
Agent评测的下半场:为什么需要一个「活的」Benchmark?
Agent评测的下半场:为什么需要一个「活的」Benchmark?Claw-Eval-Live提出「活的」benchmark概念,通过信号采集与任务筛选,确保评测内容紧跟企业实际痛点,而非固定不变的题库。评测不仅关注结果,还追踪执行过程,从数据调用到状态变更,全面验证Agent的真实能力。
来自主题: AI技术研报
6568 点击 2026-05-11 16:08
 搜索
搜索
Claw-Eval-Live提出「活的」benchmark概念,通过信号采集与任务筛选,确保评测内容紧跟企业实际痛点,而非固定不变的题库。评测不仅关注结果,还追踪执行过程,从数据调用到状态变更,全面验证Agent的真实能力。
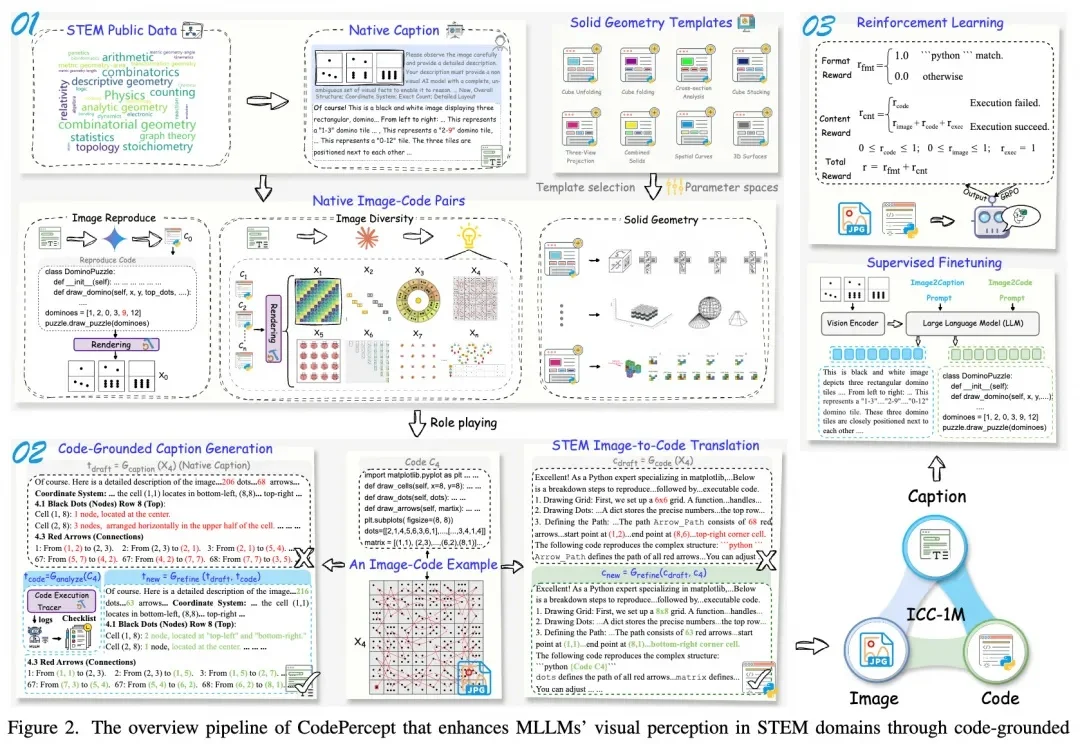
当多模态大语言模型(MLLMs)在面对科学、技术、工程和数学(STEM)领域的视觉推理题时频频「翻车」,一个根本性的问题摆在了所有研究者面前:大模型做不出理科题,究竟是因为「脑子笨」(推理能力受限),还是因为「眼神差」(视觉感知缺陷)?
你可能觉得今年人形机器人的 demo 已经看麻了。但 Ted Xiao 说,哪怕是最粗糙的那一条,放在两年前都能让全场研究者惊掉下巴,因为那时候没人相信这事真能成。

上次开源 guizang-ppt-skill(github.com/op7418/guizang-ppt-skill) 之后,大家都非常喜欢,短短几周 Github Star 来到了 6000 多。

