
10万token自然语言推理,让30B-A3B模型站上奥赛金牌线
10万token自然语言推理,让30B-A3B模型站上奥赛金牌线奥赛级科学推理,一定要从更大的通用模型开始吗?
来自主题: AI技术研报
8237 点击 2026-05-20 10:11
 搜索
搜索
奥赛级科学推理,一定要从更大的通用模型开始吗?

LenVM将长度建模提升到token级别,开辟可扩展价值预训练的新维度——3B开源模型精确长度控制全面击败GPT-5.4、Claude-Opus-4-6等顶级闭源模型;相同token预算下推理准确率提升10倍(63% vs 6%);沿模型规模、数据量、采样数三轴无饱和scaling的value pretraining

浙江大学联合美团龙猫团队、清华大学推出全新研究成果——SKILL0,并提出技能内化(Skill Internalization)——小模型真正需要的,或许不是推理时的“外挂技能”,而是将技能内化为本能。
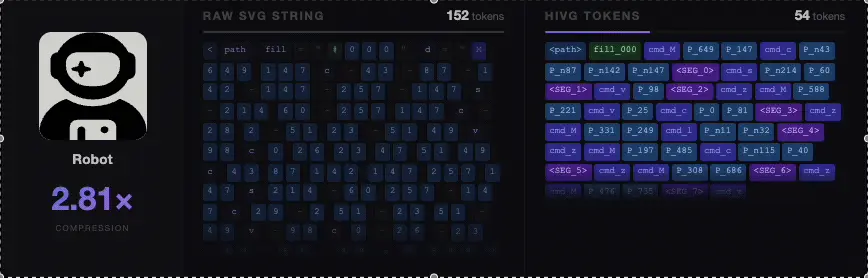
HiVG是一个面向SVG生成的层次化分词框架,在减少63.8% token数量的同时,以仅3B参数在多项指标上超越所有开源SVG模型和GPT-5.2等闭源模型。仅3B参数的HiVG,在SVG生成任务中多项指标超越了GPT-5.2、Claude-4.5-Sonnet等闭源模型。

