
姚顺雨领军,腾讯合并大语言模型和多模态团队
姚顺雨领军,腾讯合并大语言模型和多模态团队近日,腾讯宣布混元多模态模型部门与大语言模型部门合并,成立基础模型部,统一由腾讯首席AI科学家姚顺雨管理,以进一步提升模型研发和协同效率,探索全模态模型的智能上限。
来自主题: AI资讯
8956 点击 2026-07-24 22:57
 搜索
搜索
近日,腾讯宣布混元多模态模型部门与大语言模型部门合并,成立基础模型部,统一由腾讯首席AI科学家姚顺雨管理,以进一步提升模型研发和协同效率,探索全模态模型的智能上限。
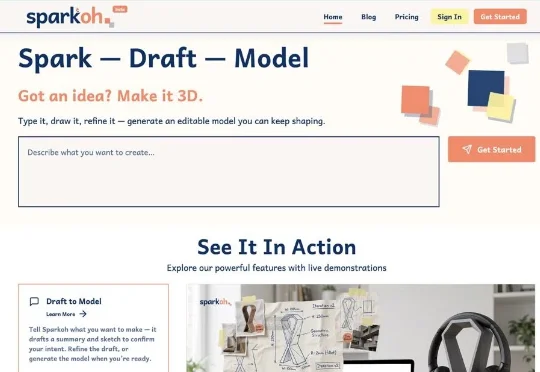
3D打印无疑是全球增长最受关注的赛道之一,但结构化、可编辑的物理3D数据却极度稀缺。就在这个行业真空里,一家年轻公司浮出水面——AI生成矢量3D模型的比特无限(BitInf)。
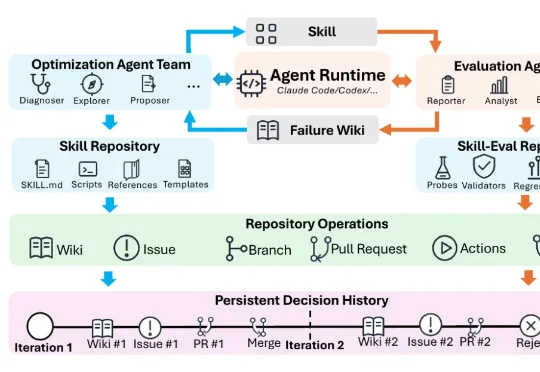
腾讯微信在论文 SkillHone 中,将这个问题归结为优化历史丢失,进而提出了面向持续 Skill 进化的开发框架。 SkillHone 把每轮诊断、候选修改、评估证据和最终决定组织成持久决策历史。同时,持续优化的对象也从单一的 SKILL.md 文件扩展到了整个 Skill 文件夹及其修改过程。
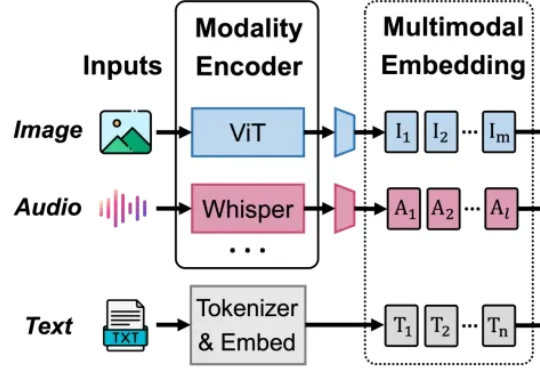