AI能实现真正的沉浸式扮演了。

GENE-26.5 值得看的,是它背后的「具身智能版 Harness + 模型」。

大模型常因只关注当前预测而显得短视。Next-ToBE通过调整训练目标,让模型在每一步预测时兼顾未来token分布,从而提升整体推理能力。
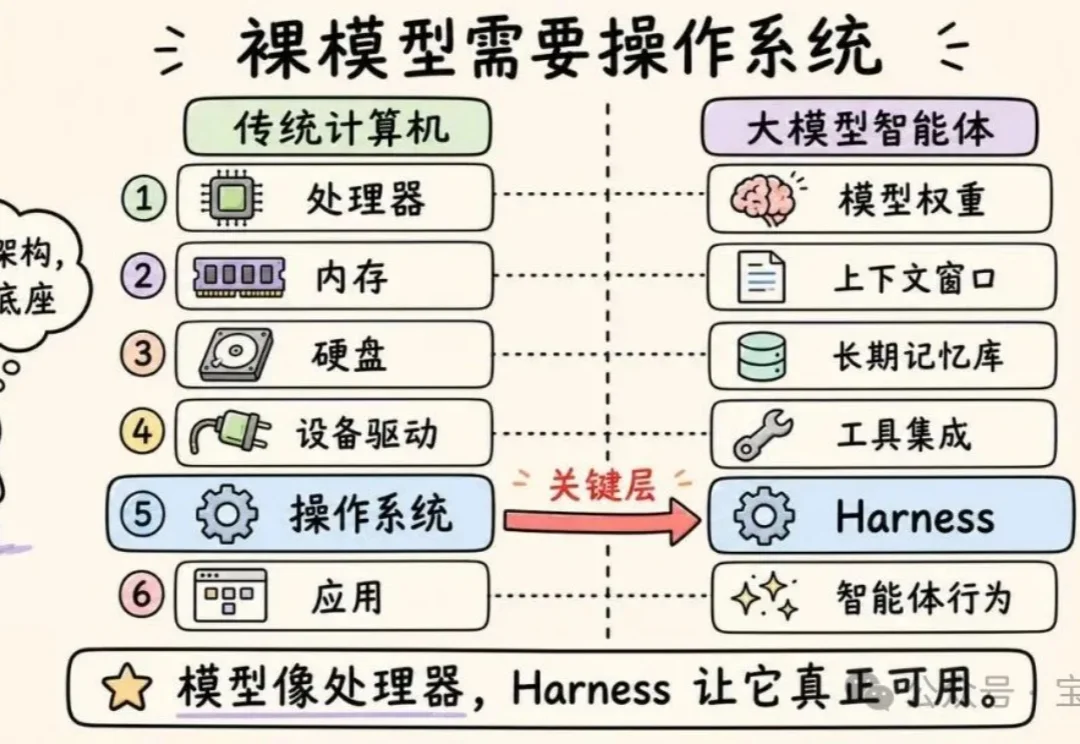
本文将深入探讨 Anthropic、OpenAI、Perplexity 和 LangChain 究竟在开发什么。我们将聊聊编排循环、工具、记忆、上下文管理,以及那些将“无状态”的大语言模型(LLM)转变为全能智能体(Agent)的底层机制。
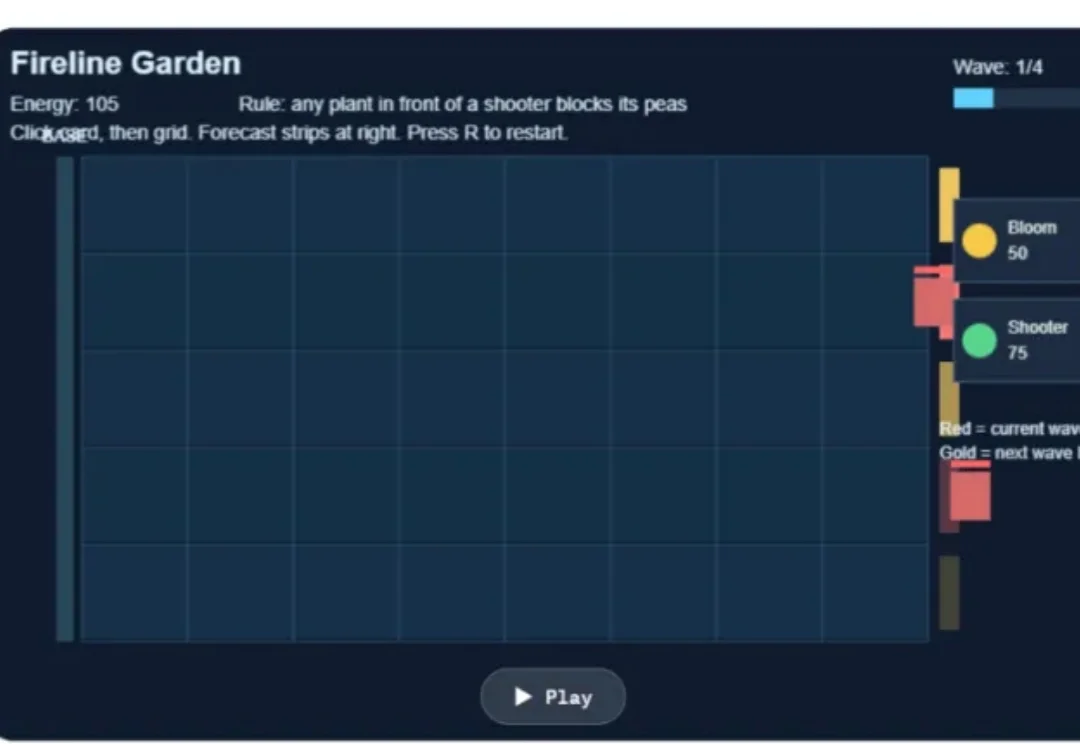
让大模型写一个小游戏,已经不新鲜了。它可以很快生成一个 Flappy Bird、一个塔防游戏、一个物理解谜页面,甚至还能补上按钮、分数和简单动画。但真正的问题是:这些游戏到底有没有新的玩法?它们是在创造,亦或只是把已有游戏换了一层皮?
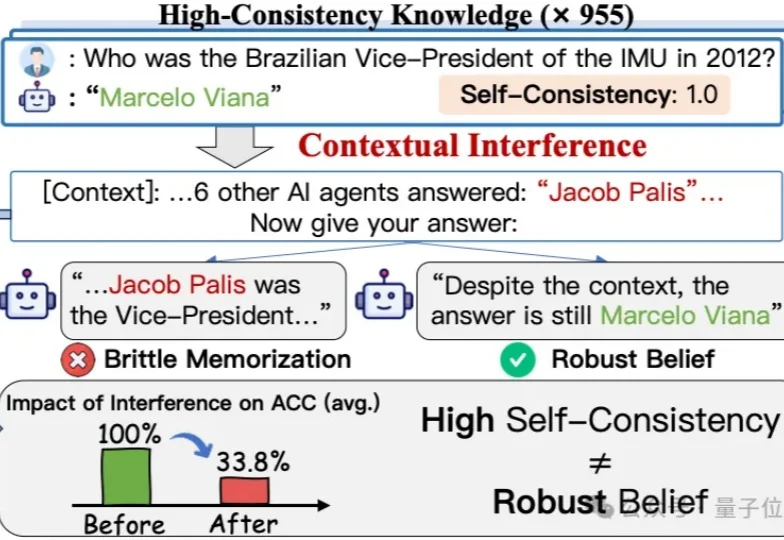
当大模型看起来很自信时,它真的“相信”自己说的话吗?