蚂蚁通用人工智能中心自然语言组联合香港大学自然语言组(后简称“团队”)推出PromptCoT 2.0,要在大模型下半场押注任务合成。实验表明,通过“强起点、强反馈”的自博弈式训练,PromptCoT 2.0可以让30B-A3B模型在一系列数学代码推理任务上实现新的SOTA结果,达到和DeepSeek-R1-0528, OpenAI o3, Gemini 2.5 Pro等相当的表现。
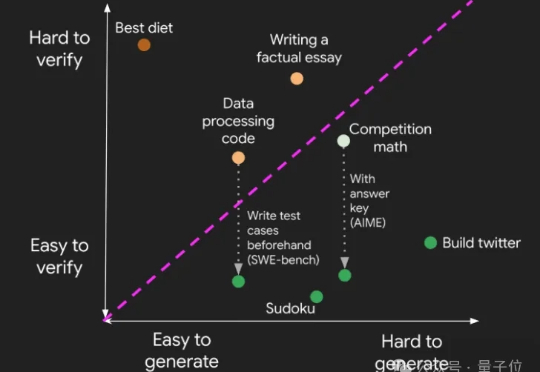
当大模型把人类曾经的终极考题变成日常练习,AI的奔跑却悄悄瘸了腿—— 训练能力突飞猛进,验证答案的本事却成了拖后腿的短板。 为此,上海AI Lab和澳门大学联合发布通用答案验证模型CompassVerifier与评测集VerifierBench。填补了Verifier领域没有建立验证->提升->验证的循环迭代体系的空白。
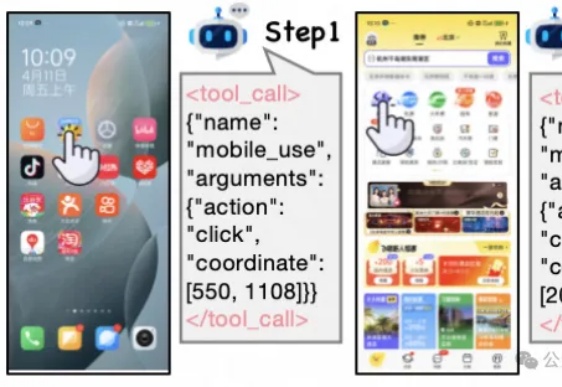
现有Mobile/APP Agent的工作可以适应实时环境,并执行动作,但由于它们大部分都仅依赖于动作级奖励(SFT或RL)。
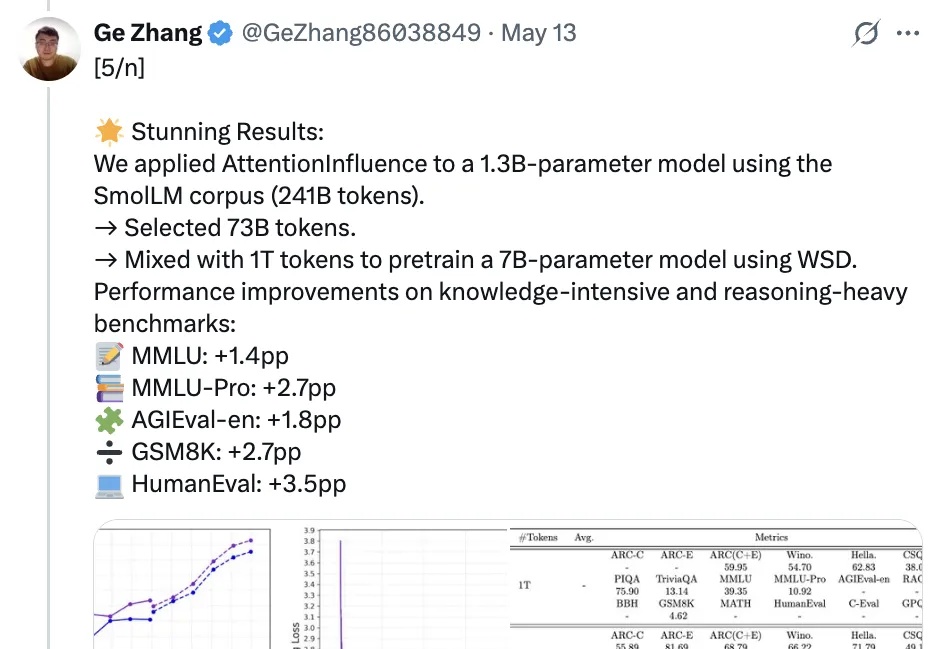
和人工标记数据说拜拜,利用预训练语言模型中的注意力机制就能选择可激发推理能力的训练数据!
AI视频的DeepSeek时刻什么时候来?没想到吧,这就来了。
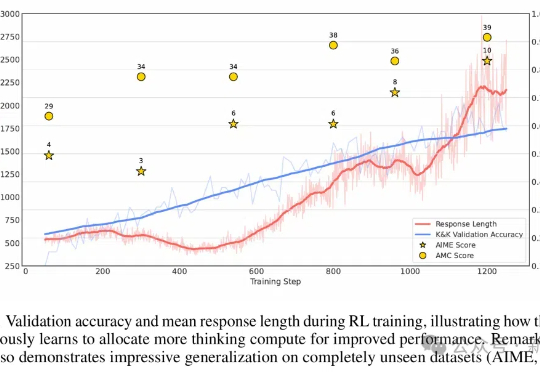
不到10美元,3B模型就能复刻DeepSeek的顿悟时刻了?来自荷兰的开发者采用轻量级的RL算法Reinforce-Lite,把复刻成本降到了史上最低!同时,微软亚研院的一项工作,也受DeepSeek-R1启发,让7B模型涌现出了高级推理技能。