
蔡浩宇更新领英,宣布成为独立大模型Agent开发者
蔡浩宇更新领英,宣布成为独立大模型Agent开发者近日,米哈游创始人蔡浩宇久违地更新了自己的个人领英,新增了一条独立大模型+智能体开发者(Independent LLM+Agent Developer)的职业经历,时间从2026年7月开始,在新加坡混合办公。
来自主题: AI资讯
9204 点击 2026-07-31 00:36
 搜索
搜索
近日,米哈游创始人蔡浩宇久违地更新了自己的个人领英,新增了一条独立大模型+智能体开发者(Independent LLM+Agent Developer)的职业经历,时间从2026年7月开始,在新加坡混合办公。

AI智件独家获悉,WoW模型一作、港科大博士池晓威于今年4月创业,成立了世界模型公司「莫刻机器人MUKA Robotics 」。工商资料显示,「莫刻机器人」成立于2026年4月,注册地在北京市海淀区,池晓威担任法人和实控人。

近日,一家公司员工爆料,其所在公司已与其他企业一道收到了美国政府指令,要求停止使用 Anthropic 旗下的产品、服务和模型。按照通知要求,公司将在 2026 年 8 月 31 日前完成全面清退,适用范围覆盖所有员工、承包商、应用程序、开发环境、云服务,以及代表公司开展工作的第三方。