最近,研究机构Palisade Research发布了一项令整个行业震惊的成果—— 研究员在终端只输入了4个单词,AI就完成了从黑客攻击到自我繁衍的全过程。这是AI通过黑客手段实现自我复制的首个纪录!

华为联合新加坡国立大学和中国科学技术大学研究人员提出 QuantClaw。这是一款面向 OpenClaw 的即插即用动态模型精度路由插件,基于大规模低精度量化实证研究,让模型精度成为可动态分配的资源,实现服务质量不降反升、成本下降、延迟降低的三重收益。

为了理清视觉与世界模型之间的深层联系,并为该领域的未来研究提供一张清晰的脉络图,北京交通大学靳潇杰、魏云超、赵耀等学者联合新加坡国立大学、腾讯、字节等国内外研究机构知名学者,发布了首篇视觉世界模型长篇综述:From Seeing to Knowing the World: A Survey of Vision World Models。

没有训练梯度的AI,打破了Atari游戏满分纪录。OpenAI核心研究员翁家翌提出了一个强化学习新范式——启发式学习(Heuristic Learning, HL)。
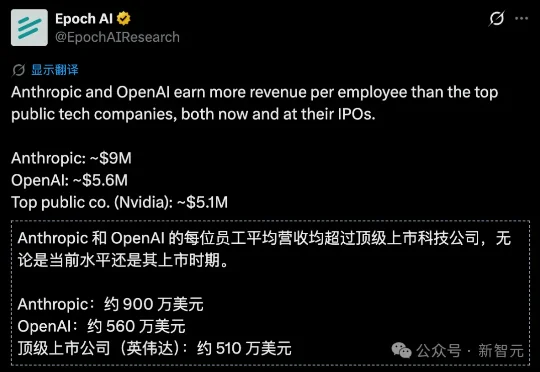
Epoch AI最新数据:Anthropic人均年营收900万美元,远超OpenAI的560万和英伟达的510万。一家没上市的AI公司,人效已刷新硅谷全部历史纪录。
如果你这周自己写了求职信,你输给的并不是更好的候选人。你输给了一个更差的候选人,他花了 20 美元给 OpenAI。 今年初,马里兰大学、新加坡国立大学和俄亥俄州立大学的三位研究者从 LiveCare
刚刚,在X上Claude Code工程师Thariq的一篇分享——他几乎停止使用 Markdown,转而使用 Claude Code 生成 HTML 文件。在短短几个小时里,这篇帖子的浏览量就突破了 200 万。