BigMac 是原生多模场景下的流水并行训练新范式。它针对多模态大模型训练中计算效率与显存占用难以兼顾的问题,提出了依赖安全的嵌套流水线:以成熟的 LLM 流水线为主干,在不打乱 LLM 执行顺序的前提下,有序嵌入编码器和生成器计算,从而在不增加 LLM 流水线空泡、保持激活显存有界的同时,高效实现多模态流水训练。

近日,来自清华大学等单位的研究团队提出了AutoMIA,一种自动生成镜像错觉艺术的 AI 设计方法,用户仅需任意指定两张图片,分别对应镜子前和镜子中的图案,AutoMIA就可以自动完成3维艺术品的设计,并且支持直接3D打印出来制作艺术品。
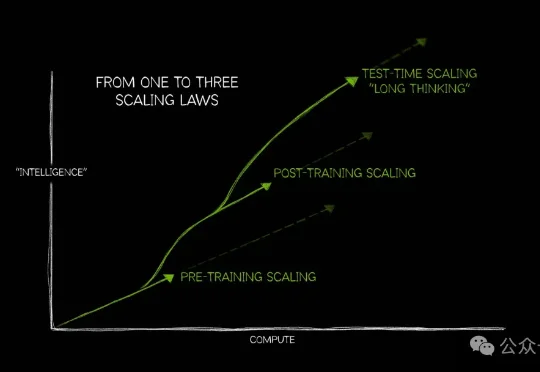
新智元报道 大模型变强,过去靠两条路。 做大——Scaling Law出现后,参数从百亿推向千亿,算力支出一路飙升。 想久——o1带火思考模型,用更长的思维链、更多推理时间换结果。 问题是,除了Sca
今天,据《华尔街日报》报道,美国金融科技公司Stripe正洽谈收购顶流大模型中转站OpenRouter。目前,交易的具体价格尚不清楚,但部分知情人士称,这笔交易估值可能达到约100亿美元(约合人民币677.55亿元)。

联想之星、银杏谷资本、啟赋资本等投了。
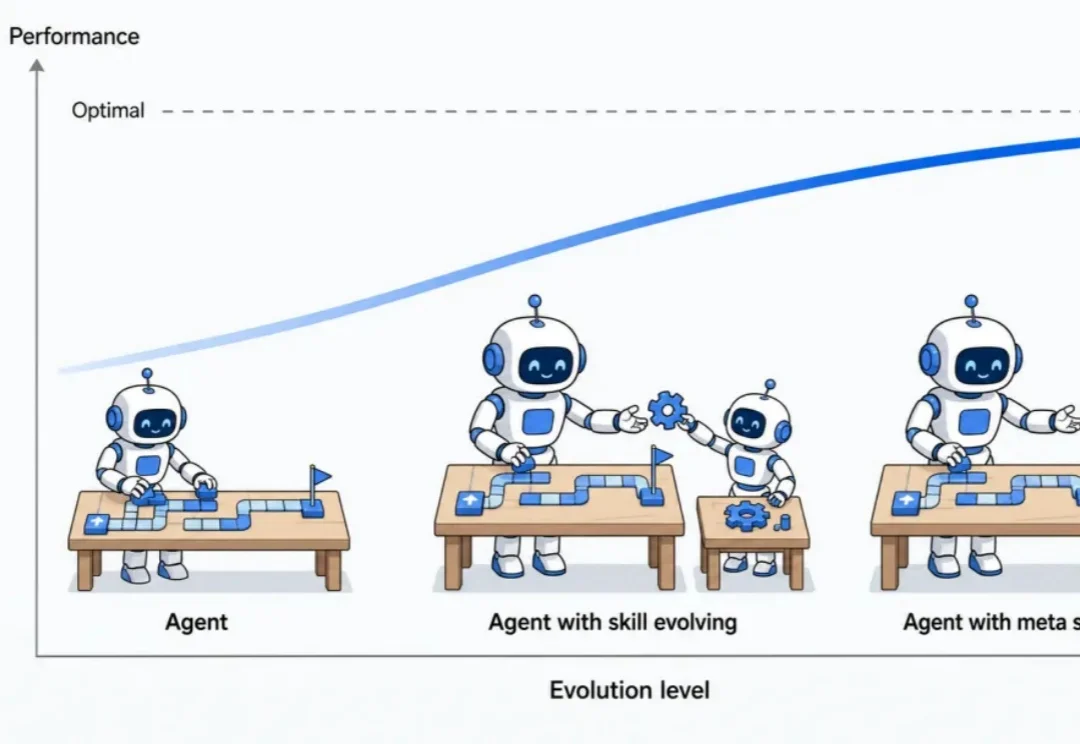
当大模型 Agent 被部署到工具调用、长程任务和开放环境中,一个关键问题会随之出现:能否在不更新模型参数的情况下,将执行经验沉淀下来,并在下一次做得更好?
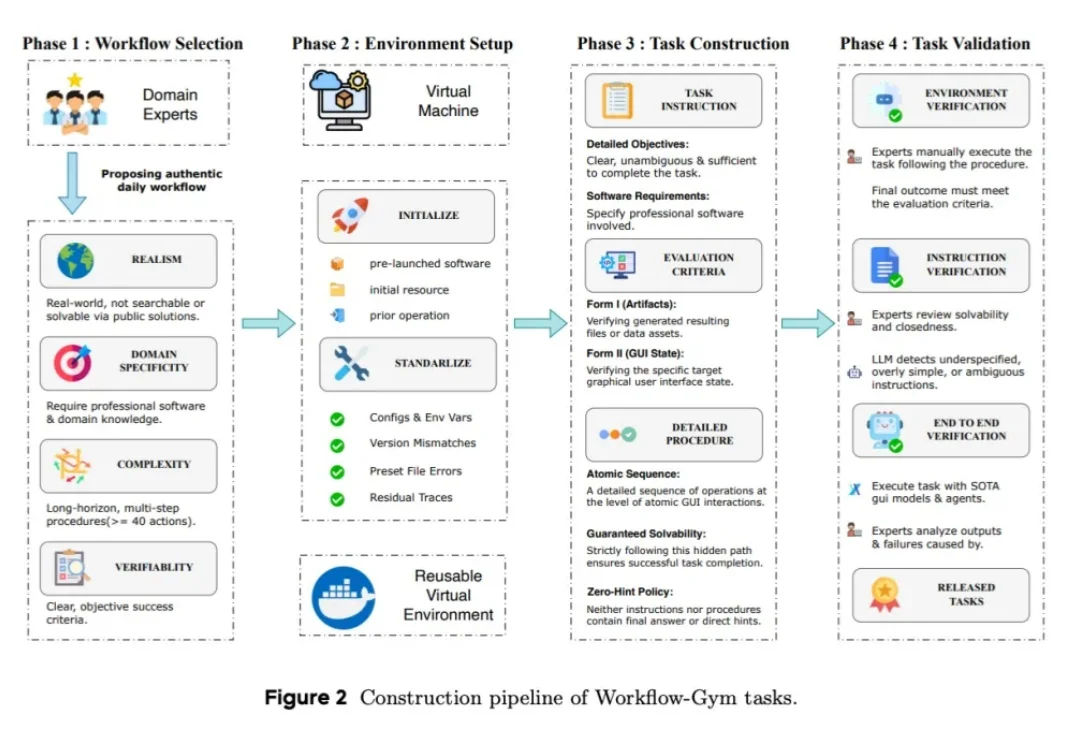
你可能已经在各种 benchmark 榜单上看过 GUI Agent 的 "大胜" 了。