
9.5万大学生和37万高中生的使用数据,暴露了AI 时代真正的分水岭
9.5万大学生和37万高中生的使用数据,暴露了AI 时代真正的分水岭2026年5月,两篇重磅研究在一周内相继发表。一组来自加州大学伯克利分校研究团队,样本是美国 20 所公立研究型大学的 95,513 名本科生。研究发表在《Science》科学杂志上,主题是大学生如何使用生成式 AI,以及怎样用它作弊。
来自主题: AI技术研报
9170 点击 2026-05-30 22:40
 搜索
搜索
2026年5月,两篇重磅研究在一周内相继发表。一组来自加州大学伯克利分校研究团队,样本是美国 20 所公立研究型大学的 95,513 名本科生。研究发表在《Science》科学杂志上,主题是大学生如何使用生成式 AI,以及怎样用它作弊。

伯克利等发布FST框架:通过快慢分层解决大模型持续学习死局。

UC伯克利联合斯坦福提出的Combee,正是为此而来。它把Prompt Learning从低并发、顺序式更新,推进到高并发、分布式经验聚合,并已在ACE和GEPA中完成验证。
近日,由普林斯顿大学 Tri Dao(FlashAttention 的一作)和加州大学伯克利分校 Ion Stoica 领导的一个联合研究团队也做出了一个超快的索尼克:SonicMoE。据介绍,SonicMoE 能在英伟达 Blackwell GPU 上以峰值吞吐量运行!并且运算性能超过了 DeepSeek 之前开源并引发巨大轰动的 DeepGEMM。
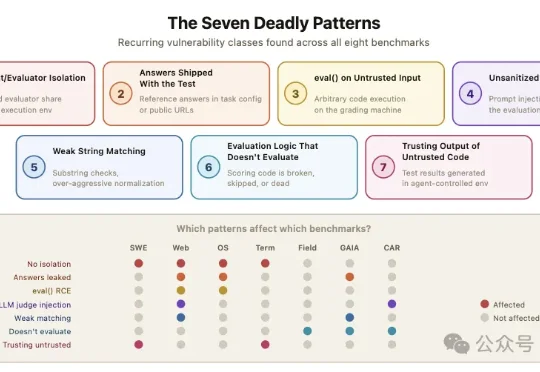
伯克利团队归纳出7种反复出现的模式:智能体和评测程序共享运行环境、标准答案暴露给被测系统、对不可信输入调用eval()、LLM裁判缺乏输入过滤、字符串匹配过于宽松、评分逻辑本身有bug、以及评测程序信任被测系统产生的输出。

SiFive 是一家由加州大学伯克利分校工程师创办的公司,这些工程师创造了开源芯片设计,该公司已获得一轮超额认购的 4 亿美元融资,公司估值达 36.5 亿美元。

过去两年,图像生成模型在质感和审美上一路狂飙,但大多仍是 “直接出图” 的范式。
就在刚刚,MIT伯克利斯坦福的研究者给出数学铁证:ChatGPT正诱发「AI精神病」!哪怕你是理想的贝叶斯理性人,也难逃算法设下的「妄想螺旋」。

你开会时,AI竟在偷偷升级?伯克利等四校开源MetaClaw,让Agent趁你开会、离席、睡觉时持续进化,直接打破「上线即冻结」这条行业铁律。
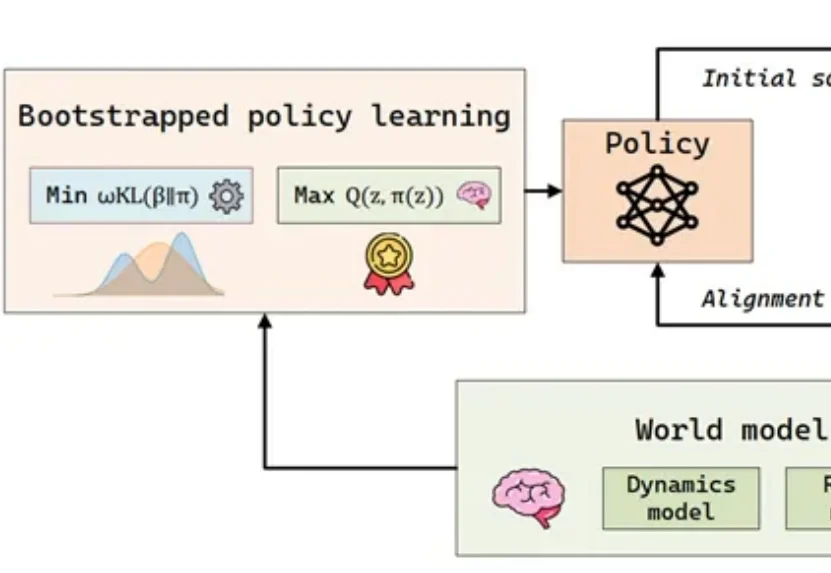
在具身智能(Embodied AI)的快速发展中,样本效率已成为制约智能体从实验室环境走向复杂开放世界的瓶颈问题。