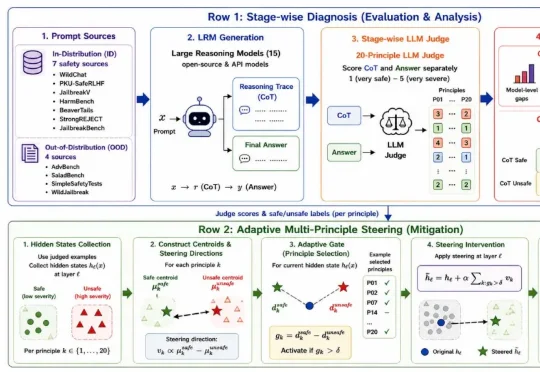
15个推理模型集体翻车,详解输出背后的思考链潜藏风险
15个推理模型集体翻车,详解输出背后的思考链潜藏风险哈佛大学、南加州大学、布朗大学、MIT 等多个机构的研究者联合做了一项系统性研究,给出了否定的答案,并举例到「当我们发现大模型的思考链可被用于生成炸弹装置或投毒配方等高风险内容时,便意识到这一问题非同小可」。
来自主题: AI技术研报
7925 点击 2026-07-07 10:21
 搜索
搜索
哈佛大学、南加州大学、布朗大学、MIT 等多个机构的研究者联合做了一项系统性研究,给出了否定的答案,并举例到「当我们发现大模型的思考链可被用于生成炸弹装置或投毒配方等高风险内容时,便意识到这一问题非同小可」。
Greg Isenberg 最近在他自己的播客 The Startup Ideas Podcast 里讲的一个判断,他说了一句很直白的话,building agents is the new SaaS,做 agent 就是新时代的 SaaS。

有人把 YC 2026 春季批次的 launch,一家不落地全看了一遍。196 家公司,395 个创始人,上周刚 Demo Day。95% 的公司沾 AI,70% 在做 agent。可它们的定位,没有一家是「我们用了 AI」。区别只在于,这句「换掉人」,被包装成了几种不同的话术。
近日,一家叫良配科技的公司拿到了今日资本200万美元的天使轮投资。放在2026年的融资市场里,这条新闻有点特别。很少有人会想到,被誉为风投女王的徐新,这次押注的场景,是相亲。更让人意外的是,做这件事的人来路并不在婚恋行业。

近日,通用世界模型领军企业生数科技完成新一轮5亿美金融资,创下国内通用世界模型领域最大单笔融资纪录,为企业技术研发与商业化落地注入强劲资本动能。本轮融资由阿里云领投,多家战略机构及老股东持续加码,巨头产业资本加持,凸显市场对其技术壁垒与商业化潜力的高度认可。

“Dario 见证的百度 AI 路线分歧。 ” 作者丨成妍菁 编辑丨胡敏 Anthropic 创始人 Dario 的职业开局有些戏剧化。 2014 年刚走出校园加入百度,就赶上中国互联网历史上第一场“

谷歌DeepMind的一个高管,用死对头Anthropic的AI,把一个2003年的游戏硬塞进了iPhone。这个人叫Ammaar Reshi,是AI Studio的产品与设计负责人。跑的是真实引擎,ARM64原生编译,不是模拟器。

从被排斥到占领好莱坞,字节Seedance你都做了什么??现在好莱坞已经是酱婶儿的了:比如这部95分钟长片《Hell Grind》(地狱磨坊),Higgisfield AI出品。还有这部AI奇幻剧集《骸骨编年史》,包含了6条独立故事线和众多角色:

7 月 3 日,学而思学习机正式进行 2026 旗舰新品发布,发布全新培优 AI 家教、「国际学院」全新英语学习体系及 T6 系列旗舰机型。所以,相比「又出了一台新学习机」,这场发布会更值得关注的是:当答案已经不再稀缺,学习机到底还能帮孩子做什么?
为了解决这一问题,来自 University of Arizona、Zoom 与 Stony Brook University 的研究团队推出了 VISTA(VIsual Spec-To-App Benchmark), 首个面向 Visual Spec-to-Web-App Coding Agents 的端到端 Benchmark。