
3D视觉被过度设计?字节Depth Anything 3来了,谢赛宁点赞
3D视觉被过度设计?字节Depth Anything 3来了,谢赛宁点赞机器之心报道 编辑:泽南、杨文 现在,只需要一个简单的、用深度光线表示训练的 Transformer 就行了。 这项研究证明了,如今大多数 3D 视觉研究都存在过度设计的问题。 本周五,AI 社区最热
来自主题: AI技术研报
8761 点击 2025-11-16 11:27
 搜索
搜索
机器之心报道 编辑:泽南、杨文 现在,只需要一个简单的、用深度光线表示训练的 Transformer 就行了。 这项研究证明了,如今大多数 3D 视觉研究都存在过度设计的问题。 本周五,AI 社区最热

Transformer的火种已燃烧七年。如今,推理模型(Reasoning Models)正点燃第二轮革命。Transformer共同作者、OpenAI研究员Łukasz Kaiser预判:未来一两年,AI会极速跃升——瓶颈不在算法,而在GPU与能源。

一篇入围顶会NeurIPS’25 Oral的论文,狠狠反击了一把DiT(Diffusion Transformer)。这篇来自字节跳动商业化技术团队的论文,则是提出了一个名叫InfinityStar的方法,一举兼得了视频生成的质量和效率,为视频生成方法探索更多可能的路径。
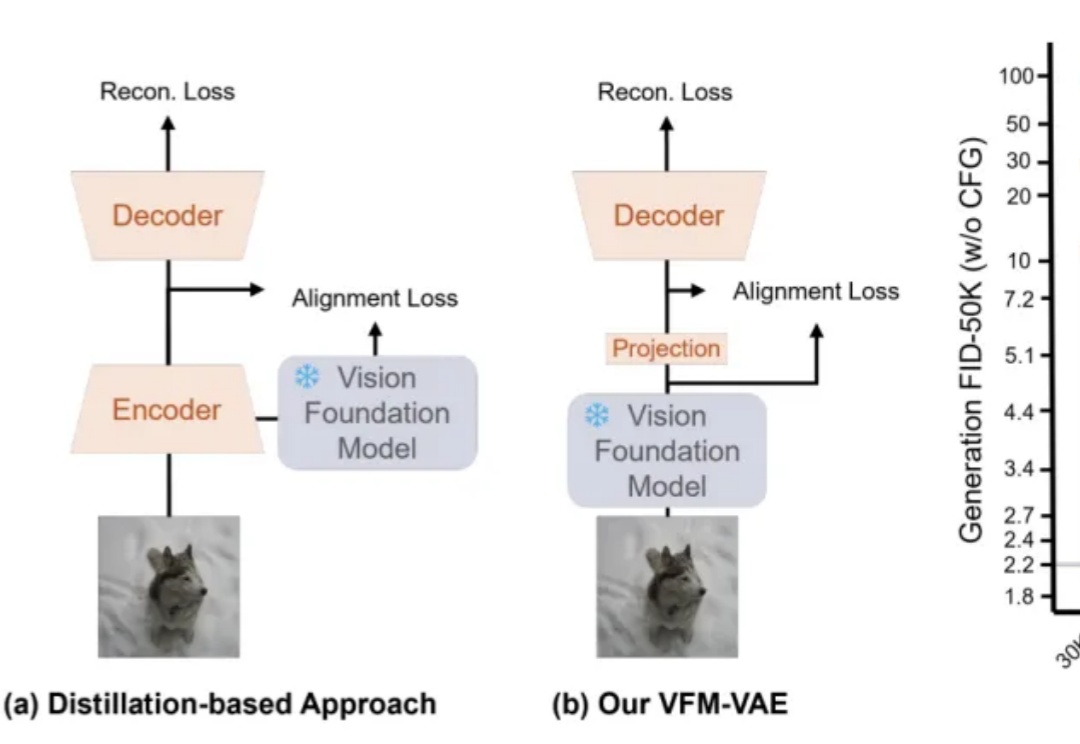
近期,RAE(Diffusion Transformers with Representation Autoencoders)提出以「 冻结的预训练视觉表征」直接作为潜空间,以显著提升扩散模型的生成性能。

谷歌花27亿美元(约192亿人民币)挖来的Transformer“贡献最大”作者Noam Shazzer,现在点燃了火药桶。

大模型「灾难性遗忘」问题或将迎来突破。近日,NeurIPS 2025收录了谷歌研究院的一篇论文,其中提出一种全新的「嵌套学习(Nested Learning)」架构。实验中基于该框架的「Hope」模型在语言建模与长上下文记忆任务中超越Transformer模型,这意味着大模型正迈向具备自我改进能力的新阶段。

微调超大参数模型,现在的“打开方式”已经大变样了: 仅需2-4 张消费级显卡(4090),就能在本地对DeepSeek 671B乃至Kimi K2 1TB这样的超大模型进行微调了。

谷歌世界模型大牛Danijar Hafner宣布离任!他自2016年起开始在Google Brain实习,后又在DeepMind、Brain Team工作。他的经历颇具传奇色彩,曾获辛顿指导,还与Łukasz Kaiser、Ashish Vaswani等Transformer大佬有过交集。

Transformer 语言模型具有单射性,隐藏状态可无损重构输入信息。
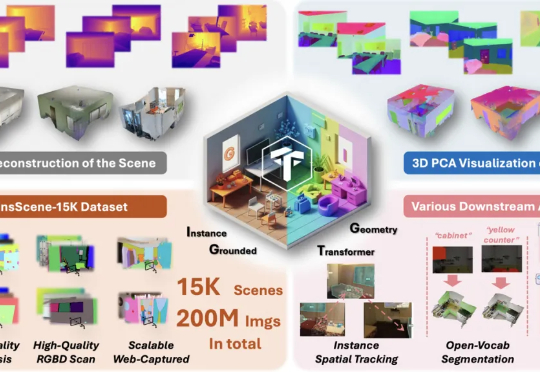
现在,NTU联合StepFun提出了IGGT (Instance-Grounded Geometry Transformer) ,一个创新的端到端大型统一Transformer,首次将空间重建与实例级上下文理解融为一体。