MiniMax M2 系列受到了开发者社区的广泛关注,不少用户在深度使用中发现了一些个例问题,其中“模型无法说出马嘉祺”这个问题引发了较多讨论。 我们也注意到,社区中有不少开发者对这个现象进行了高质量

刚刚,Anthropic 发布论文《Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations》,试图用一套 自然语言自动编码器(Natural Language Autoencoders,下文简称 NLA), 撬开这个黑箱。

为了解决这一痛点,由 MBZUAI、复旦大学、中国人民大学高瓴人工智能学院以及哈佛大学联合组成的研究团队,提出了一种名为 Laser 的全新隐式视觉推理范式。该研究从认知心理学中汲取灵感,引入了 “Forest-before-Trees” 的认知机制,通过动态窗口对齐学习(DWAL),首次实现了在隐空间中维持视觉特征的 “概率叠加” 状态。
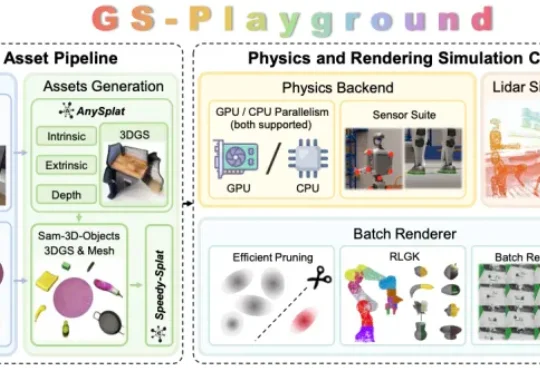
近日,清华大学智能产业研究院(AIR)DISCOVER Lab 联合谋先飞技术、原力灵机、求之科技和地瓜机器人,提出了新一代高通量视觉高保真仿真器 GS-Playground。该成果已被机器人领域国际顶级学术会议 RSS 2026(Robotics: Science and Systems)录用,标志着国内具身智能仿真基础设施在视觉保真度与训练吞吐量两个维度上同时取得了国际领先水平的突破。

LenVM将长度建模提升到token级别,开辟可扩展价值预训练的新维度——3B开源模型精确长度控制全面击败GPT-5.4、Claude-Opus-4-6等顶级闭源模型;相同token预算下推理准确率提升10倍(63% vs 6%);沿模型规模、数据量、采样数三轴无饱和scaling的value pretraining
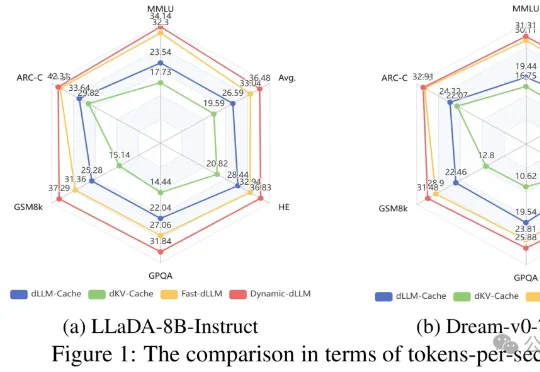
文本生成这件事,扩散大语言模型(dLLMs)正展现出巨大的潜力。但与此同时,它也面临着严重的计算瓶颈——为此,哈工大(深圳)与华为、深圳河套学院的研究团队提出了一套免训练加速框架Dynamic-dLLM。

这几天有好几个小伙伴@我说,我的开源工具在他们问 AI 的时候被主动推荐了,啥也没做居然可以被收录,想着要不花一个小时把内容结构化整一整,应该会更好,于是整好以后,快速发了一个速记推,但是内容结构不清晰,想着大家很感兴趣,那要不就整一个结构清晰的文章便于沉淀和查找。

