

「熟悉的陌生人」才是「好老师」?复旦提出简单指标,找出推理蒸馏中真正有教学价值的数据
「熟悉的陌生人」才是「好老师」?复旦提出简单指标,找出推理蒸馏中真正有教学价值的数据什么样的思维链,能「教会」学生更好地推理?
来自主题: AI技术研报
9613 点击 2026-01-28 10:15
什么样的思维链,能「教会」学生更好地推理?

过去几年,机制可解释性(Mechanistic Interpretability)让研究者得以在 Transformer 这一 “黑盒” 里追踪信息如何流动、表征如何形成:从单个神经元到注意力头,再到跨层电路。但在很多场景里,研究者真正关心的不只是 “模型为什么这么答”,还包括 “能不能更稳、更准、更省,更安全”。

随着大语言模型(LLM)的商业价值快速提升,其昂贵的训练成本使得模型版权保护(IP Protection)成为业界关注的焦点。然而,现有模型版权验证手段(如模型指纹)往往忽略一个关键威胁:攻击者一旦直接窃取模型权重,即拥有对模型的完全控制权,能够逆向指纹 / 水印,或通过修改输出内容绕过指纹验证。

在大模型研究领域,做混合专家模型(MoE)的团队很多,但专注机制可解释性(Mechanistic Interpretability)的却寥寥无几 —— 而将二者深度结合,从底层机制理解复杂推理过程的工作,更是凤毛麟角。
AI语音成大厂必争之地 打开字节、阿里们的多模态能力地图,每块宝藏都标着"语音”。
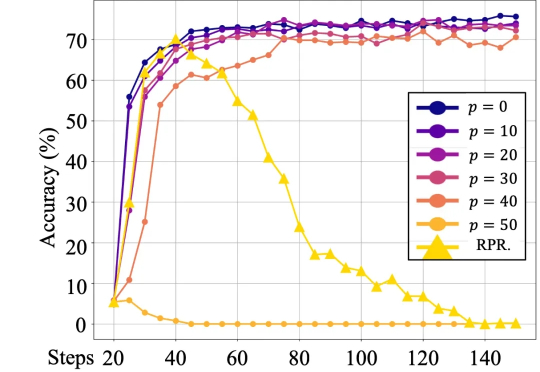
最近的一篇论文中,来自人大和腾讯的研究者们的研究表明,语言模型对强化学习中的奖励噪音具有鲁棒性,即使翻转相当一部分的奖励(例如,正确答案得 0 分,错误答案得 1 分),也不会显著影响下游任务的表现。
咱就是说啊,视觉基础模型这块儿,国产AI真就是上了个大分——Glint-MVT,来自格灵深瞳的最新成果。Glint-MVT,来自格灵深瞳的最新成果先来看下成绩——线性探测(LinearProbing):

OpenAI 最近发布了三份针对企业客户的研究报告,本次挑选了其中的「AI in the Enterprise」一篇进行了翻译。
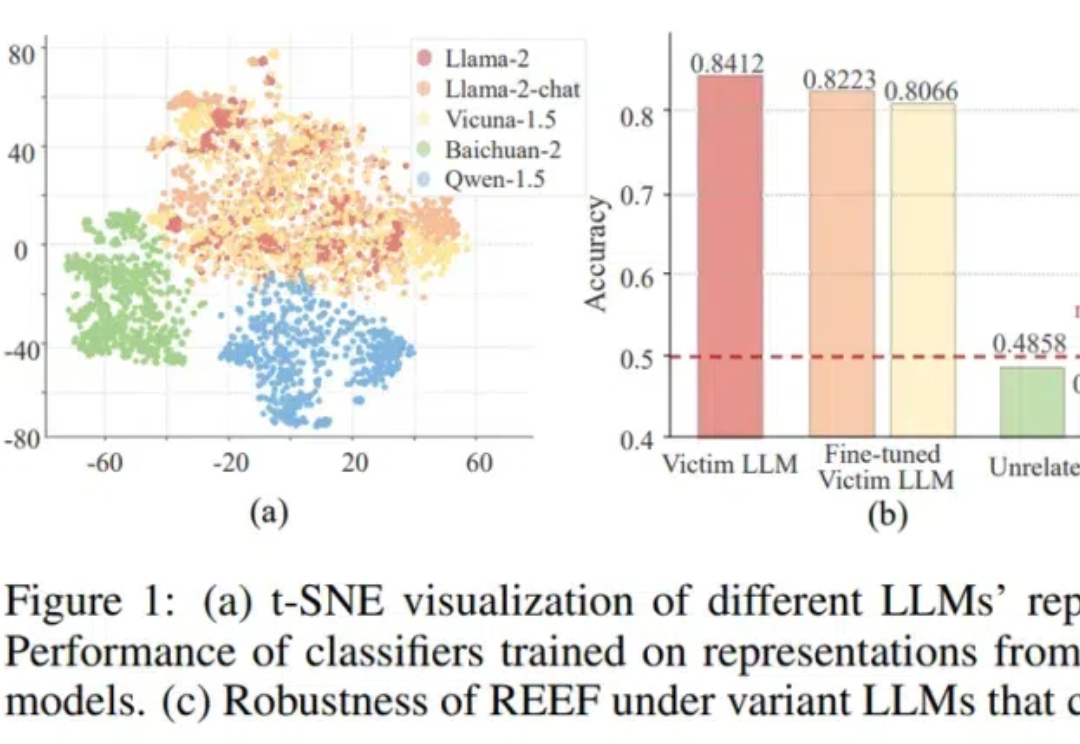
大模型“套壳”事件防不胜防,有没有方法可以检测套壳行为呢? 来自上海AI实验室、中科院、人大和上交大的学者们,提出了一种大模型的“指纹识别”方法——REEF(Representation Encoding Fingerprints)。
终于,Windows用户也可以用上ChatGPT了。就在刚刚,OpenAI推出了适用Windows系统的ChatGPT应用。不过,目前仅供ChatGPT Plus、Team、Enterprise和Edu用户使用。