ECCV 2026 | 实时导演多镜头长视频! 港中文&快手可灵发布ShotStream
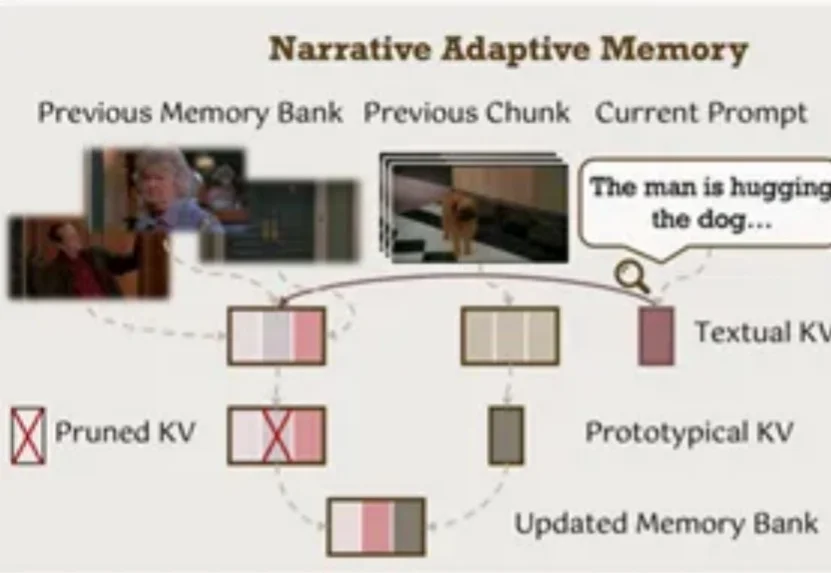
ECCV 2026 | 实时导演多镜头长视频! 港中文&快手可灵发布ShotStream为了打破多镜头长视频面临的高延迟、零交互困境,香港中文大学与快手可灵团队联合提出了首个实时流式多镜头长视频生成框架 ——ShotStream。该研究打破了传统双向架构的限制,将多镜头合成定义为基于历史上下文的下一镜头生成任务,用户可以通过动态流式提示词在运行时动态指导叙事走向!更令人振奋的是
来自主题: AI技术研报
6670 点击 2026-07-12 10:47