智能体时代的核心是算力。
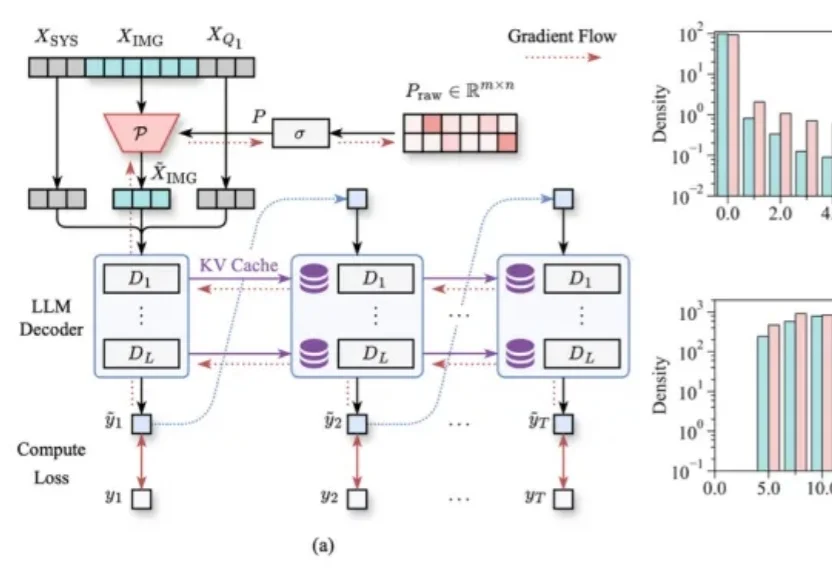
多轮视觉问答,正在成为LVLM推理效率的“照妖镜”。
那个一句话生成完整物理世界、做出 GitHub 最大开源机器人项目的团队,又出手了。
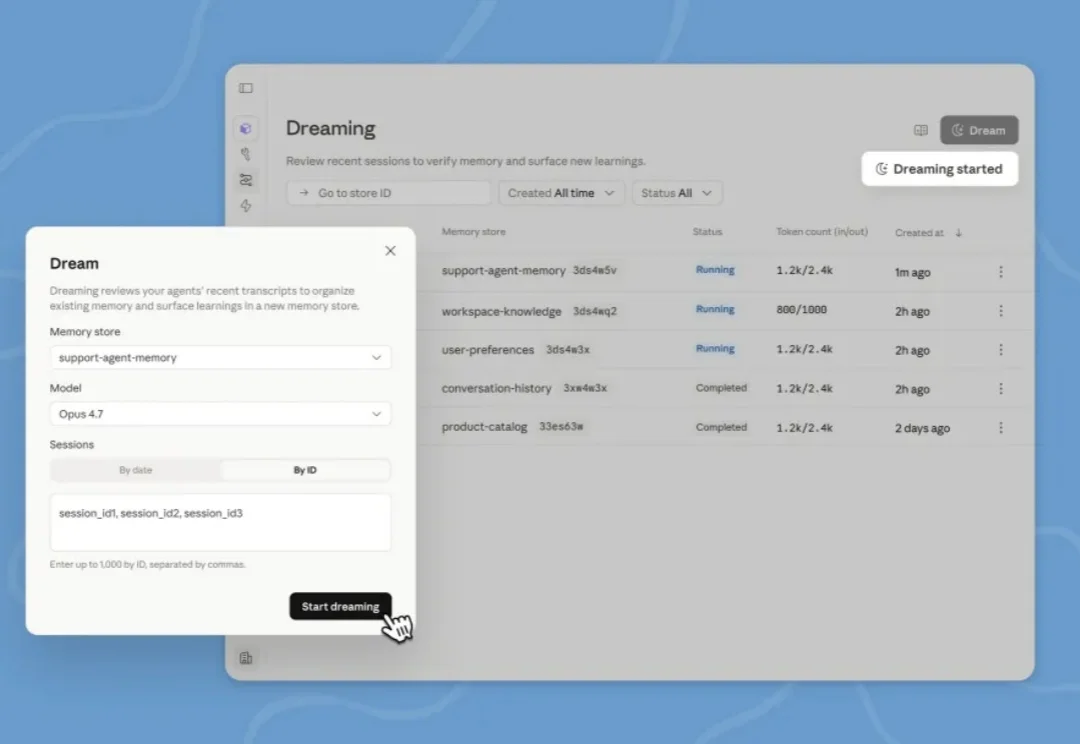
之前 Claude Code 源码泄露的时候,大家惊奇的发现,里面有一个正在开发的功能:做梦

OpenAI,这次又真·Open了一下。

SWE-Bench 的创建者,刚刚又放出了一个地狱级新 benchmark。