7月几天之内,中国大模型行业接连出现了两个超过2万亿参数的模型。
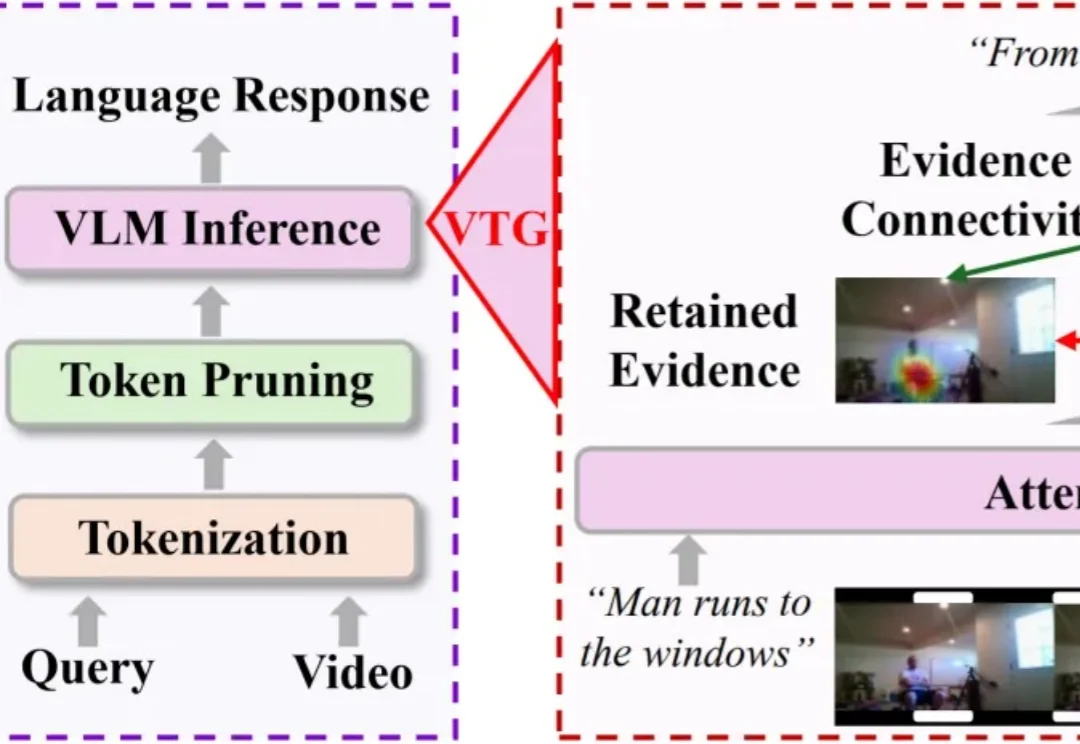
长视频理解,正在成为多模态大模型的重要能力。
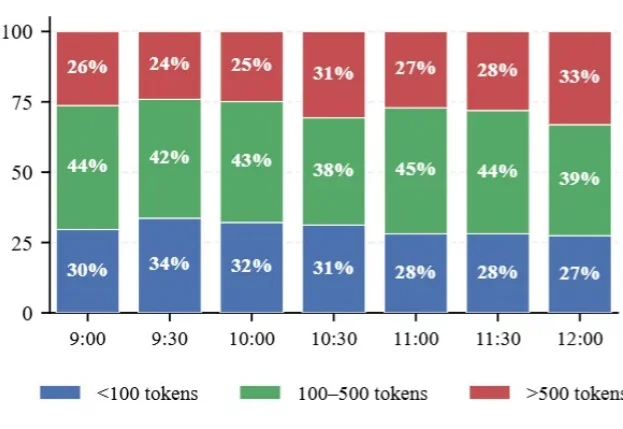
在刚刚落幕的2026 WAIC世界人工智能大会上,无问芯穹首次公布了其在大模型推理系统架构中的新突破——跨集群异构推理架构PDD。
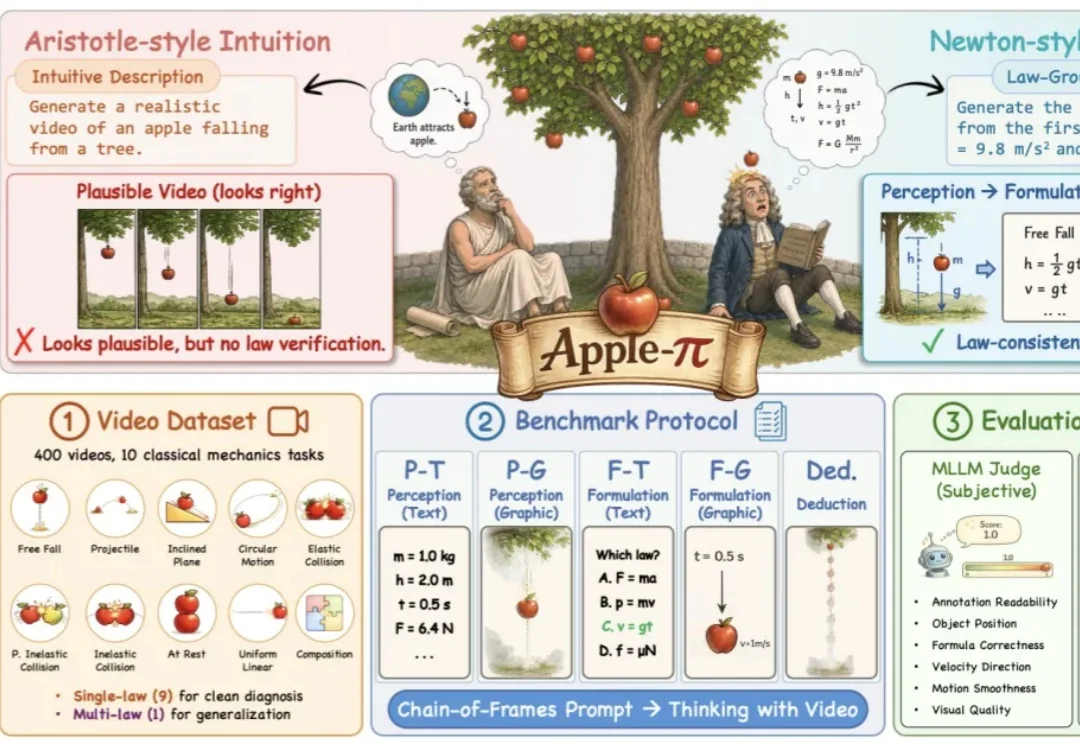
一个苹果从树上落下,今天的视频模型大多能生成一段「看起来正确」的运动:苹果向下、速度加快,最终落地。
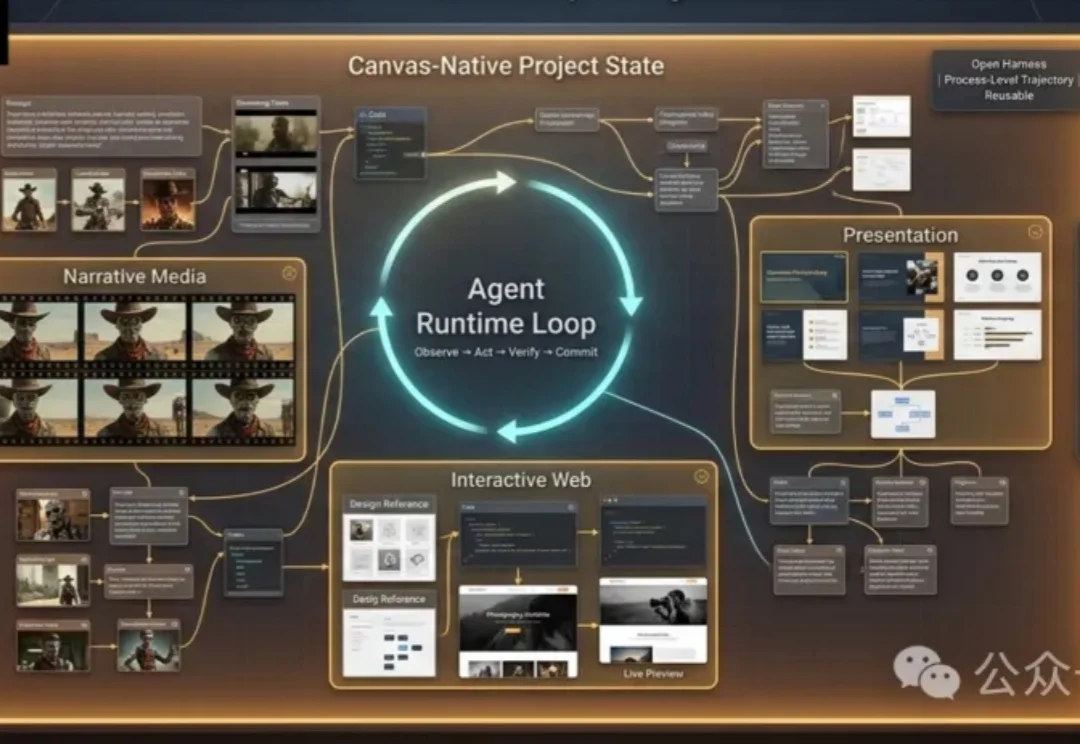
近几年,多模态生成模型进步很快。一句指令就能生成图片、视频、音频、网页、UI、分镜,甚至整套演示文稿。只看成品,创作门槛似乎已经大幅降低。

近期,SemiAnalysis 创始人 Dylan Patel 先后做客红杉资本的《Training Data[1]》和 WisdomTree 的《The Next Big Thing[2]》。两期访谈从模型和芯片,一路延伸至内存、能源、数据中心与 AI 商业模式,并指向同一个变化:AI 竞赛的焦点,正从单纯比较模型能力,扩展到谁能以更低成本、更大规模,把模型能力稳定地交付出来。
过去两年,多模态模型的竞争看起来像一场“造眼睛”的竞赛:更高的图像分辨率、更多的视觉 token、更大的模型,以及更昂贵的训练。行业似乎默认,只要第一次看得足够清楚,AI 就能从“看见”抵达“洞见”。