 的深度图仍然连贯。
精准度和推理速度两手抓
T=2 迭代就能跑到 12.5 FPS(480×640),这个配置下 SQUID AbsRel 0.05 -> 在有计算性能受限的情况下, Linstereo 只需两次迭代优化(等效推理速度12.5FPS)仍可以保持SQUID AbsRel 0.05
三个模块,协同才是关键
三个模块单独加都有提升,但组合在一起效果远超单独叠加:
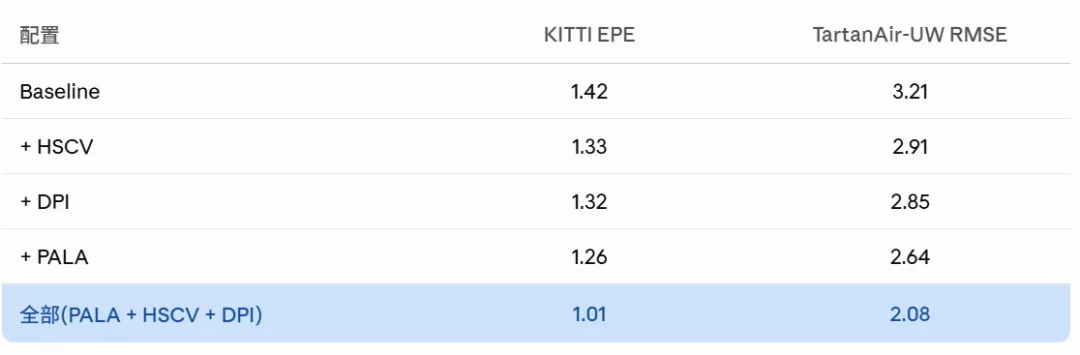
还有一个有意思的现象:PALA block 堆到 3 个(参数从 127M 涨到 147M),KITTI EPE 反而从 1.01 涨到 1.05。迭代本身已经在做隐式的深度堆叠,再显式加层数可能过拟合了。
SeaStereo 数据集
论文还发布了 SeaStereo-Dataset——40,320 对水下立体图像,带稠密视差标注,7 种 Jerlov 水体类型,用 Blender 做物理级水下光学渲染,前景是 ShapeNetCore 物体,背景是真实海洋照片。水下立体匹配一直缺公开数据,这个数据集对后续研究会比较有用。
参数高效:以小博大
得益于我们的参数高效设计,127M 参数中超过 100M 来自冻结的 Depth Anything V3 backbone,真正需要训练的仅约 10M。这充分验证了我们轻量 decoder 的有效性:小参数量同样能撬动大规模预训练的强大先验,在小样本水下场景下达到当前性能。面向水下机器人等边缘算力平台,我们正进一步通过知识蒸馏压缩编码器,把推理延迟推向更极致的水平。
作者简介
Yiran Wang,悉尼大学澳大利亚机器人中心(Australian Centre for Robotics)博士生,导师为 Viorela Ila 博士。本科毕业于澳大利亚国立大学(ANU)高级计算专业(荣誉学位)。研究方向涵盖计算机视觉、立体深度估计、运动生成与三维视觉,近期聚焦于利用 Vision Foundation Model 提升立体匹配在退化视觉条件下的鲁棒性。相关工作发表于 ECCV、NeurIPS、ICRA 等国际会议。
Viorela Ila,悉尼大学航空航天与机电工程学院高级讲师(Senior Lecturer),澳大利亚机器人中心核心研究员。2005 年获西班牙赫罗纳大学博士学位,后赴佐治亚理工学院从事博士后研究。研究方向涵盖视觉 SLAM、三维重建、图模型优化与水下机器人感知,近期代表工作包括动态 SLAM 框架 DynoSAM 等。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


